Which of the following sentences is TRUE about the definition of cloud models for machine learning pipelines?
A. Data as a Service (DaaS) can host the databases providing backups, clustering, and high availability.
B. Infrastructure as a Service (IaaS) can provide CPU, memory, disk, network and GPU.
C. Platform as a Service (PaaS) can provide some services within an application such as payment applications to create efficient results.
D. Software as a Service (SaaS) can provide AI practitioner data science services such as Jupyter notebooks.
Explanation: Cloud models are service models that provide different levels of abstraction
and control over computing resources in a cloud environment. Some of the common cloud
models for machine learning pipelines are:
Which of the following is a privacy-focused law that an AI practitioner should adhere to while designing and adapting an AI system that utilizes personal data?
A. General Data Protection Regulation (GDPR)
B. ISO/IEC 27001
C. PCIDSS
D. Sarbanes Oxley (SOX)
Explanation: The General Data Protection Regulation (GDPR) is a privacy-focused law that an AI practitioner should adhere to while designing and adapting an AI system that utilizes personal data. The GDPR applies to any organization that processes personal data of individuals in the European Union (EU), regardless of where the organization is located. The GDPR grants individuals rights over their personal data, such as the right to access, rectify, erase, restrict, or object to its processing. The GDPR also imposes obligations on organizations that process personal data, such as the duty to obtain consent, conduct data protection impact assessments, implement data protection by design and by default, and ensure accountability and transparency. The GDPR also addresses some specific issues related to AI, such as automated decision-making, profiling, and data portability.
Which of the following best describes distributed artificial intelligence?
A. It does not require hyperparemeter tuning because the distributed nature accounts for the bias.
B. It intelligently pre-distributes the weight of starting a neural network.
C. It relies on a distributed system that performs robust computations across a network of unreliable nodes.
D. It uses a centralized system to speak to decentralized nodes.
Explanation: Distributed artificial intelligence (DAI) is a subfield of artificial intelligence that studies how multiple intelligent agents can coordinate and cooperate to achieve a common goal or solve a complex problem. DAI relies on a distributed system that performs robust computations across a network of unreliable nodes, such as sensors, robots, or humans. DAI can handle large-scale, dynamic, and uncertain environments that are beyond the capabilities of a single agent.
When working with textual data and trying to classify text into different languages, which approach to representing features makes the most sense?
A. Bag of words model with TF-IDF
B. Bag of bigrams (2 letter pairs)
C. Word2Vec algorithm
D. Clustering similar words and representing words by group membership
Explanation: A bag of bigrams (2 letter pairs) is an approach to representing features for textual data that involves counting the frequency of each pair of adjacent letters in a text. For example, the word “hello” would be represented as {“he”: 1, “el”: 1, “ll”: 1, “lo”: 1}. A bag of bigrams can capture some information about the spelling and structure of words, which can be useful for identifying the language of a text. For example, some languages have more common bigrams than others, such as “th” in English or “ch” in German .
You and your team need to process large datasets of images as fast as possible for a machine learning task. The project will also use a modular framework with extensible code and an active developer community. Which of the following would BEST meet your needs?
A. Caffe
B. Keras
C. Microsoft Cognitive Services
D. TensorBoard
Explanation: Caffe is a deep learning framework that is designed for speed and modularity. It can process large datasets of images efficiently and supports various types of neural networks. It also has a large and active developer community that contributes to its code base and documentation. Caffe is suitable for image processing tasks such as classification, segmentation, detection, and recognition.
A classifier has been implemented to predict whether or not someone has a specific type of disease. Considering that only 1% of the population in the dataset has this disease, which measures will work the BEST to evaluate this model?
A. Mean squared error
B. Precision and accuracy
C. Precision and recall
D. Recall and explained variance
Explanation: Precision and recall are two measures that can evaluate the performance of a classifier, especially when the data is imbalanced. Precision is the ratio of true positives (correctly predicted positive cases) to all predicted positive cases. Recall is the ratio of true positives to all actual positive cases. Precision and recall can help assess how well the classifier can identify the positive cases (the disease) and avoid false negatives (missed diagnosis) or false positives (unnecessary treatment).
Below are three tables: Employees, Departments, and Directors.
Employee_Table
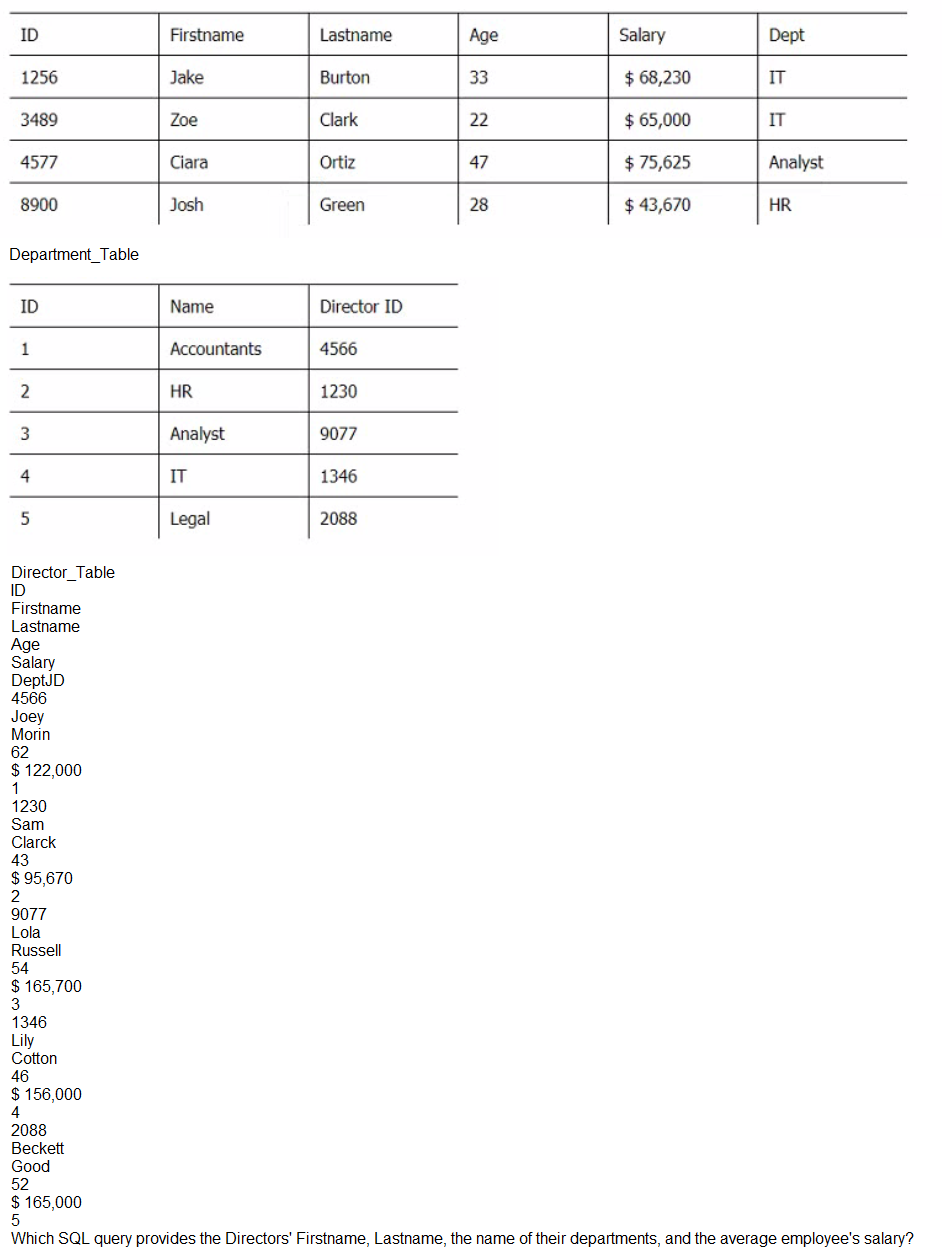
A. SELECT m.Firstname, m.Lastname, d.Name, AVG(e.Saiary) as Dept_avg_Saiary
FROM Employee_Table as e
LEFT JOIN Department_Table as d on e.Dept = d.Name
LEFT JOIN Directorjable as m on d.ID = m.DeptJD
GROUP BY m.Firstname, m.Lastname, d.Name
B. SELECT m.Firstname, m.Lastname, d.Name, AVG(e.Salary) as Dept_avg_Salary
FROM Employee_Table as e
RIGHT JOIN Departmentjable as d on e.Dept = d.Name
INNER JOIN Directorjable as m on d.ID = m.DeptJD
GROUP BY d.Name
C. SELECT m.Firstname, m.Lastname, d.Name, AVG(e.Salary) as Dept_avg_Salary
FROM Employee_Table as e
RIGHT JOIN Department_Table as d on e.Dept = d.Name
INNER JOIN Directorjable as m on d.ID = m.DeptJD
GROUP BY e.Salary
D. SELECT m.Firstname, m.Lastname, d.Name, AVG(e.Salary) as Dept_avg_Salary
FROM Employee_Table as e
RIGHT JOIN Department_Table as d on e.Dept = d.Name
INNER JOIN Directorjable as m on d.ID = m.DeptID
GROUP BY m.Firstname, m.Lastname, d.Name
Explanation: This SQL query provides the Directors’ Firstname, Lastname, the name of their departments, and the average employee’s salary by joining the three tables using the appropriate join types and conditions. The RIGHT JOIN between Employee_Table and Department_Table ensures that all departments are included in the result, even if they have no employees. The INNER JOIN between Department_Table and Directorjable ensures that only departments with directors are included in the result. The GROUP BY clause groups the result by the directors’ names and departments’ names, and calculates the average salary for each group using the AVG function.
Which of the following is the definition of accuracy?
A. (True Positives + False Positives) / Total Predictions
B. (True Positives + True Negatives) / Total Predictions
C. True Positives / (True Positives + False Negatives)
D. True Positives / (True Positives + False Positives)
Explanation: Accuracy is a measure of how well a classifier can correctly predict the class of an instance. Accuracy is calculated by dividing the number of correct predictions (true positives and true negatives) by the total number of predictions. True positives are instances that are correctly predicted as positive (belonging to the target class). True negatives are instances that are correctly predicted as negative (not belonging to the target class).
Which of the following methods can be used to rebalance a dataset using the rebalance design pattern?
A. Bagging
B. Boosting
C. Stacking
D. Weighted class
Explanation: Weighted class is a technique to rebalance a dataset by assigning different weights to each class, according to their frequency in the dataset. The weights are inversely proportional to the class frequency, meaning that rare classes have higher weights and common classes have lower weights. This helps to reduce the bias towards the majority class and improve the model performance on the minority class.
Which of the following occurs when a data segment is collected in such a way that some members of the intended statistical population are less likely to be included than others?
A. Algorithmic bias
B. Sampling bias
C. Stereotype bias
D. Systematic value distortion
Explanation: Sampling bias occurs when a data segment is collected in such a way that some members of the intended statistical population are less likely to be included than others. This can result in a sample that is not representative of the population and may lead to inaccurate or misleading conclusions. Sampling bias can be caused by various factors, such as non-random sampling methods, non-response, self-selection, or convenience sampling.
In a self-driving car company, ML engineers want to develop a model for dynamic pathing. Which of following approaches would be optimal for this task?
A. Dijkstra Algorithm
B. Reinforcement learning
C. Supervised Learning.
D. Unsupervised Learning
Explanation: Reinforcement learning is a type of machine learning that involves learning from trial and error based on rewards and penalties. Reinforcement learning can be used to develop models for dynamic pathing, which is the problem of finding an optimal path from one point to another in an uncertain and changing environment. Reinforcement learning can enable the model to adapt to new situations and learn from its own actions and feedback. For example, a self-driving car company can use reinforcement learning to train its model to navigate complex traffic scenarios and avoid collisions .
Which of the following is NOT an activation function?
A. Additive
B. Hyperbolic tangent
C. ReLU
D. Sigmoid
Explanation: An activation function is a function that determines the output of a neuron in
a neural network based on its input. An activation function can introduce non-linearity into a
neural network, which allows it to model complex and non-linear relationships between
inputs and outputs. Some of the common activation functions are:
| Page 1 out of 8 Pages |