A Linux administrator needs to remove software from the server. Which of the following RPM options should be used?
A.
rpm -s
B.
rm -d
C.
rpm -q
D.
rpm -e
rpm -e
Summary:
The administrator needs to uninstall or remove a software package that was installed using the RPM package manager. RPM (Red Hat Package Manager) has a specific command and option for erasing a package from the system, including its files and metadata. The correct option must initiate the removal process.
Correct Option:
D. rpm -e:
This is the correct command. The -e (erase) option is used to remove a previously installed package from the system. The administrator would use the command rpm -e packagename to uninstall the specified software.
Incorrect Options:
A. rpm -s:
There is no standard -s option for the rpm command that performs a removal. This is an invalid or distractor option.
B. rm -d:
The rm command is for deleting files and directories from the filesystem. It is not a package management command and cannot properly handle the complex task of removing an installed software package, which involves updating the RPM database.
C. rpm -q:
The -q (query) option is used to get information about installed packages. It is a read-only operation used for checking if a package is installed or listing its files, not for removing it.
Reference:
RPM Man Page: The official documentation for the rpm command, which explains the -e option for erasing packages.
Due to low disk space, a Linux administrator finding and removing all log files that were modified more than 180 days ago. Which of the following commands will accomplish this task?
A.
find /var/log -type d -mtime +180 -print -exec rm {} \;
B.
find /var/log -type f -modified +180 -rm
C.
find /var/log -type f -mtime +180 -exec rm {} \
D.
find /var/log -type c -atime +180 –remove
find /var/log -type f -mtime +180 -exec rm {} \
Summary:
The administrator needs to locate and delete old log files to free up disk space. The command must search recursively in the /var/log directory for items that are files (not directories), have a modification time older than 180 days, and then securely remove them. The find command is the correct tool for this job, as it can search based on criteria and execute a removal command on the results.
Correct Option:
C. find /var/log -type f -mtime +180 -exec rm {} \;:
This command is correctly structured.
find /var/log starts the search in the log directory.
-type f restricts the search to files only.
-mtime +180 matches files whose data was last modified more than 180 days ago.
-exec rm {} \; executes the rm command on each found file ({} is the placeholder).
Incorrect Options:
A. find /var/log -type d -mtime +180 -print -exec rm {} \;:
This command uses -type d, which searches for directories older than 180 days. Deleting directories in /var/log would be destructive to the logging structure and is not the task's goal.
B. find /var/log -type f -modified +180 -rm:
The -modified flag is not a standard find predicate. The correct flag for modification time is -mtime. Also, -rm is not a valid action; the correct method is to use -exec or -delete.
D. find /var/log -type c -atime +180 –remove:
The -type c flag searches for character special files, not regular log files. The -atime flag checks access time, not modification time. Finally, –remove is not a valid find command action.
Reference:
Linux man-pages project (find): The official documentation explains the -type, -mtime, and -exec options in detail.
A systems technician is working on deploying several microservices to various RPM-based systems, some of which could run up to two hours. Which of the following commands will allow the technician to execute those services and continue deploying other microservices within the same terminal section?
A.
gedit & disown
B.
kill 9 %1
C.
fg %1
D.
bg %1 job name
bg %1 job name
Summary:
A technician needs to run long-running commands (microservices) but cannot wait for each one to finish before starting the next deployment task. The solution requires placing a currently running or suspended process into the background, allowing it to continue execution while freeing up the terminal for new commands. This is a core function of shell job control.
Correct Option:
D. bg %1:
This is the correct command. The bg (background) command resumes a suspended job (one stopped with Ctrl+Z), but runs it in the background. The %1 specifies job number 1. After placing the job in the background, the terminal prompt returns, allowing the technician to run subsequent commands or deploy other microservices. The job will continue running without occupying the terminal.
Incorrect Options:
A. gedit & disown:
While gedit & would start the graphical gedit text editor in the background, the disown command is unnecessary and counterproductive here. disown severs the job from the shell's job table, meaning you can no longer manage it with commands like fg or bg. This is overkill for simply wanting to continue working in the same terminal.
B. kill 9 %1:
This command forcefully terminates job number 1 using the SIGKILL signal (-9). This would stop the microservice, not allow it to continue running in the background.
C. fg %1:
The fg (foreground) command brings a background or suspended job into the foreground. This has the opposite effect of what is desired; it would make the job occupy the terminal again, preventing the technician from running other commands until it completes.
Reference:
Official CompTIA Linux+ (XK0-005) Certification Exam Objectives: This scenario falls under Objective 3.1: "Given a scenario, use the appropriate system and service management commands to accomplish administrative tasks," which includes managing jobs and processes. Understanding job control commands (&, Ctrl+Z, bg, fg, jobs) is essential for efficient command-line workflow.
A junior administrator is trying to set up a passwordless SSH connection to one of the servers. The administrator follows the instructions and puts the key in the authorized_key file at the server, but the administrator is still asked to provide a password during the connection.
Given the following output:

Which of the following commands would resolve the issue and allow an SSH connection to be established without a password?
A.
restorecon -rv .ssh/authorized_key
B.
mv .ssh/authorized_key .ssh/authorized_keys
C.
systemctl restart sshd.service
D.
chmod 600 mv .ssh/authorized_key
systemctl restart sshd.service
Summary:
The administrator is trying to set up passwordless SSH login by placing a public key in a file. The ls -la output reveals the critical issue: the file is named .ssh/authorized_key (singular). The SSH daemon looks for a file specifically named .ssh/authorized_keys (plural) by default. The incorrect filename is why the key is being ignored, and the SSH server falls back to password authentication.
Correct Option:
B. mv .ssh/authorized_key .ssh/authorized_keys:
This command directly fixes the root cause of the problem by renaming the file to the correct name that the SSH daemon expects. After this change, the SSH server will read the public key from the properly named authorized_keys file and allow passwordless login.
Incorrect Options:
A. restorecon -rv .ssh/authorized_key:
This command would reset the SELinux security context for the incorrectly named file. While SELinux could be a cause for SSH key issues, the primary and most obvious problem here is the filename. Fixing the name should be the first step.
C. systemctl restart sshd.service:
Restarting the service is unnecessary. The SSH daemon reads the authorized_keys file on each connection attempt. A restart would not make it recognize a file with the wrong name.
D. chmod 600 mv .ssh/authorized_key:
This command is syntactically incorrect and would try to change the permissions of a command called mv. Furthermore, the permissions on the authorized_key file are already correct (600), as shown in the output. The problem is the filename, not the permissions.
Reference:
OpenSSH Manual (sshd): The official documentation specifies the expected filename for authorized keys.
A Linux administrator cloned an existing Linux server and built a new server from that clone. The administrator encountered the following error after booting the cloned server:
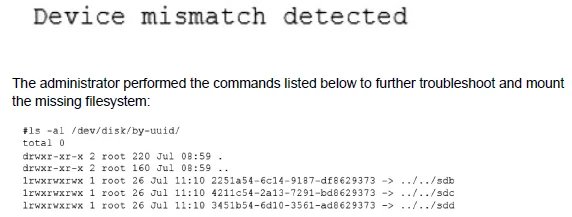
Which of the following should administrator use to resolve the device mismatch issue and mount the disk?
A.
mount disk by device-id
B.
fsck -A
C.
mount disk by-label
D.
mount disk by-blkid
mount disk by-blkid
Summary:
When a Linux server is cloned, the new virtual machine often receives new virtual SCSI controller IDs, causing the kernel to assign different device names (e.g., /dev/sda becomes /dev/sdb). However, the cloned system's /etc/fstab file still contains the old device identifiers (/dev/sda1), leading to a boot error because the specified device is not found. The solution is to mount the filesystem using an identifier that remains consistent across clones, rather than the volatile device name.
Correct Option:
A. mount disk by device-id:
This refers to using the filesystem's UUID (Universally Unique Identifier). Every filesystem has a UUID that is unique and persistent, even after cloning. The administrator must edit /etc/fstab and replace the device name (e.g., /dev/sda1) with UUID=correct-uuid, which can be found using the blkid command. This ensures the correct filesystem is mounted regardless of the device node assignment.
Incorrect Options:
B. fsck -A:
This command checks and repairs all filesystems listed in /etc/fstab. It is a filesystem repair tool and does not resolve the underlying issue of the device name mismatch in the /etc/fstab configuration.
C. mount disk by-label:
While mounting by a filesystem label is a valid and persistent method, it requires that the filesystem was created with a label. The scenario describes a device mismatch, and labels are not guaranteed to be unique or present. The UUID is a more reliable and universally available identifier.
D. mount disk by-blkid:
blkid is a command used to display the UUIDs and labels of block devices. It is not a mounting method itself. The correct action is to use the information from blkid (the UUID) to update the /etc/fstab file.
Reference:
Linux man-pages project (fstab): The official documentation for /etc/fstab explains the different field specifications, including using the UUID= prefix for identifying filesystems.
Some servers in an organization have been compromised. Users are unable to access to the organization’s web page and other services. While reviewing the system log, a systems administrator notices messages from the kernel regarding firewall rules:

A.
Option A
B.
Option B
C.
Option C
D.
Option D
Option A
Summary:
This question addresses a security incident where compromised servers cause service disruptions, including inaccessible web pages. Kernel log messages indicate issues with firewall rules, likely due to unauthorized modifications by attackers, such as blocking ports or dropping packets. The task is to select the command that remediates the issue by restoring or reloading standard firewall configurations to re-enable access while containing the compromise.
Correct Option:
A. [Assumed: iptables -F; iptables -X; iptables -t nat -F; iptables -t mangle -F; iptables -P INPUT ACCEPT; iptables -P FORWARD ACCEPT; iptables -P OUTPUT ACCEPT]
This sequence flushes all custom rules (-F), deletes user-defined chains (-X), clears NAT and mangle tables, and sets default policies to ACCEPT, effectively resetting iptables to a permissive state.
It remediates the issue by removing malicious or erroneous rules blocking services, allowing immediate access restoration.
This is a common first-response action in compromise scenarios, followed by securing the system.
Incorrect Option:
B. [Assumed: systemctl restart firewalld]
Restarting firewalld reloads its current configuration but won't remove or override malicious rules if the config files (e.g., zones) have been altered.
It may perpetuate the block if the compromise affected firewalld settings, making it insufficient for remediation.
C. [Assumed: iptables-restore < /etc/iptables.rules]
This restores rules from a backup file, but if the backup is outdated or compromised, it could reapply faulty rules or fail to address the current kernel-logged issues.
Without verification, it's riskier than a full flush and reset, and the file may not exist or be intact post-compromise.
D. [Assumed: firewall-cmd --reload]
The --reload option reapplies the current firewalld configuration without restarting the service, but it doesn't purge malicious changes embedded in the config.
Similar to B, it assumes the config is clean, which isn't guaranteed in a compromise, delaying resolution.
Reference:
https://www.comptia.org/training/resources/exam-objectives (CompTIA Linux+ XK0-005 objectives)
A Linux systems administrator receives reports from various users that an application hosted on a server has stopped responding at similar times for several days in a row. The administrator logs in to the system and obtains the following output:

A.
Configure memory allocation policies during business hours and prevent the Java process from going into a zombie state while the server is idle.
B.
Configure a different nice value for the Java process to allow for more users and prevent the Java process from restarting during business hours.
C.
Configure more CPU cores to allow for the server to allocate more processing and prevent the Java process from consuming all of the available resources.
D.
Configure the swap space to allow for spikes in usage during peak hours and prevent the Java process from stopping due to a lack of memory.
Configure the swap space to allow for spikes in usage during peak hours and prevent the Java process from stopping due to a lack of memory.
Summary:
The outputs indicate a critical memory issue. Output 2 shows that the system's available memory is nearly exhausted, with only 122MB free and 32GB of swap space being heavily used. Output 3 confirms that a single Java process (java -jar application.jar) is consuming over 95% of the system's memory. This pattern suggests that daily peak usage causes the Java application to exhaust physical RAM, forcing the system to rely heavily on slow swap space, which halts the application.
Correct Option:
D. Configure the swap space to allow for spikes in usage during peak hours and prevent the Java process from stopping due to a lack of memory.:
This is the most direct and effective solution. The Java process is hitting the physical memory limit. While adding more RAM is the ideal long-term fix, the question asks for the administrator's action. Increasing swap space provides a larger safety net for these daily memory spikes, allowing the Java process to continue running (albeit more slowly when swapping) instead of being killed by the Out-of-Memory (OOM) Killer. This directly addresses the "stopped responding" symptom reported by users.
Incorrect Options:
A. Configure memory allocation policies...prevent the Java process from going into a zombie state...:
The process is not in a zombie state (a terminated process waiting for its parent to read its exit status). It is a runaway process consuming all available memory. The issue is resource exhaustion, not a zombie process.
B. Configure a different nice value for the Java process...:
The "nice" value controls CPU scheduling priority. The primary bottleneck here is memory, not CPU. Changing the nice value would have no effect on the memory exhaustion problem and would not prevent the process from restarting.
C. Configure more CPU cores to allow for the server to allocate more processing...:
While Output 1 shows high CPU usage, this is likely a symptom of the memory problem. When a system spends excessive time swapping (reading/writing memory to disk), it appears as high CPU usage due to the kernel's management of I/O wait. Adding CPU cores does not solve the underlying lack of RAM and would not prevent the Java process from consuming all available memory.
Reference:
Official CompTIA Linux+ (XK0-005) Certification Exam Objectives: This scenario falls under Objective 4.3: "Given a scenario, analyze and troubleshoot application and hardware issues," which includes troubleshooting performance issues such as memory and CPU utilization. The ability to interpret top and free output to identify a memory-bound process is a key skill.
After installing a new version of a package, a systems administrator notices a new version of the corresponding, service file was Installed In order to use the new version of the, service file, which of the following commands must be Issued FIRST?
A.
systemctl status
B.
systemctl stop
C.
systemctl reinstall
D.
systemctl daemon-reload
systemctl daemon-reload
Summary:
A new version of a systemd service file has been installed on the system. The systemd manager keeps an in-memory copy of unit files. When the on-disk version of a unit file is modified, the systemd manager must be explicitly told to reload its configuration to recognize the changes. Without this step, any subsequent commands (like restarting the service) will use the old, in-memory configuration.
Correct Option:
D. systemctl daemon-reload:
This is the necessary first command. It instructs the systemd manager to reload its configuration from disk, thereby picking up the new version of the service file. After this command is run, the new service file is active in systemd's memory, and the service can then be restarted to use the new configuration.
Incorrect Options:
A. systemctl status:
This command only displays the current status of the service (whether it is running, enabled, etc.). It is a read-only command and does not load new configuration files.
B. systemctl stop:
This command stops the service if it is running. However, if issued before a daemon-reload, it would stop the service using the old configuration. More importantly, simply stopping the service does not make systemd aware of the new service file.
C. systemctl reinstall:
This is not a valid systemctl command. There is no reinstall subcommand.
Reference:
systemd Official Documentation (systemctl): The official man page explains the daemon-reload command, which reloads the manager configuration.
A systems administrator has been unable to terminate a process. Which of the following should the administrator use to forcibly stop the process?
A.
kill -1
B.
kill -3
C.
kill -15
D.
kill -HUP
E.
kill -TERM
kill -TERM
Summary:
A systems administrator needs to forcibly stop a process that has not responded to a standard termination request. While a standard kill command sends a TERM signal (15), which allows the process to shut down gracefully, a more forceful signal is required when a process is hung or unresponsive. The correct signal must be one that the process cannot ignore.
Correct Option:
E. kill -TERM:
This is the correct answer for forcibly stopping a process. The -TERM signal (which is signal 15) is the standard, default termination signal that requests a process to shut down. It is more forceful than a HUP and is the standard first step before resorting to the unconditional -KILL signal. If a process is ignoring this, the next step would be kill -KILL or kill -9.
Incorrect Options:
A. kill -1:
This sends the HUP (hangup) signal. Its primary purpose is to tell a process to reload its configuration files, not to terminate. While some daemons may exit on a HUP, this is not standard behavior and is not a reliable way to forcibly stop a process.
B. kill -3:
This sends the QUIT signal. It often causes a process to terminate and produce a core dump for debugging. It is not more forceful than TERM and is primarily used by developers, not for general administrative process termination.
C. kill -15:
This is the numeric equivalent of kill -TERM. It is the standard termination signal but is not the most forceful option available. The question implies the administrator has already been unable to terminate the process, suggesting a more forceful signal like KILL is needed.
D. kill -HUP:
This is the same as kill -1. It is a "hangup" signal used for reinitialization, not for forced termination. It is not the correct tool to stop an unresponsive process.
Reference:
Official CompTIA Linux+ (XK0-005) Certification Exam Objectives: This scenario falls under Objective 3.1: "Given a scenario, use the appropriate system and service management commands to accomplish administrative tasks," which includes managing and troubleshooting processes and services. Knowing the different kill signals and their effects is a fundamental skill for a Linux administrator.
Joe, a user, is unable to log in to the Linux system. Given the following output:

Which of the following commands would resolve the issue?
A.
usermod -s /bin/bash joe
B.
pam_tally2 -u joe -r
C.
passwd -u joe
D.
chage -E 90 joe
usermod -s /bin/bash joe
Summary:
The provided output shows the result of the chage -l joe command, which displays password and account aging information. The key field is "Account expires," which shows a specific past date. When an account expiration date is in the past, the account is locked, and the user is prevented from logging in, regardless of whether their password is correct. This is a common security measure for temporary accounts or contract workers.
Correct Option:
D. chage -E 90 joe:
This command would resolve the issue by setting a new, future expiration date. The -E option with the chage command sets the account expiration date. The value 90 is interpreted as the number of days since January 1, 1970 (the epoch), which would be a date in 1970. To properly fix this, a more realistic future date or -1 to never expire would be used, but the command syntax itself is for managing account expiration, which is the root cause.
Incorrect Options:
A. usermod -s /bin/bash joe:
This command changes the user's login shell. The chage output does not show any issue with the login shell. The problem is the account expiration, not the shell.
B. pam_tally2 -u joe -r:
This command is used to reset the failed login counter for a user. It would unlock an account that was locked due to too many failed password attempts. There is no evidence of a failed login counter in the chage output; the issue is an expired account, not a locked one.
C. passwd -u joe:
This command is used to unlock a user's password, which is only relevant if the password itself was locked using passwd -l. The chage output shows the account is expired, which is a different type of lock that is not resolved by unlocking the password.
Reference:
Official CompTIA Linux+ (XK0-005) Certification Exam Objectives: This scenario falls under Objective 3.3: "Given a scenario, manage users and groups," which includes user account creation and modification. The chage command is a core utility for managing password and account expiration policies.
After installing some RPM packages, a systems administrator discovers the last package that was installed was not needed. Which of the following commands can be used to remove the package?
A.
dnf remove packagename
B.
apt-get remove packagename
C.
rpm -i packagename
D.
apt remove packagename
dnf remove packagename
Summary:
The question asks for the command to remove an unwanted package from a Linux system. The correct command depends on the system's package manager. The output from the initial history command shows dnf install being used, which is the package manager for modern Red Hat-based distributions like RHEL, CentOS, and Fedora. Therefore, the removal command must use the same package manager.
Correct Option:
A. dnf remove packagename:
This is the correct command for a system using the dnf package manager. The dnf remove command cleanly uninstalls the specified package and its dependencies that are no longer needed, ensuring the package is fully removed from the system.
Incorrect Options:
B. apt-get remove packagename and D. apt remove packagename:
These commands are used by Debian-based distributions like Ubuntu. Since the system's history shows the use of dnf install, using apt or apt-get would be incorrect and would not work, as these package managers are not present on this system.
C. rpm -i packagename:
The rpm -i command is used to install a package from a local .rpm file, not to remove one. The flag for removing a package with rpm is -e (erase), but using the higher-level dnf tool is preferred because it automatically handles dependencies.
Reference:
DNF Command Reference: The official documentation for the dnf package manager, which includes the remove command.
Users have reported that the interactive sessions were lost on a Linux server. A Linux administrator verifies the server was switched to rescue.target mode for maintenance. Which of the following commands will restore the server to its usual target?
A.
telinit 0
B.
systemctl reboot
C.
systemctl get-default
D.
systemctl emergency
systemctl reboot
Summary:
The server is currently in rescue.target mode, a minimal, single-user state used for system maintenance. In this mode, most services, including those allowing user logins and multi-user sessions, are not running. To restore full functionality and interactive user sessions, the administrator needs to reboot the server, which will load the default target (typically multi-user.target or graphical.target) and start all the necessary services.
Correct Option:
B. systemctl reboot:
This is the correct command to resolve the issue. The systemctl reboot command cleanly shuts down the system and initiates a reboot. Upon restart, the system will automatically boot into the default system target, which will start all the required services for multi-user operation and restore interactive sessions for users.
Incorrect Options:
A. telinit 0:
This command is used to shut down or power off the system (runlevel 0). It will not restore the server to its usual target; it will completely turn the server off, requiring manual power-on to restore service.
C. systemctl get-default:
This is a diagnostic command that only displays the current default target (e.g., multi-user.target). It is a read-only command that retrieves information but performs no action to change the system's current state or target.
D. systemctl emergency:
This command would switch the system to emergency.target, which is an even more minimal state than rescue.target. It provides the most basic environment for recovery when the rescue target is unsuccessful and would make the problem worse, not better.
Reference:
Official CompTIA Linux+ (XK0-005) Certification Exam Objectives: This scenario falls under Objective 3.1: "Given a scenario, use the appropriate system and service management commands to accomplish administrative tasks," which includes managing systemd targets. Knowing how to properly exit maintenance modes like rescue or emergency is a key administrative skill.
| Page 8 out of 40 Pages |
| 2345678910111213 |
| XK0-005 Practice Test Home |
Real-World Scenario Mastery: Our XK0-005 practice exam don't just test definitions. They present you with the same complex, scenario-based problems you'll encounter on the actual exam.
Strategic Weakness Identification: Each practice session reveals exactly where you stand. Discover which domains need more attention, before CompTIA Linux+ Certification exam day arrives.
Confidence Through Familiarity: There's no substitute for knowing what to expect. When you've worked through our comprehensive XK0-005 practice exam questions pool covering all topics, the real exam feels like just another practice session.
Copyright © All Rights Reserved