A junior Linux administrator is tasked with installing an application. The installation guide states the application should only be installed in a run level 5 environment.

Which of the following commands would ensure the server is set to runlevel 5?
A.
systemctl isolate multi-user.target
B.
systemctl isolate graphical.target
C.
systemctl isolate network.target
D.
systemctl isolate basic.target
systemctl isolate graphical.target
Summary:
The task requires setting the server to runlevel 5. In modern Linux systems that use systemd, the concept of runlevels is mapped to specific "targets." Runlevel 5 is the multi-user system with a graphical user interface (GUI), which corresponds to the graphical.target in systemd. The correct command must switch the system to this target.
Correct Option:
B. systemctl isolate graphical.target:
This is the correct command. The systemctl isolate command is used to start a specific target and stop all others. Since graphical.target is the systemd equivalent of the traditional runlevel 5, this command will ensure the server is in the required environment for the application installation.
Incorrect Options:
A. systemctl isolate multi-user.target:
This corresponds to runlevel 3 (multi-user, text-based interface without a GUI). This is not the runlevel 5 environment specified in the installation guide.
C. systemctl isolate network.target:
This is a basic target that is pulled in as a dependency for network functionality. It is not a system state (runlevel) and does not provide a full user environment for installing applications.
D. systemctl isolate basic.target:
This is a minimal target that serves as a foundation for other targets. It is not a complete system state and is equivalent to runlevel 1 (single-user mode), not runlevel 5.
Reference:
systemd Official Documentation (systemd.special): The official man page describes the various special targets, including graphical.target and multi-user.target, and their purposes.
A systems administrator is notified that the mysqld process stopped unexpectedly. The systems administrator issues the following command:
sudo grep –i -r ‘out of memory’ /var/log
The output of the command shows the following:
kernel: Out of memory: Kill process 9112 (mysqld) score 511 or sacrifice child.
Which of the following commands should the systems administrator execute NEXT to troubleshoot this issue? (Select two).
A.
free -h
B.
nc -v 127.0.0.1 3306
C.
renice -15 $( pidof mysql )
D.
lsblk
E.
killall -15
F.
vmstat -a 1 4
free -h
vmstat -a 1 4
Summary:
The mysqld process was killed by the kernel due to an Out of Memory (OOM) condition. This indicates the system exhausted its physical RAM and swap space, forcing the kernel to terminate a process (in this case, MySQL) to prevent a complete system crash. The next logical step is to investigate the current memory usage and system performance to understand the resource constraints that led to the OOM event.
Correct Options:
A. free -h:
This command provides a quick, human-readable overview of the system's current memory usage, showing total, used, free, and available RAM, as well as swap space. This is essential to see if the system is still under memory pressure.
F. vmstat -a 1 4:
This command provides a detailed, real-time report on system performance. It shows memory (active, inactive), swap, I/O, and CPU activity. Running it with an interval (1 second) for a few iterations (4 times) helps identify if the system is currently experiencing high memory pressure, swapping (si/so), or other resource contention that could lead to another OOM kill.
Incorrect Options:
B. nc -v 127.0.0.1 3306:
This command tests if the MySQL service is listening on its default port (3306). Since the process was killed, it is unlikely to be running, making this check less useful than diagnosing the root cause (memory exhaustion).
C. renice -15 $( pidof mysql ):
The renice command changes the priority of a running process. Since the MySQL process was killed, its PID no longer exists, so this command would fail. Furthermore, changing the priority would not resolve a lack of physical memory.
D. lsblk:
This command lists information about block devices (disks and partitions). The problem is related to memory (RAM), not disk space or storage configuration.
E. killall -15:
This command is used to send a SIGTERM signal to processes. The MySQL process is already dead, so there is nothing to kill. Using this would be irrelevant to troubleshooting the OOM condition.
Reference:
Linux man-pages project (free): The official documentation for the free command.
A Linux administrator recently downloaded a software package that is currently in a compressed file. Which of the following commands will extract the files?
A.
unzip -v
B.
bzip2 -z
C.
gzip
D.
funzip
gzip
Summary:
The administrator needs to extract files from a compressed software package. The correct command depends on the compression format used for the file. Common compression formats in Linux include .gz (gzip), .bz2 (bzip2), and .zip. The question implies a standard compressed file, and gzip is one of the most common utilities for this purpose, used to decompress files with the .gz extension.
Correct Option:
C. gzip:
This is the correct command for decompressing files compressed with gzip. The typical usage is gzip -d filename.gz or gunzip filename.gz, which will extract the contents of the compressed file. The gzip command by default decompresses when used with the -d flag.
Incorrect Options:
A. unzip -v:
The unzip command is specifically for .zip archives. The -v flag is for verbose listing of the archive contents, not for extraction. A more general extraction command would be unzip without flags.
B. bzip2 -z:
The bzip2 command is for files compressed with the .bz2 format. However, the -z flag is for compression, not extraction. The correct flag for decompression with bzip2 is -d.
D. funzip:
This is a specialized utility that unzips the first file in a .zip archive and sends it to standard output. It is not a general-purpose extraction tool for all compressed formats and is less commonly used than unzip or gzip.
Reference:
Linux man-pages project (gzip): The official documentation explains that gzip -d is used to decompress files.
Which of the following tools is commonly used for creating CI/CD pipelines?
A.
Chef
B.
Puppet
C.
Jenkins
D.
Ansible
Jenkins
Summary:
The question asks for a tool specifically designed for creating CI/CD (Continuous Integration/Continuous Deployment) pipelines. A CI/CD pipeline is an automated process that encompasses building, testing, and deploying code. The correct tool is one that orchestrates these stages through a defined workflow, often triggered by code commits.
Correct Option:
C. Jenkins:
This is the primary tool among the options for creating CI/CD pipelines. Jenkins is an open-source automation server that is specifically designed to set up and manage continuous integration and continuous delivery pipelines. It uses a flexible, plugin-based architecture to define complex workflows that can include building code, running tests, and deploying applications.
Incorrect Options:
A. Chef & B. Puppet:
These are Configuration Management tools. Their primary purpose is to automate the provisioning and configuration of servers to a desired state (e.g., installing packages, managing files). While they can be integrated into a CI/CD pipeline (e.g., a Jenkins job can trigger a Puppet run to configure a server), they are not the pipeline orchestration tools themselves.
D. Ansible:
Like Chef and Puppet, Ansible is primarily a Configuration Management and application deployment tool. It excels at defining and executing playbooks to configure systems. While it has features like Ansible Tower (AWX) that can help orchestrate workflows, the core Ansible engine is not a dedicated CI/CD pipeline tool in the way Jenkins is. Jenkins is more synonymous with the role of a pipeline orchestrator.
Reference:
Jenkins Official Website: The homepage describes Jenkins as "the leading open-source automation server" used for building, deploying, and automating any project, which is the definition of a CI/CD pipeline tool.
A systems administrator has been tasked with disabling the nginx service from the environment to prevent it from being automatically and manually started. Which of the following commands will accomplish this task?
A.
systemctl cancel nginx
B.
systemctl disable nginx
C.
systemctl mask nginx
D.
systemctl stop nginx
systemctl mask nginx
A Linux administrator copied a Git repository locally, created a feature branch, and committed some changes to the feature branch. Which of the following Git actions should the Linux administrator use to publish the changes to the main branch of the remote repository?
A.
rebase
B.
tag
C.
commit
D.
push
push
Summary:
The administrator has made commits to a local feature branch. To share these changes with others and integrate them into the collaborative project, the local commits must be uploaded to the shared, remote repository. The action that transfers local commits to a remote repository is a distinct command from those used for local history management.
Correct Option:
D. push:
This is the correct action. The git push command is used to upload local repository content to a remote repository. It transfers commits from your local branch (in this case, the feature branch) to the corresponding branch on the remote server, making them available to other team members. To get the changes into the main branch, the administrator would typically push the feature branch and then create a Pull Request or merge it on the remote platform (like GitHub or GitLab), or merge it locally and then push the main branch.
Incorrect Options:
A. rebase:
This is a history-rewriting command used to move or combine a sequence of commits to a new base commit. It is often used to maintain a clean project history. It is an operation performed on the local repository history and does not publish changes to a remote server.
B. tag:
This command is used to create, list, delete, or verify a tag object. Tags are typically used to mark specific points in history as being important (e.g., release versions like v1.0.0). It does not publish the changes from a feature branch.
C. commit:
The git commit command is used to save the staged changes to the local repository. The administrator has already performed this step. Committing records changes locally but does not share them with the remote repository.
Reference:
Official CompTIA Linux+ (XK0-005) Certification Exam Objectives: This question aligns with Objective 1.2: "Given a scenario, perform version control using Git," which requires knowledge of core Git commands. Understanding the workflow of commit (local save) followed by push (remote publish) is fundamental. The official Git website, git-scm.com, is the primary reference.
A systems administrator wants to test the route between IP address 10.0.2.15 and IP address 192.168.1.40. Which of the following commands will accomplish this task?
A.
route -e get to 192.168.1.40 from 10.0.2.15
B.
ip route get 192.163.1.40 from 10.0.2.15
C.
ip route 192.169.1.40 to 10.0.2.15
D.
route -n 192.168.1.40 from 10.0.2.15
ip route get 192.163.1.40 from 10.0.2.15
Summary:
The administrator needs to trace the exact network path a packet would take from a specific source IP (10.0.2.15) to a specific destination IP (192.168.1.40). This is different from simply viewing the routing table; it requires asking the kernel to resolve the path for a specific connection, showing the next-hop gateway and the egress interface. This is often called a "route lookup."
Correct Option:
B. ip route get 192.168.1.40 from 10.0.2.15:
This is the correct and modern command for this task. The ip route get command instructs the kernel to perform a route lookup as if a packet were being sent from the source IP to the destination IP. It displays the complete path, including the gateway and the network interface that would be used.
Incorrect Options:
A. route -e get to 192.168.1.40 from 10.0.2.15:
The route command is part of the deprecated net-tools package. While route -n can display the routing table, it does not have a get function that accepts a from parameter to test a specific source-destination pair.
C. ip route 192.169.1.40 to 10.0.2.15:
This command has multiple errors. First, the IP address is incorrect (192.169.1.40). Second, the syntax is invalid. The ip route command is primarily for managing the routing table (e.g., ip route add or ip route show), not for performing a specific route lookup with a source address.
D. route -n 192.168.1.40 from 10.0.2.15:
The route -n command displays the entire kernel routing table in numerical form. It does not take destination and source IP addresses as arguments to test a specific path.
Reference:
ip-route man page: The official documentation for the ip route command, which includes the get action for route lookups.
A systems administrator is tasked with setting up key-based SSH authentication. In which of the following locations should the administrator place the public keys for the server?
A.
~/.sshd/authkeys
B.
~/.ssh/keys
C.
~/.ssh/authorized_keys
D.
~/.ssh/keyauth
~/.ssh/authorized_keys
Summary:
The administrator is configuring key-based authentication for SSH. This method requires the user's public key to be stored on the server in a specific, standardized file. The SSH daemon (sshd) is programmed to look for this file in a predetermined location within the target user's home directory when a login attempt is made. The correct location is defined by the SSH protocol and server configuration.
Correct Option:
C. ~/.ssh/authorized_keys:
This is the standard and default location where the SSH daemon looks for public keys to authorize a user's login. Each line in this file contains one public key. When a user tries to connect, the server checks if the corresponding private key matches any of the public keys listed in this file.
Incorrect Options:
A. ~/.sshd/authkeys:
This path is incorrect. The .sshd directory is not a standard directory for SSH configuration on the client or server side for user keys.
B. ~/.ssh/keys:
While a .ssh directory is correct, the keys file is not the standard name recognized by the SSH daemon for authorized public keys.
D. ~/.ssh/keyauth:
This is also a non-standard filename. The SSH daemon will not check this file for authorization keys by default.
Reference:
OpenSSH Manual (sshd): The official documentation specifies that the authorized_keys file in the user's ~/.ssh directory lists the public keys that are permitted for logging in.
A systems administrator is troubleshooting a connectivity issue pertaining to access to a system named db.example.com. The system IP address should be 192.168.20.88. The administrator issues the dig command and receives the following output:
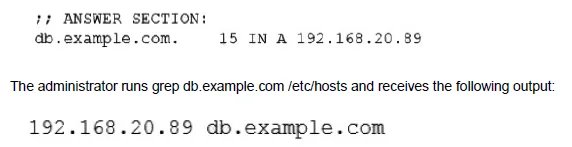
Given this scenario, which of the following should the administrator do to address this issue?
A.
Modify the /etc/hosts file and change the db.example.com entry to 192.168.20.89
B.
Modify the /etc/network file and change the db.example.com entry to 192.168.20.88
C.
Modify the /etc/network file and change the db.example.com entry to 192.168.20.89.
D.
Modify the /etc/hosts file and change the db.example.com entry to 192.168.20.88.
Modify the /etc/hosts file and change the db.example.com entry to 192.168.20.88.
Summary:
The administrator is troubleshooting access to db.example.com. The dig command shows that the DNS server correctly returns the IP address 192.168.20.88. However, the local /etc/hosts file has a static entry that maps db.example.com to a different, incorrect IP address (192.168.20.89). On most systems, /etc/hosts is checked before DNS, causing the system to use the wrong IP from the hosts file, leading to the connectivity issue.
Correct Option:
D. Modify the /etc/hosts file and change the db.example.com entry to 192.168.20.88.:
This is the correct solution. The local /etc/hosts file is overriding the correct DNS lookup. By correcting the entry in /etc/hosts to the intended IP address (192.168.20.88), the system will resolve db.example.com correctly, and connectivity should be restored.
Incorrect Options:
A. Modify the /etc/hosts file and change the db.example.com entry to 192.168.20.89.:
This would make the problem worse or, at best, keep it the same. The IP 192.168.20.89 is already the incorrect entry causing the issue. Changing it to the same value is pointless, and confirming the wrong address would not help.
B. Modify the /etc/network file and change the db.example.com entry to 192.168.20.88.:
There is no standard /etc/network file used for hostname-to-IP mapping. The correct file for static local host entries is /etc/hosts. The /etc/network/ directory typically contains interface configuration scripts, not hostname resolution entries.
C. Modify the /etc/network file and change the db.example.com entry to 192.168.20.89.:
This is incorrect for the same reasons as option B. The file is wrong, and the IP address is also wrong.
Reference:
Official CompTIA Linux+ (XK0-005) Certification Exam Objectives: This scenario falls under Objective 4.1: "Given a scenario, analyze and troubleshoot network connectivity issues," which includes troubleshooting name resolution. Understanding the order of name resolution (e.g., /etc/hosts before DNS in /etc/nsswitch.conf) and knowing how to correct static entries in /etc/hosts is a fundamental skill.
A development team asks an engineer to guarantee the persistency of journal log files across system reboots. Which of the following commands would accomplish this task?
A.
grep -i auto /etc/systemd/journald.conf && systemctl restart systemd-journald.service
B.
cat /etc/systemd/journald.conf | awk '(print $1,$3)'
C.
sed -i 's/auto/persistent/g' /etc/systemd/journald.conf && sed -i 'persistent/s/ˆ#//q'
/etc/systemd/journald.conf
D.
journalctl --list-boots && systemctl restart systemd-journald.service
sed -i 's/auto/persistent/g' /etc/systemd/journald.conf && sed -i 'persistent/s/ˆ#//q'
/etc/systemd/journald.conf
Summary:
By default, the systemd-journald service stores logs in a volatile, in-memory location (/run/log/journal/), which is cleared on reboot. To make logs persistent, the configuration in /etc/systemd/journald.conf must be changed. The Storage= parameter needs to be set to persistent and, crucially, the line must be uncommented by removing the leading # symbol.
Correct Option:
C. sed -i 's/auto/persistent/g' /etc/systemd/journald.conf && sed -i 'persistent/s/ˆ#//q' /etc/systemd/journald.conf:
This command accomplishes the task, though the q at the end is a typo and should likely be g. The first command changes the Storage parameter from auto to persistent. The second command uses a pattern to find the line containing "persistent" and removes the comment character (#) from the beginning of that line (s/ˆ#//), thereby activating the setting. A service restart would also be needed, which is implied for the change to take effect.
Incorrect Options:
A. grep -i auto /etc/systemd/journald.conf && systemct1 restart systemd-journald.service:
This command only searches for the word "auto" in the config file and then restarts the service. It does not actually modify the configuration file to change the Storage parameter to persistent or uncomment the necessary line, so it will not enable persistence.
B. cat /etc/systemd/journald.conf | awk '(print $1,$3)':
This is a purely diagnostic command that formats and displays the contents of the configuration file. It is a read-only operation and makes no changes to the system, so it cannot enable persistent logging.
D. journalctl --list-boots && systemct1 restart systemd-journald.service:
The journalctl --list-boots command displays a list of boot sessions currently available in the journal. This only shows data that is already stored; it does not configure future log persistence. Restarting the service without a configuration change will not enable persistence.
Reference:
Official CompTIA Linux+ (XK0-005) Certification Exam Objectives: This scenario falls under Objective 4.3: "Given a scenario, analyze and troubleshoot application and hardware issues," which includes managing logs. Configuring the systemd-journald service for persistent storage is a key task for ensuring log data is available for troubleshooting after a system reboot. The official systemd documentation for journald.conf is the primary reference.
A systems administrator received a notification that a system is performing slowly. When running the top command, the systems administrator can see the following values:

Which of the following commands will the administrator most likely run NEXT?
A.
vmstat
B.
strace
C.
htop
D.
lsof
vmstat
Summary:
The top output shows a critical issue: extremely high I/O wait (%wa is 70.2%) and zero idle time (%id is 0.0%). This clearly indicates the system is bottlenecked by disk I/O; processes are stalled waiting for read/write operations to complete. The next logical step is to investigate the details of this I/O activity to identify the root cause, such as which processes are causing heavy I/O, the read/write rates, and swap activity.
Correct Option:
A. vmstat:
This is the most likely next command. vmstat provides a detailed breakdown of system resources, including crucial I/O statistics that top does not show. Key columns to check would be:
si (swap in) and so (swap out): To see if high I/O is due to memory pressure and swapping.
bi (blocks in) and bo (blocks out): To see the actual disk block I/O rates.
us, sy, id, wa: To confirm the CPU breakdown in a different view.
It gives a broader, system-wide view of memory, swap, and I/O, which is the logical next step after top has identified I/O wait as the problem.
Incorrect Options:
B. strace:
strace is a debugging tool that traces system calls and signals made by a specific process. It is far too granular and would be used later to investigate a specific problematic process identified by broader tools like vmstat or iotop.
C. htop:
htop is an enhanced, interactive version of top. While it might provide a nicer interface or slightly more information, it essentially shows the same type of high-level data as top. Since top has already identified the general problem (I/O wait), the administrator should move to a more diagnostic tool like vmstat, not a similar one.
D. lsof:
lsof (list open files) is used to see which files a specific process has open. Like strace, this is a tool for drilling down into a specific process once it has been identified as the culprit. It is not the right tool for getting a system-wide overview of I/O and memory pressure.
Reference:
Official CompTIA Linux+ (XK0-005) Certification Exam Objectives: This scenario falls under Objective 4.3: "Given a scenario, analyze and troubleshoot application and hardware issues," which includes troubleshooting performance issues. The standard methodology is to start with general tools like top, then use more specific tools like vmstat (for memory/I/O) or iostat (for disk-specific I/O) to pinpoint the cause.
A Linux administrator has been tasked with installing the most recent versions of packages on a RPM-based OS. Which of the following commands will accomplish this task?
A.
apt-get upgrade
B.
rpm -a
C.
yum updateinfo
D.
dnf update
E.
yum check-update
dnf update
Summary:
The task is to install the most recent versions of all packages on an RPM-based operating system. This requires a command that performs two key actions: first, it must refresh the local cache of available packages from the remote repositories, and second, it must download and install the newer versions of all installed packages. The command must be the primary package manager for the system.
Correct Option:
D. dnf update:
This is the correct and modern command. dnf is the next-generation package manager for RPM-based distributions like Red Hat Enterprise Linux, Fedora, and CentOS. The dnf update command refreshes the repository metadata and then upgrades all installed packages to their latest available versions. It has effectively replaced yum as the default in newer versions of these distributions.
Incorrect Options:
A. apt-get upgrade:
This command is used on Debian-based distributions (like Ubuntu and Debian), not RPM-based systems. apt and yum/dnf are package managers for two different Linux families.
B. rpm -a:
This is an invalid command. The rpm command is the low-level package manager, but it does not have an -a flag to update all packages. It is used to install, query, and verify individual .rpm files, but it does not resolve dependencies or manage repositories like yum or dnf.
C. yum updateinfo:
This command is used to display information about available updates, including security advisories (errata). It is a diagnostic command that lists available updates but does not actually install any packages.
E. yum check-update:
This command checks the repositories for available updates and lists which packages have newer versions. Like yum updateinfo, it is a read-only command that checks for updates but does not download or install them.
Reference:
Official CompTIA Linux+ (XK0-005) Certification Exam Objectives: This scenario falls under Objective 1.1: "Given a scenario, perform a Linux installation and configuration," which includes managing software using package management. Knowing the correct command to update all packages on an RPM-based system (dnf update or yum update) is a fundamental administrative task.
| Page 7 out of 40 Pages |
| 123456789101112 |
| XK0-005 Practice Test Home |
Real-World Scenario Mastery: Our XK0-005 practice exam don't just test definitions. They present you with the same complex, scenario-based problems you'll encounter on the actual exam.
Strategic Weakness Identification: Each practice session reveals exactly where you stand. Discover which domains need more attention, before CompTIA Linux+ Certification exam day arrives.
Confidence Through Familiarity: There's no substitute for knowing what to expect. When you've worked through our comprehensive XK0-005 practice exam questions pool covering all topics, the real exam feels like just another practice session.
Copyright © All Rights Reserved