A DevOps engineer needs to allow incoming traffic to ports in the range of 4000 to 5000 on a Linux server. Which of the following commands will enforce this rule?
A.
iptables -f filter -I INPUT -p tcp --dport 4000:5000 -A ACCEPT
B.
iptables -t filter -A INPUT -p tcp --dport 4000:5000 -j ACCEPT
C.
iptables filter -A INPUT -p tcp --dport 4000:5000 -D ACCEPT
D.
iptables filter -S INPUT -p tcp --dport 4000:5000 -A ACCEPT
iptables -t filter -A INPUT -p tcp --dport 4000:5000 -j ACCEPT
Summary:
The engineer needs to create a firewall rule that accepts incoming TCP traffic on a range of ports (4000 to 5000). The iptables command is used to configure the Linux kernel's netfilter firewall. The correct command must use the proper syntax to append a rule to the INPUT chain of the filter table, matching the TCP protocol and the specified destination port range, and then jump to the ACCEPT target.
Correct Option:
B. iptables -t filter -A INPUT -p tcp --dport 4000:5000 -j ACCEPT:
This command is correctly structured.
-t filter specifies the table (filter is the default table, so this is often omitted, but it is correct to include it).
-A INPUT appends the rule to the INPUT chain.
-p tcp specifies the TCP protocol.
--dport 4000:5000 defines the destination port range.
-j ACCEPT is the target action, meaning to accept the packet.
Incorrect Options:
A. iptables -f filter -I INPUT -p tcp --dport 4000:5000 -A ACCEPT:
This command uses -f (which is not a standard flag for specifying a table; the correct flag is -t) and -I (which inserts a rule at the beginning of the chain). It also incorrectly uses -A ACCEPT instead of -j ACCEPT.
C. iptables filter -A INPUT -p tcp --dport 4000:5000 -D ACCEPT:
This command omits the -t flag for the table. It also uses -D ACCEPT, where -D is the command to delete a rule, not to set a jump target.
D. iptables filter -S INPUT -p tcp --dport 4000:5000 -A ACCEPT:
This command omits the -t flag and uses -S (which is for displaying the rules of a specific chain) and then tries to combine it with rule-adding parameters, which is invalid syntax.
Reference:
Netfilter/iptables Project Documentation: The official documentation details the correct syntax for the iptables command.
When trying to log in remotely to a server, a user receives the following message:
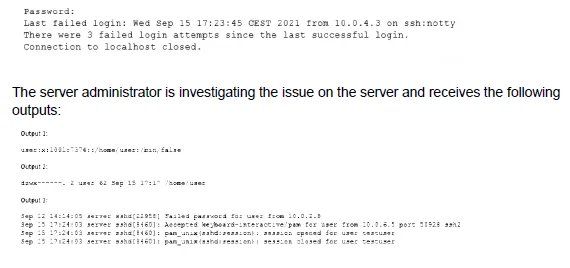
Which of the following is causing the issue?
A.
The wrong permissions are on the user’s home directory.
B.
The account was locked out due to three failed logins.
C.
The user entered the wrong password.
D.
The user has the wrong shell assigned to the account.
The user has the wrong shell assigned to the account.
Summary:
The user receives a "Connection closed" message immediately after the last failed login attempt, without being prompted for a password again. The key evidence is in Output 1 from /etc/passwd, which shows the user's login shell is set to /bin/false. This shell is not a functional interactive shell; it simply returns a false status and exits immediately. When SSH successfully authenticates a user, it launches their assigned shell. If that shell is /bin/false, it exits instantly, closing the connection.
Correct Option:
D. The user has the wrong shell assigned to the account:
This is the direct cause. The user's shell in /etc/passwd is /bin/false, which is often used to disable logins for service accounts. When SSH authenticates the user, it launches /bin/false, which exits immediately, resulting in the closed connection. This happens after authentication, which is why the log shows an "Accepted" message before the session closes.
Incorrect Options:
A. The wrong permissions on the user’s home directory:
Output 2 shows the home directory permissions are 700 (drwx------), which is correct and secure for a user's home directory. This is not the cause.
B. The account was locked out due to three failed logins:
Account lockouts typically result in a specific "Account locked" or "Permission denied" message, not a closed connection after an accepted login. The log (Output 3) shows a successful "Accepted" authentication followed by a session open/close, which indicates the login was technically successful but the session couldn't be maintained.
C. The user entered the wrong password:
The log in Output 3 shows a final "Accepted" message for the user, confirming the correct password was entered for that specific session. The previous failures were from a different IP and are not the reason for the immediate disconnect after the successful login.
Reference:
Linux man-pages project (passwd): The /etc/passwd file format defines the user's login shell in the last field. A non-existent or non-functional shell will prevent successful login.
Which of the following enables administrators to configure and enforce MFA on a Linux system?
A.
Kerberos
B.
SELinux
C.
PAM
D.
PKI
PAM
Summary:
Multi-Factor Authentication (MFA) requires integrating different authentication methods (like passwords, one-time codes, or biometrics) into the system's login process. This integration happens at the authentication layer, which is modular and configurable in Linux. The correct framework allows administrators to define a stack of authentication modules that must be satisfied for a successful login.
Correct Option:
C. PAM:
This is the correct framework. Pluggable Authentication Modules (PAM) is the subsystem in Linux that handles authentication tasks for applications and services. Administrators can configure MFA by editing PAM configuration files (in /etc/pam.d/) to require multiple authentication methods. For example, a configuration can first require a password (pam_unix.so) and then require a one-time token from a Google Authenticator module (pam_google_authenticator.so).
Incorrect Options:
A. Kerberos:
Kerberos is a network authentication protocol that uses tickets to allow nodes to communicate over a non-secure network to prove their identity to one another. It is a single sign-on (SSO) system, not a framework for configuring multiple distinct factors at the OS login prompt.
B. SELinux:
Security-Enhanced Linux is a kernel security module that provides a mechanism for supporting access control security policies, including mandatory access controls (MAC). It focuses on restricting what programs and users can do after they are logged in (file access, network ports, etc.), not on how they authenticate during the login process.
D. PKI:
A Public Key Infrastructure is a set of roles, policies, hardware, software, and procedures needed to create, manage, distribute, use, store, and revoke digital certificates and manage public-key encryption. It is used for asymmetric cryptography and can be one factor in an MFA setup (e.g., using a smart card), but PKI itself is not the system that enforces the multi-factor policy; that is the role of PAM.
Reference:
Official CompTIA Linux+ (XK0-005) Certification Exam Objectives: This knowledge aligns with Objective 4.2: "Given a scenario, implement and configure Linux firewalls and access control options," which includes implementing and configuring access controls. PAM is the primary technology for configuring advanced authentication methods on a Linux system.
Which of the following technologies provides load balancing, encryption, and observability in containerized environments?
A.
Virtual private network
B.
Sidecar pod
C.
Overlay network
D.
Service mesh
Service mesh
Summary:
The question asks for a technology specifically designed for containerized environments that consolidates the advanced networking functions of load balancing (distributing traffic), encryption (securing communication with mTLS), and observability (providing metrics, logs, and traces). This describes a dedicated infrastructure layer that manages service-to-service communication in a microservices architecture.
Correct Option:
D. Service mesh:
This is the correct technology. A service mesh is a dedicated infrastructure layer for handling service-to-service communication in a containerized application. Its key features include:
Load Balancing:
Intelligently distributing traffic between instances of a service.
Encryption:
Automatically encrypting traffic between services using mutual TLS (mTLS).
Observability:
Providing detailed telemetry data (metrics, logs, and traces) for monitoring and troubleshooting communication patterns.
Popular examples include Istio and Linkerd.
Incorrect Options:
A. Virtual private network:
A VPN is designed to create a secure, encrypted tunnel between a client and a network, or between two networks. It is not a container-specific technology and does not provide built-in load balancing or fine-grained observability for service-to-service traffic within a cluster.
B. Sidecar pod:
A sidecar is a design pattern, not a technology itself. In Kubernetes, a sidecar is a helper container that runs alongside the main application container in a pod. While a service mesh uses a sidecar pattern (by injecting a proxy container next to each service), the sidecar itself is just one component and does not encompass the full set of features like cluster-wide load balancing and observability that define a service mesh.
C. Overlay network:
An overlay network is a virtual network built on top of another network. In container orchestration (like Kubernetes), it allows pods on different nodes to communicate. While it provides connectivity, its primary purpose is not load balancing, encryption, or observability. It is a foundational networking layer upon which technologies like a service mesh are built.
Reference:
Official CompTIA Linux+ (XK0-005) Certification Exam Objectives: This knowledge aligns with the container management concepts in Objective 1.5. Understanding advanced container networking concepts like service meshes is part of managing modern, cloud-native applications.
A developer reported an incident involving the application configuration file /etc/httpd/conf/httpd.conf that is missing from the server. Which of the following identifies the RPM package that installed the configuration file?
A.
rpm -qf /etc/httpd/conf/httpd.conf
B.
rpm -ql /etc/httpd/conf/httpd.conf
C.
rpm —query /etc/httpd/conf/httpd.conf
D.
rpm -q /etc/httpd/conf/httpd.conf
rpm -qf /etc/httpd/conf/httpd.conf
Summary:
A critical application configuration file is missing. To restore it, the administrator first needs to identify which RPM (Red Hat Package Manager) package originally installed the file. This will allow them to know which package to reinstall to get a fresh copy of the default configuration file. The correct RPM command must be one that queries the package database to find the owner of a specific file.
Correct Option:
A. rpm -qf /etc/httpd/conf/httpd.conf:
This is the correct command. The -qf flags stand for query file. This command interrogates the RPM database to determine which installed package owns, or provided, the specified file (/etc/httpd/conf/httpd.conf). Once the package name (e.g., httpd) is known, the administrator can reinstall it with rpm -Uvh --replacepkgs httpd or yum reinstall httpd to restore the missing file.
Incorrect Options:
B. rpm -ql /etc/httpd/conf/httpd.conf:
The -ql flags stand for query list. This command is used to list all the files that are installed by a given package name. For example, rpm -ql httpd would list all files from the httpd package. Using a file path as the argument is incorrect syntax and will result in an error.
C. rpm —query /etc/httpd/conf/httpd.conf:
The --query option is used to query packages, but it requires specific query flags (like -f or -l) to define the type of query. Using it alone with a file path is invalid syntax and will not work.
D. rpm -q /etc/httpd/conf/httpd.conf:
The -q flag is for querying a package, but it expects a package name as an argument, not a file path. For example, rpm -q httpd checks if the httpd package is installed. Providing a file path will cause RPM to look for a package with that exact name, which does not exist, and will return "package /etc/httpd/conf/httpd.conf is not installed."
Reference:
Official CompTIA Linux+ (XK0-005) Certification Exam Objectives: This scenario falls under Objective 1.1: "Given a scenario, perform a Linux installation and configuration," which includes managing software using package management. Knowing how to use rpm -qf to identify the package that owns a file is a fundamental troubleshooting skill.
A systems administrator needs to check if the service systemd-resolved.service is running without any errors. Which of the following commands will show this information?
A.
systemctl status systemd-resolved.service
B.
systemctl enable systemd-resolved.service
C.
systemctl mask systemd-resolved.service
D.
systemctl show systemd-resolved.service
systemctl status systemd-resolved.service
Summary:
The administrator needs to verify the current runtime state of a specific systemd service, including whether it is active, any recent errors, and its log output. The command must provide a concise, human-readable status overview that is used for immediate troubleshooting and verification of service health.
Correct Option:
A. systemctl status systemd-resolved.service:
This is the primary command for checking a service's runtime status. It displays a summary showing whether the service is active (running), enabled, the main process ID, and the most recent log entries from the service's journal. This is the ideal tool for quickly determining if a service is running without errors.
Incorrect Options:
B. systemctl enable systemd-resolved.service:
This command configures the service to start automatically at boot. It does not show the current running status or any error messages; it only changes the startup configuration.
C. systemctl mask systemd-resolved.service:
This command prevents a service from being started, both manually and automatically, by linking it to /dev/null. It is a powerful administrative action to completely disable a service, not a command to check its status.
D. systemctl show systemd-resolved.service:
This command displays all the low-level properties and settings of the service unit from the systemd manager itself. While it provides extensive configuration data, its output is very verbose and not optimized for a quick check of operational status and errors.
Reference:
systemd Official Documentation (systemctl): The official man page details the status command and its purpose for showing brief runtime status information.
Users have been unable to save documents to /home/tmp/temp and have been receiving the following error:
A junior technician checks the locations and sees that /home/tmp/tempa was accidentally created instead of /home/tmp/temp. Which of the following commands should the technician use to fix this issue?
A.
cp /home/tmp/tempa /home/tmp/temp
B.
mv /home/tmp/tempa /home/tmp/temp
C.
cd /temp/tmp/tempa
D.
ls /home/tmp/tempa
mv /home/tmp/tempa /home/tmp/temp
Summary:
A directory was created with the incorrect name /home/tmp/tempa instead of the required /home/tmp/temp. Users and applications are trying to save files to the correct path but receiving a "Path not found" error. The solution is to rename the existing misnamed directory to the correct name, which will immediately resolve the path issue for all users without needing to copy data or change application configurations.
Correct Option:
B. mv /home/tmp/tempa /home/tmp/temp:
This is the correct and most efficient command. The mv (move) command is used in Linux to both move and rename files and directories. This command will rename the directory from tempa to temp in its current location. Once the directory has the correct name, the users' save operations will succeed as the expected path will now exist.
Incorrect Options:
A. cp /home/tmp/tempa /home/tmp/temp:
This command would attempt to copy the contents of the tempa directory into a new directory named temp. If temp does not exist, it might create it, but it would result in two separate directories (tempa and temp). The original, incorrectly named tempa directory would still exist, and the copy operation might not preserve all file attributes and permissions correctly.
C. cd /temp/tmp/tempa:
This command is used to change the current working directory of the shell to the incorrectly named path. It is a navigation command only and performs no action to fix the underlying problem of the misnamed directory.
D. ls /home/tmp/tempa:
This command lists the contents of the incorrectly named directory. Like the cd command, it is a read-only diagnostic command that only displays information. It does not modify the filesystem or resolve the issue.
Reference:
Official CompTIA Linux+ (XK0-005) Certification Exam Objectives: This scenario falls under Objective 3.2: "Given a scenario, manage storage, files, and directories in a Linux environment," which includes using commands to manage and manipulate files and directories. The mv command is a fundamental tool for this objective.
A cloud engineer is asked to copy the file deployment.yaml from a container to the host where the container is running. Which of the following commands can accomplish this task?
A.
docker cp container_id/deployment.yaml deployment.yaml
B.
docker cp container_id:/deployment.yaml deployment.yaml
C.
docker cp deployment.yaml local://deployment.yaml
D.
docker cp container_id/deployment.yaml local://deployment.yaml
docker cp container_id:/deployment.yaml deployment.yaml
Summary:
The task requires copying a file from a running Docker container to the host filesystem. The correct command must use the proper docker cp syntax, which requires specifying the source as
Correct Option:
B. docker cp container_id:/deployment.yaml deployment.yaml: This command uses the correct syntax.
container_id:/deployment.yaml correctly identifies the source as the file /deployment.yaml located inside the container with the specified ID.
deployment.yaml specifies the destination as a file in the current working directory on the host machine. This will successfully copy the file from the container to the host.
Incorrect Options:
A. docker cp container_id/deployment.yaml deployment.yaml:
This syntax is incorrect because it uses a forward slash (/) instead of a colon (:) to separate the container ID from the file path. The command will fail because it interprets container_id/deployment.yaml as a path on the host, not inside the container.
C. docker cp deployment.yaml local://deployment.yaml:
This command is reversed and uses invalid syntax. It attempts to copy a file named deployment.yaml from the host into the container, but the local:// prefix is not valid for the docker cp command.
D. docker cp container_id/deployment.yaml local://deployment.yaml:
This command has the same source syntax error as option A (missing colon). Furthermore, the local:// destination prefix is invalid. The correct way to specify a host path is to use a simple file path.
Reference:
Docker Documentation (docker cp): The official documentation explains the command syntax for copying files between a container and the local filesystem.
A Linux administrator rebooted a server. Users then reported some of their files were missing. After doing some troubleshooting, the administrator found one of the filesystems was missing. The filesystem was not listed in /etc/f stab and might have been mounted manually by someone prior to reboot. Which of the following would prevent this issue from reoccurring in the future?
A.
Sync the mount units.
B.
Mount the filesystem manually.
C.
Create a mount unit and enable it to be started at boot.
D.
Remount all the missing filesystems
Create a mount unit and enable it to be started at boot.
Summary:
The issue occurred because a filesystem was mounted manually, and this temporary mount was lost after a reboot since it was not configured to persist. The manual mount was not recorded in the system's configuration. To prevent this from happening again, the administrator must create a permanent configuration that automatically mounts the filesystem during the boot process.
Correct Option:
C. Create a mount unit and enable it to be started at boot.:
This is the correct and modern solution. On systems using systemd, persistent filesystem mounts are managed by creating mount unit files (e.g., /etc/systemd/system/mnt-data.mount). These units define what to mount, where to mount it, and the filesystem type. Enabling this unit ensures the filesystem is mounted automatically at boot, making the mount persistent across reboots. Alternatively, adding an entry to /etc/fstab accomplishes the same goal and is the traditional method, which systemd also reads.
Incorrect Options:
A. Sync the mount units.:
This is not a standard command or procedure. While systemctl daemon-reload is used to reload unit files after creating or modifying them, "syncing mount units" is not the specific action that solves the root cause of a missing persistent configuration.
B. Mount the filesystem manually.:
This is exactly what caused the problem. A manual mount (using the mount command) is temporary and only lasts until the next reboot. It does not solve the persistence issue.
D. Remount all the missing filesystems.:
Remounting the filesystems manually would restore access for the current session, but it is a temporary fix. The mounts would be lost again after the next reboot, as it does not address the lack of a permanent configuration.
Reference:
Official CompTIA Linux+ (XK0-005) Certification Exam Objectives: This scenario falls under Objective 3.2: "Given a scenario, manage storage, files, and directories in a Linux environment," which includes configuring the fstab file (or systemd mount units) for persistent mounting. This is a fundamental concept for ensuring data availability after system restarts.
A Linux administrator created a new file system. Which of the following files must be updated to ensure the filesystem mounts at boot time?
A.
/etc/sysctl
B.
/etc/filesystems
C.
/etc/fstab
D.
/etc/nfsmount.conf
/etc/fstab
Summary:
To ensure a filesystem is automatically mounted every time the system boots, its configuration must be added to the system's filesystem table. This table is read by the mount command during the system's startup sequence. The correct file contains a list of all filesystems, their mount points, types, and options that should be mounted automatically.
Correct Option:
C. /etc/fstab:
This is the correct file. The fstab (filesystem table) file is the central configuration file that defines how and where storage devices and partitions should be mounted. Adding an entry for the new filesystem to /etc/fstab ensures the operating system will attempt to mount it automatically at boot time.
Incorrect Options:
A. /etc/sysctl:
This file is used to configure kernel parameters at boot time, such as network settings and system limits. It is not used for defining filesystem mount points.
B. /etc/filesystems:
This file is used to set the default search order for filesystem types when mounting a device without specifying a type. It does not define which filesystems to mount at boot.
D. /etc/nfsmount.conf:
This file contains default options for NFS (Network File System) mounts. It is specific to NFS and is not the general configuration file for all filesystem mounts at boot.
Reference:
Linux man-pages project (fstab): The official documentation explains the purpose and format of the /etc/fstab file.
A new Linux systems administrator just generated a pair of SSH keys that should allow connection to the servers. Which of the following commands can be used to copy a key file to remote servers? (Choose two.)
A.
wget
B.
ssh-keygen
C.
ssh-keyscan
D.
ssh-copy-id
E.
ftpd
F.
scp
ssh-copy-id
scp
Summary:
The administrator needs to transfer the public SSH key to a remote server to enable passwordless authentication. This involves copying the ~/.ssh/id_rsa.pub file (or similar) to the remote server and appending it to the ~/.ssh/authorized_keys file in the target user's home directory. The correct commands must securely transfer the file and handle its placement correctly.
Correct Options:
D. ssh-copy-id:
This is the dedicated and recommended command for this task. It automatically copies the public key to the remote server, ensures the ~/.ssh directory exists with correct permissions, and appends the key to the authorized_keys file, all in one secure step.
F. scp:
The Secure Copy command can be used to manually transfer the public key file to the remote server. The administrator would then need to manually log in via SSH and append the key to the authorized_keys file (e.g., cat id_rsa.pub >> ~/.ssh/authorized_keys). It is a manual two-step process but achieves the goal.
Incorrect Options:
A. wget:
This is a command-line tool for downloading files from the web (HTTP, HTTPS, FTP). It is not used for securely transferring files to a remote server via SSH.
B. ssh-keygen
This command is used to generate new SSH key pairs, not to copy them to remote servers. Its job is complete once the keys are created on the local machine.
C. ssh-keyscan:
This utility is used to collect public SSH host keys from remote servers. It helps populate the local known_hosts file to avoid trust-on-first-use prompts, but it does not copy user keys to the server.
E. ftpd:
This is the File Transfer Protocol daemon, a service that runs on a server. It is not a client command for copying files, and using FTP is insecure compared to SCP or SSH-based methods.
Reference:
OpenSSH Manual (ssh-copy-id): The official documentation explains that ssh-copy-id installs public keys in a remote machine's authorized_keys.
A systems administrator wants to back up the directory /data and all its contents to /backup/data on a remote server named remote. Which of the following commands will achieve the desired effect?
A.
scp -p /data remote:/backup/data
B.
ssh -i /remote:/backup/ /data
C.
rsync -a /data remote:/backup/
D.
cp -r /data /remote/backup/
rsync -a /data remote:/backup/
Summary:
The task requires efficiently synchronizing an entire local directory (/data) to a specific location on a remote server. The command must handle the transfer over the network, preserve file attributes (like permissions and timestamps), and copy the contents of the directory into the target path. The tool must be suitable for backing up directory structures.
Correct Option:
C. rsync -a /data remote:/backup/: This is the ideal command for this task.
rsync is designed for efficient file synchronization and transfer.
The -a (archive) flag preserves permissions, timestamps, and performs a recursive copy, which is essential for a complete backup.
The syntax /data remote:/backup/ will copy the entire contents of the local /data directory into the remote /backup/ directory, effectively creating /backup/data on the remote server.
Incorrect Options:
A. scp -p /data remote:/backup/data:
While scp can copy files over SSH, the -p flag only preserves timestamps, not all file attributes. More importantly, if /backup/data doesn't exist on the remote server, scp may fail or behave unexpectedly with directories. rsync is generally more robust for directory synchronization.
B. ssh -i /remote:/backup/ /data:
This command is completely invalid. The ssh command is used to log into a remote shell, not to copy files. The syntax is nonsensical for a file transfer operation.
D. cp -r /data /remote/backup/:
The cp command is for local copies only. It cannot transfer files to a remote server. It would interpret /remote/backup/ as a local directory path, which does not exist.
Reference:
rsync Official Documentation: The man page details the -a flag and the command's syntax for remote transfers.
| Page 4 out of 40 Pages |
| 123456789101112 |
| XK0-005 Practice Test Home |
Real-World Scenario Mastery: Our XK0-005 practice exam don't just test definitions. They present you with the same complex, scenario-based problems you'll encounter on the actual exam.
Strategic Weakness Identification: Each practice session reveals exactly where you stand. Discover which domains need more attention, before CompTIA Linux+ Certification exam day arrives.
Confidence Through Familiarity: There's no substitute for knowing what to expect. When you've worked through our comprehensive XK0-005 practice exam questions pool covering all topics, the real exam feels like just another practice session.
Copyright © All Rights Reserved