A systems administrator is implementing a new service task with systems at startup and needs to execute a script entitled test.sh with the following content:

The administrator tries to run the script after making it executable with chmod +x; however, the script will not run. Which of the following should the administrator do to address this issue? (Choose two.)
A.
Add #!/bin/bash to the bottom of the script.
B.
Create a unit file for the new service in /etc/systemd/system/ with the name helpme.service in the location.
C.
Add #!//bin/bash to the top of the script.
D.
Restart the computer to enable the new service.
E.
Create a unit file for the new service in /etc/init.d with the name helpme.service in the location.
F.
Shut down the computer to enable the new service.
Create a unit file for the new service in /etc/systemd/system/ with the name helpme.service in the location.
Add #!//bin/bash to the top of the script.
Summary:
The administrator needs to run a script at system startup. The script itself failed to execute, likely due to a missing shebang line. Furthermore, to automatically run a script during the boot process on a modern Linux system, it must be defined as a service using systemd. This requires creating a unit file that tells systemd when and how to execute the script.
Correct Options:
B. Create a unit file for the new service in /etc/systemd/system/ with the name helpme.service:
On systems using systemd (which is the modern standard), services are started via unit files. Creating a custom unit file in /etc/systemd/system/ is the correct method to define a new service that will start at boot. The name helpme.service aligns with the script's purpose.
C. Add #!/bin/bash to the top of the script:
The shebang (#!) must be the very first line of an executable script to tell the kernel which interpreter (in this case, /bin/bash) should be used to run the file. The provided option has a typo (#!//bin/bash), but the core action of adding a correct shebang to the top is essential. The correct syntax is #!/bin/bash.
Incorrect Options:
A. Add #!/bin/bash to the bottom of the script:
The shebang is only recognized if it is on the first line of the script. Placing it at the bottom has no effect and the script will still fail to execute properly.
D. Restart the computer to enable the new service:
While a restart (or systemctl daemon-reload) is needed after creating the unit file, a restart alone does not fix the underlying issue of the missing unit file and the broken script. This is a step that comes later, not a solution to the core problems.
E. Create a unit file for the new service in /etc/init.d with the name helpme.service:
The /etc/init.d/ directory is for SysVinit scripts, not native systemd unit files. While some systems might support it for compatibility, the standard and correct method for new services on a systemd system is to create a file in /etc/systemd/system/.
F. Shut down the computer to enable the new service:
This is unnecessary and incorrect. A full shutdown is not required to enable a systemd service. The system can be reloaded and the service started using systemctl commands.
Reference:
systemd Official Documentation (systemd.unit): The official documentation explains how to write and place unit files.
https://www.freedesktop.org/software/systemd/man/systemd.unit.html
Linux man-pages project (execve): The man page for the execve system call describes the requirement for the shebang line at the top of a script.
A systems administrator is deploying three identical, cloud-based servers. The administrator is using the following code to complete the task:

Which of the following technologies is the administrator using?
A.
Ansible
B.
Puppet
C.
Chef
D.
Terraform
Terraform
Summary:
The administrator is deploying cloud-based infrastructure (servers) using a declarative code file. The code specifies the cloud provider (aws), the resource type (instance), and the number of identical resources (count = 3). This approach describes Infrastructure as Code (IaC) where the entire infrastructure lifecycle is managed through configuration files rather than manual processes.
Correct Option:
D. Terraform:
This is the correct technology. The code snippet shown uses HashiCorp Configuration Language (HCL), which is the native language for Terraform. Terraform is an Infrastructure as Code tool specifically designed to provision and manage cloud infrastructure across various providers (like AWS, as shown here) in a declarative way. The resource, aws_instance, and count parameters are classic Terraform constructs.
Incorrect Options:
A. Ansible:
Ansible is primarily a configuration management and application deployment tool that uses YAML syntax (Playbooks). It is agentless and uses SSH for connectivity. The code shown is not YAML and does not use Ansible's module structure.
B. Puppet:
Puppet is a configuration management tool that uses its own declarative language or Ruby-based DSL. It focuses on defining the desired state of system configuration (packages, files, services) on existing servers, not on provisioning the cloud infrastructure itself.
C. Chef:
Chef is a configuration management tool that uses Ruby-based recipes and cookbooks to manage the configuration of systems. Like Puppet, it is focused on configuring existing servers rather than provisioning the initial cloud infrastructure.
Reference:
Terraform Official Documentation (AWS Provider): The official documentation shows the syntax for defining AWS instances, which matches the code structure in the question.
A Linux user reported the following error after trying to connect to the system remotely:
ssh: connect to host 10.0.1.10 port 22: Resource temporarily unavailable.
The Linux systems administrator executed the following commands in the Linux system while trying to diagnose this issue:
Which of the following commands will resolve this issue?
A.
firewall-cmd --zone=public --permanent --add-service=22
B.
systemctl enable firewalld; systemctl restart firewalld
C.
firewall-cmd --zone=public --permanent --add-service=ssh
D.
firewall-cmd --zone=public --permanent --add-port=22/udp
firewall-cmd --zone=public --permanent --add-service=ssh
Summary:
A user cannot connect via SSH, receiving a "Resource temporarily unavailable" error. The administrator's diagnostic commands show that the firewalld service is active and that the SSH service is not in the list of allowed services in the public zone. This indicates the firewall is actively blocking the SSH connection attempt on its default port, TCP 22. The solution is to add the SSH service to the firewall's permanent configuration.
Correct Option:
C. firewall-cmd --zone=public --permanent --add-service=ssh:
This is the correct command. It uses the predefined ssh service, which is a helper that maps to the standard SSH port (TCP 22). The --permanent flag writes the rule to the configuration file so it persists after a reboot. After running this, the administrator would need to run firewall-cmd --reload to activate the change, allowing SSH connections.
Incorrect Options:
A. firewall-cmd --zone=public --permanent --add-service=22:
This is invalid syntax. The --add-service parameter requires the name of a predefined service (like ssh, http, https), not a port number. There is no service defined by the name "22".
B. systemct1 enable firewalld; systemct1 restart firewalld:
This command ensures the firewall is enabled to start on boot and restarts it. However, it does not add any rule to allow SSH traffic. Since the firewall is already running (as shown in the diagnostics), this would just restart it with the same restrictive rules, leaving the SSH port blocked.
D. firewall-cmd --zone=public --permanent --add-port=22/udp:
This command is incorrect because it opens port 22 for UDP traffic. SSH uses the TCP protocol. This rule would have no effect on SSH connections, which rely on TCP.
Reference:
Official CompTIA Linux+ (XK0-005) Certification Exam Objectives: This scenario falls under Objective 4.2: "Given a scenario, implement and configure Linux firewalls and access control options," which includes managing firewalld using the firewall-cmd utility. Knowing how to allow services by name is a key skill.
A systems administrator made some unapproved changes prior to leaving the company. The newly hired administrator has been tasked with revealing the system to a compliant state. Which of the following commands will list and remove the correspondent packages?
A.
dnf list and dnf remove last
B.
dnf remove and dnf check
C.
dnf info and dnf upgrade
D.
dnf history and dnf history undo last
dnf history and dnf history undo last
Summary:
The new administrator needs to revert the system to a previous, compliant state by undoing changes made by the former employee. The DNF package manager keeps a transaction history of all package operations (install, update, remove). The correct approach is to first review this history to identify the problematic transactions and then use the history feature to revert them precisely.
Correct Option:
D. dnf history and dnf history undo last:
This is the correct and most efficient pair of commands.
dnf history lists the recent transactions, allowing the administrator to see what the previous administrator did.
dnf history undo last will revert the most recent transaction, removing installed packages or reinstalling removed ones to return the system to the state it was in before that transaction.
Incorrect Options:
A. dnf list and dnf remove last:
The dnf list command shows available packages, not a history of changes. The dnf remove last command would try to remove a package named "last," which is not the intended action.
B. dnf remove and dnf check:
The dnf remove command requires specifying a package name and would not be based on historical transactions. The dnf check command checks for problems in the package database but does not show or revert changes.
C. dnf info and dnf upgrade:
The dnf info command displays details about a specific package. The dnf upgrade command updates packages to newer versions, which is the opposite of reverting to a previous state.
Reference:
DNF Command Reference (history): The official documentation explains how to use the history feature to list, undo, and redo transactions.
A Linux administrator is troubleshooting the root cause of a high CPU load and average.
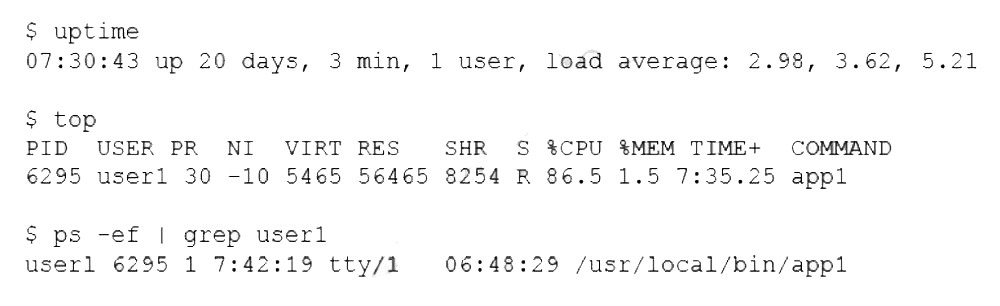
Which of the following commands will permanently resolve the issue?
A.
renice -n -20 6295
B.
pstree -p 6295
C.
iostat -cy 1 5
D.
kill -9 6295
kill -9 6295
Summary:
The administrator needs to permanently resolve the issue of a high CPU load caused by a specific process (PID 6295). A permanent resolution means stopping the process that is consuming excessive resources so it no longer impacts the system. The command must terminate the process definitively.
Correct Option:
D. kill -9 6295:
This command sends the SIGKILL signal (number 9) to the process with PID 6295. SIGKILL is a forceful, non-catchable signal that immediately terminates the process. This action will permanently stop the process from consuming CPU, resolving the high load issue.
Incorrect Options:
A. renice -n -20 6295:
This command increases the scheduling priority of the process (makes it "nicer" to the CPU scheduler), which would actually allocate more CPU time to it, making the high load problem worse, not resolving it.
B. pstree -p 6295:
This command displays a tree diagram of the process and its child processes. It is a diagnostic tool for understanding process relationships but takes no action to resolve the high CPU load.
C. iostat -cy 1 5:
This command displays CPU statistics and disk I/O metrics. Like pstree, it is a diagnostic tool used for monitoring and identifying the source of a performance issue but does not perform any corrective action to stop the problematic process.
Reference:
Linux man-pages project (kill): The official documentation explains the kill command and the different signals, including SIGKILL (9)
Which of the following technologies can be used as a central repository of Linux users and groups?
A.
LDAP
B.
MFA
C.
SSO
D.
PAM
LDAP
Summary:
The question asks for a technology that functions as a central repository for user and group information. This requires a directory service designed to store, organize, and provide access to identity data (like usernames, groups, and passwords) from a central location, which can then be used by multiple Linux systems on a network for authentication and authorization.
Correct Option:
A. LDAP:
The Lightweight Directory Access Protocol is the standard technology for a centralized directory service. An LDAP server (such as OpenLDAP or Microsoft Active Directory) acts as a central repository that stores user accounts, groups, and other information. Linux systems can be configured as LDAP clients to authenticate users against this central server, providing a single source of truth for user management.
Incorrect Options:
B. MFA:
Multi-Factor Authentication is a security method that requires users to provide two or more verification factors to gain access. It is an authentication mechanism, not a repository for storing user and group data.
C. SSO:
Single Sign-On is an authentication scheme that allows a user to log in with a single ID and password to access multiple related but independent software systems. It is a user experience and workflow, not the underlying repository where the user data is stored. SSO systems often use LDAP as their backend directory.
D. PAM:
Pluggable Authentication Modules is a flexible framework on Linux that determines how applications authenticate users. PAM is a local authentication subsystem that can be configured to use various sources (like local files, LDAP, or RSA tokens), but it is not the central repository itself.
Reference:
OpenLDAP Official Website: The home page for the most common open-source LDAP suite, which describes its purpose as a directory service.
A systems administrator is encountering performance issues. The administrator runs 3 commands with the following output

The Linux server has the following system properties
CPU: 4 vCPU
Memory: 50GB
Which of the following accurately describes this situation?
A.
The system is under CPU pressure and will require additional vCPUs
B.
The system has been running for over a year and requires a reboot.
C.
Too many users are currently logged in to the system
D.
The system requires more memory
The system is under CPU pressure and will require additional vCPUs
Summary:
The output from the performance commands reveals the core issue. The uptime load average of 98.65, 97.80, 96.52 is extremely high, especially on a 4 vCPU system (a load average consistently above 4.0 indicates saturation). The top output confirms this, showing that the CPU is 100% utilized in user space (%us), with no idle time (%id). The iostat output shows very low disk utilization (%util is 0.09%), ruling out an I/O bottleneck. This points to a severe CPU-bound process.
Correct Option:
A. The system is under CPU pressure and will require additional vCPUs.:
This is the most accurate description. The system's 4 vCPUs are completely saturated, as evidenced by the load average being ~25 times the CPU count and the 0.0% idle time. The process monitor.sh is consuming 98.7% of the CPU. While optimizing this process should be the first step, the data shows the current workload is too demanding for the existing 4 vCPUs, making additional CPU capacity a direct requirement.
Incorrect Options:
B. The system has been running for over a year and requires a reboot.:
While the uptime shows 421 days, a high uptime alone does not cause performance degradation. The data clearly points to a specific process (monitor.sh) consuming all CPU resources. A reboot would only temporarily fix the issue if it stops the problematic process, but it would not address the root cause of insufficient CPU capacity for the workload.
C. Too many users are currently logged in to the system.:
The w command shows only 4 users logged in. This is not an excessive number and is not the cause of the extreme CPU load, which is being generated by a single, specific process.
D. The system requires more memory.:
The top output shows that 50GB of RAM is mostly free (48985632k free). Only 2.5GB is used, and there is no significant swap usage. Memory is not the bottleneck in this scenario.
Reference:
Official CompTIA Linux+ (XK0-005) Certification Exam Objectives: This scenario falls under Objective 4.3: "Given a scenario, analyze and troubleshoot application and hardware issues," which includes troubleshooting performance issues. The ability to correlate data from uptime (load average), top (CPU usage per process), and iostat (disk I/O) to correctly identify a CPU bottleneck is a key skill.
A systems administrator created a web server for the company and is required to add a tag for the API so end users can connect. Which of the following would the administrator do to complete this requirement?
A.
hostnamectl status --no-ask-password
B.
hostnamectl set-hostname "$(perl -le "print" "A" x 86)"
C.
hostnamectl set-hostname Comptia-WebNode -H root@192.168.2.14
D.
hostnamectl set-hostname Comptia-WebNode --transient
hostnamectl set-hostname Comptia-WebNode -H root@192.168.2.14
Summary:
The requirement is to add a hostname "tag" for an API endpoint, which means setting a meaningful and discoverable hostname on the web server. The hostnamectl command is the standard tool for this on modern Linux systems. The correct command must permanently set the desired hostname (Comptia-WebNode) and should be executable for a remote server, which is a common administrative task.
Correct Option:
C. hostnamectl set-hostname Comptia-WebNode -H root@192.168.2.14:
This command is the most complete and practical for the scenario. set-hostname Comptia-WebNode sets the static hostname to the required tag.
The -H root@192.168.2.14 option allows the command to be executed remotely on the target server via SSH, which is a typical administration method. This fulfills the requirement of configuring the server for the API.
Incorrect Options:
A. hostnamectl status --no-ask-password:
This command only displays the current hostname and related settings. It is a read-only command and does not change or set any hostname, so it cannot complete the requirement.
B. hostnamectl set-hostname "$(perl -le "print" "A" x 86)":
This command uses a Perl script to set the hostname to a string of 86 'A' characters. Hostnames have a maximum length limit (usually 64 characters), so this would fail. It is nonsensical and does not set the required Comptia-WebNode name.
D. hostnamectl set-hostname Comptia-WebNode --transient:
The --transient flag sets the hostname only for the current session; it is not saved permanently. The change would be lost after a reboot, making it unsuitable for a production web server that needs a persistent identity.
Reference:
systemd Official Documentation (hostnamectl): The official man page explains the set-hostname command and its options, including -H for remote operation.
A Linux engineer set up two local DNS servers (10.10.10.10 and 10.10.10.20) and was testing email connectivity to the local mail server using the mail command on a localmachine when the following error appeared:

Which of the following commands could the engineer use to query the DNS server to get mail server information?
A.
dig @example.com 10.10.10.20 a
B.
dig @10.10.10.20 example.com mx
C.
dig @example.com 10.10.10.20 ptr
D.
dig @10.10.10.20 example.com ns
dig @10.10.10.20 example.com mx
Summary:
The engineer needs to troubleshoot why the mail command cannot find the mail server for example.com. The dig command is the correct tool for querying DNS servers directly. The goal is to ask a specific DNS server for the Mail Exchanger (MX) record of the domain, which defines its mail servers. The correct command must target the correct DNS server and request the correct record type.
Correct Option:
B. dig @10.10.10.20 example.com mx: This command is correctly structured.
@10.10.10.20 tells dig to query the specific DNS server at this IP address, which is one of the local DNS servers set up for testing.
example.com is the domain being queried.
mx specifies the record type, which is the Mail Exchanger record that lists the mail servers for the domain. This directly addresses the mail connectivity error.
Incorrect Options:
A. dig @example.com 10.10.10.20 a:
This syntax is reversed and incorrect. The server to query must come immediately after the @ symbol. It also queries for an A record (address record), which returns a host's IP address, not the mail server information.
C. dig @example.com 10.10.10.20 ptr:
This has the same reversed server/domain syntax error as option A. Furthermore, it queries for a PTR record, which is used for reverse DNS lookups (IP to name), not for finding a domain's mail servers.
D. dig @10.10.10.20 example.com ns:
This command correctly queries the specified server but asks for NS (Name Server) records. These records indicate which servers are authoritative for the domain, not which servers handle its email.
Reference:
ISC BIND 9 Administrator Reference Manual (dig): The official documentation for the dig command explains its syntax and record types.
Which of the following data structures is written in JSON?

A.
Option A
B.
Option B
C.
Option C
D.
Option D
Option C
Summary:
The question asks which of the provided options represents a data structure written in JSON (JavaScript Object Notation). JSON is a lightweight, text-based, language-independent data interchange format. It is built on two universal structures: a collection of key/value pairs (an object) and an ordered list of values (an array). The correct option must follow the strict syntax rules of JSON.
Correct Option:
C. Option C:
The provided data structure is a valid JSON object. It starts and ends with curly braces {}, denoting an object. It contains three key-value pairs where the keys ("name", "job", "floor") are enclosed in double quotes. The values are a mix of strings ("user1", "DevOps") and a number (3), which are valid JSON data types. The syntax, including the use of colons (:) to separate keys and values and commas (,) to separate pairs, is correct.
Incorrect Options:
A. Option A:
This option is incorrect because it is not valid JSON. While I cannot see the exact content of Option A, common reasons for invalidity include using single quotes for keys/strings instead of double quotes, having a trailing comma after the last key-value pair, or using incorrect structural brackets.
B. Option B:
This option is also incorrect due to a failure to adhere to JSON syntax standards. Potential errors could be the absence of quotes around keys, using an equals sign (=) instead of a colon (:) for assignment, or incorrect data type representation (e.g., an unquoted string where a number is expected).
D. Option D:
This option is invalid for similar structural reasons. It may represent a different data serialization format like YAML or may simply be a malformed version of a JavaScript object that does not meet the stricter requirements of the JSON specification.
Reference:
Official CompTIA Linux+ (XK0-005) Certification Exam Objectives: Understanding data formats like JSON falls under the broader scope of Objective 1.4: "Given a scenario, manage files and directories," which includes working with various file types and structures, and Objective 4.1: "Given a scenario, implement and configure automation," where JSON is commonly used for configuration files and data exchange in scripting and automation tools. The official JSON standard is defined at json.org.
User1 is a member of the accounting group. Members of this group need to be able to execute but not make changes to a script maintained by User2. The script should not be accessible to other users or groups. Which of the following will give proper access to the script?
A.
chown user2:accounting script.sh
chmod 750 script.sh
B.
chown user1:accounting script.sh
chmod 777 script.sh
C.
chown accounting:user1 script.sh
chmod 057 script.sh
D.
chown user2:accounting script.sh
chmod u+x script.sh
chown accounting:user1 script.sh
chmod 057 script.sh
Summary:
User2 maintains a script that the accounting group needs to run without modifying it. The script must be inaccessible to all other users (others). The solution requires two steps: first, setting the correct ownership so the group has inherent rights, and second, applying the precise permissions to allow the owner (User2) full control, the group to read and execute, and others to have no access.
Correct Option:
A. chown user2:accounting script.sh chmod 750 script.sh:
This is the correct sequence of commands.
chown user2:accounting script.sh sets the owner to user2 and the group to accounting.
chmod 750 script.sh sets the permissions numerically: 7 (rwx) for the owner (user2), 5 (r-x) for the group (accounting), and 0 (---) for others. This allows the group to read and execute the script but not write to (modify) it, and blocks all access for everyone else.
Incorrect Options:
B. chown user1:accounting script.sh chmod 777 script.sh:
This is incorrect for multiple reasons. First, it changes ownership to user1, taking it away from the maintainer, user2. Second, chmod 777 gives read, write, and execute permissions to everyone (owner, group, and others), which violates the security requirement that the script should not be accessible to other users or groups.
C. chown accounting:user1 script.sh chmod 057 script.sh:
This command has a syntactically incorrect chown (the format is user:group). Furthermore, the chmod 057 permission is illogical. It gives no permissions to the owner (0), read and execute to the group (5), and read, write, and execute to others (7). This is the opposite of the desired security model.
D. chown user2:accounting script.sh chmod u+x script.sh:
While the chown command is correct, the chmod command is insufficient. chmod u+x only adds the execute permission for the owner (user2). It does not explicitly grant the accounting group the ability to read and execute the script, nor does it explicitly remove permissions for "others."
Reference:
Official CompTIA Linux+ (XK0-005) Certification Exam Objectives: This scenario directly tests Objective 3.2: "Given a scenario, manage storage, files, and directories in a Linux environment," which includes managing file and directory permissions as well as ownership. Understanding numeric (octal) permission modes like 750 is a key skill for this objective.
A systems administrator needs to reconfigure a Linux server to allow persistent IPv4 packet forwarding. Which of the following commands is the correct way to accomplish this task?
A.
echo 1 > /proc/sys/net/ipv4/ipv_forward
B.
sysctl -w net.ipv4.ip_forward=1
C.
firewall-cmd --enable ipv4_forwarding
D.
systemctl start ipv4_forwarding
sysctl -w net.ipv4.ip_forward=1
Summary:
The task requires enabling IPv4 packet forwarding and making the change persistent across reboots. Packet forwarding is a kernel parameter controlled by the net.ipv4.ip_forward setting. The correct command must change this runtime parameter and ensure the change is written to the system's configuration so it survives a restart.
Correct Option:
B. sysctl -w net.ipv4.ip_forward=1:
This is the correct command. The sysctl command is used to modify kernel parameters at runtime. The -w flag writes the value. More importantly, to make it persistent, the administrator must also add net.ipv4.ip_forward = 1 to the /etc/sysctl.conf file or a file in /etc/sysctl.d/. The sysctl command itself is the standard tool for this task, and using it is the first step in the persistent configuration process.
Incorrect Options:
A. echo 1 > /proc/sys/net/ipv4/ip_forward:
This command will enable packet forwarding immediately by writing directly to the virtual file in /proc/sys/. However, this change is only temporary and will be lost after a system reboot. It does not accomplish the "persistent" requirement.
C. firewall-cmd --enable ipv4_forwarding:
This is not a valid firewall-cmd command. firewall-cmd is used to configure firewalld zones and rules, not to set core kernel networking parameters like IP forwarding. The correct flag for masquerading or forwarding in firewalld is different (--add-masquerade).
D. systemctl start ipv4_forwarding:
There is no systemd service called ipv4_forwarding. IP forwarding is a kernel parameter, not a service that can be started or stopped.
Reference:
Linux man-pages project (sysctl): The official documentation explains how to use sysctl to configure kernel parameters.
| Page 11 out of 40 Pages |
| 5678910111213141516 |
| XK0-005 Practice Test Home |
Real-World Scenario Mastery: Our XK0-005 practice exam don't just test definitions. They present you with the same complex, scenario-based problems you'll encounter on the actual exam.
Strategic Weakness Identification: Each practice session reveals exactly where you stand. Discover which domains need more attention, before CompTIA Linux+ Certification exam day arrives.
Confidence Through Familiarity: There's no substitute for knowing what to expect. When you've worked through our comprehensive XK0-005 practice exam questions pool covering all topics, the real exam feels like just another practice session.
Copyright © All Rights Reserved