Refer to the code snippet below:
Which three Considerations must the developer implement to make the method available within the Lightning web component? Choose 3 answer
A. The method must specify the (cacheable-trun) attribute
B. The method must specify the (continuation-true) attribute
C. The method must be annotaled with true Invocablemethod annolation
D. The method cannot mutate the result set retrieved from the database.
E. The method must be annotated with the AureEnabled annolation
Explanation:
The code snippet shows a Lightning Web Component (LWC) using @wire to call an Apex method named fetchOpportunities from the OpportunitySearch class. The @wire service is used to read Salesforce data reactively. For an Apex method to be compatible with the @wire service, it must adhere to specific criteria.
Why A is Correct: The (cacheable=true) attribute is a mandatory requirement for an Apex method to be called via the @wire service. This directive tells the framework that the method is a read-only operation, which allows the framework to cache the results and manage its reactivity efficiently. This is a key difference between @wire and imperative calls.
Why D is Correct: This is a direct consequence of using (cacheable=true). A cacheable method must be a read-only operation. It cannot perform Data Manipulation Language (DML) operations such as insert, update, delete, or undelete. It also cannot modify the data within the result set before returning it, as this would violate the principle of the method being idempotent (returning the same result for the same input every time).
Why E is Correct: The @AuraEnabled annotation is fundamental. It makes an Apex method accessible from any Lightning code, including both Aura Components and Lightning Web Components. Without this annotation, the client-side code cannot see or call the method.
Why B is Incorrect: The (continuation=true) attribute is used for making long-running callouts to external systems from Apex. It is part of the Continuation framework and is completely unrelated to the @wire service or querying database records for display in an LWC.
Why C is Incorrect: The @InvocableMethod annotation is used to expose an Apex method for use in Process Builder, Flow, or the REST API. While an Apex method can technically have both @AuraEnabled and @InvocableMethod annotations, @InvocableMethod is not required for the method to be available to a Lightning Web Component via @wire or imperative calls. The @AuraEnabled annotation is the one that is specifically required for this context.
Reference:
Salesforce Developer Documentation: Call Apex Methods
Specifically, the documentation states: "To use the @wire service to call an Apex method, annotate the Apex method with @AuraEnabled(cacheable=true)." It also clarifies that "Apex methods are read-only and don’t mutate data when called via the @wire service."
What are two benefits of using External IDs? Choose 2 answers
A. An External ID field can be used Co reference an ID from another external system.
B. An External ID can be a formula field to help create a unique key from two fields in Salesforce.
C. An External ID can be used with Salesforce Mobile to make external data visible.
D. An External ID is indexed and can improve the performance of SOQl quenes.
Explanation:
🟢 Correct Answer: A. An External ID field can be used to reference an ID from another external system.
This is a primary use case for External IDs. When you are integrating Salesforce with an external system, you often need to store the unique identifier from that system on the Salesforce record. By marking a field as an External ID, you can use its value to upsert records (update existing records or insert new ones) without having to know the Salesforce ID (the 15 or 18-character ID). This is crucial for data loading and integration scenarios where the external system's ID is the key to matching records.
🟢 Correct Answer: D. An External ID is indexed and can improve the performance of SOQL queries.
Salesforce automatically creates an index on fields marked as an External ID. An index is a data structure that improves the speed of data retrieval operations on a database table. Therefore, using an External ID in the WHERE clause of a SOQL query will be significantly faster than querying a non-indexed field. This is particularly important for large data sets, as it helps avoid timeouts and improves overall application performance. While other fields can be indexed, the External ID designation is a simple way to ensure a field is indexed for this purpose.
🔴 Incorrect Answer: B. An External ID can be a formula field to help create a unique key from two fields in Salesforce.
Reasoning: This is incorrect because a field designated as an External ID must be a writable field type, such as Text, Number, or Email. Formula fields are read-only and their values are calculated dynamically at runtime. As such, they cannot be used for matching or upserting records via an external key, which is a key function of an External ID. You cannot select the "External ID" checkbox for a formula field when you are creating or editing the field in Salesforce.
🔴 Incorrect Answer: C. An External ID can be used with Salesforce Mobile to make external data visible.
Reasoning: While you can use External IDs in some integration scenarios with Salesforce Mobile, the primary function of an External ID is for record matching and data synchronization, not for making external data visible. The Salesforce feature specifically designed to display data from external systems in real-time, within the Salesforce user interface, is Salesforce Connect. This feature uses External Objects and External Data Sources to present the data, which is a different concept from a field's External ID attribute.
Reference:
For further information on External IDs and their capabilities, you can refer to the official Salesforce documentation on "Custom Field Attributes" and "External IDs." This resource details the supported field types for External IDs and explains their purpose in data integration and performance.
Source: Salesforce Help: Custom Field Attributes
Which two sfdx commands can be used to add testing data to a Developer sandbox?
A. Forced: data:bulk:upsert
B. Forced: data: object :upsert
C. Forced: data: tree: upsert
D. Forced: data:async:upsert
Explanation:
A. force:data:bulk:upsert ✅
This command uses the Bulk API to insert or update large amounts of data into a sandbox.
It’s especially useful when working with big data volumes, like thousands of records.
C. force:data:tree:upsert ✅
This command lets you import data in a structured format, often using JSON files.
It’s great when you need to load related records (like Accounts with related Contacts) because it preserves relationships.
B. force:data:object:upsert ❌
There’s no such command in the Salesforce CLI (sfdx). Looks like a trick option.
D. force:data:async:upsert ❌
Also not a valid CLI command. Another distractor.
Reference:
Salesforce CLI Command Reference – force:data
✅ Final Answer: A and C
Universal Container(UC) wants to lower its shipping cost while making the shipping process more efficient. The Distribution Officer advises UC to implement global addresses to allow multiple Accounts to share a default pickup address. The Developer is tasked to create the supporting object and relationship for this business requirement and uses the Setup Menu to create a custom object called "Global Address". Which field should the developer ad to create the most efficient model that supports the business need?
A. Add a Master-Detail field on the Account object to the Global Address object
B. Add a Master-Detail field on the Global Address object to the Account object.
C. Add a Lookup field on the Account object to the Global Address object.
D. Add a Lookup field on the Global Address object to the Account object
Explanation:
To choose the right field, we need to understand the business need and how Salesforce relationships work. UC wants multiple Accounts to share one default pickup address, so one Global Address record could be linked to many Accounts. Let’s look at each option:
Option A: Master-Detail field on the Account object to the Global Address object
In a Master-Detail relationship, the child object (Account) would depend on the parent (Global Address). This means:
→ Each Account could only link to one Global Address (which is fine).
→ If the Global Address is deleted, all related Accounts would also be deleted because Master-Detail relationships enforce cascading deletion.
→ Deleting Accounts just because a shared address is removed doesn’t make sense for this business need. Accounts are independent records and should exist even if the Global Address is deleted.
→ This option is not efficient because it creates a strict dependency that could cause problems.
Option B: Master-Detail field on the Global Address object to the Account object
Here, Global Address would be the child, and Account would be the parent. This means:
→ Each Global Address could only link to one Account.
→ The business need is for multiple Accounts to share one Global Address, so this setup wouldn’t work. You’d need a separate Global Address record for every Account, which defeats the purpose of a shared default pickup address.
→ This option doesn’t support the requirement.
Option C: Lookup field on the Account object to the Global Address object
In a Lookup relationship, the Account object would have a field that points to a Global Address record. This means:
→ Each Account can link to one Global Address (the default pickup address).
→ One Global Address can be linked to many Accounts, which perfectly matches the requirement for multiple Accounts to share a default pickup address.
→ If a Global Address is deleted, the Accounts remain unaffected, with the lookup field becoming blank. This is safer and more logical for Accounts, which are independent records.
→ This is the most efficient model because it supports the business need (shared addresses) without unnecessary restrictions.
Option D: Lookup field on the Global Address object to the Account object
Here, the Global Address object would have a field pointing to an Account. This means:
→ Each Global Address could only link to one Account.
→ This doesn’t allow multiple Accounts to share one Global Address, which goes against the requirement.
→ You’d need multiple Global Address records for each Account, making the process less efficient.
Why Lookup Field on Account to Global Address?
The Lookup field on the Account object to the Global Address object (Option C) is the best choice because:
→ It allows many Accounts to reference the same Global Address record, meeting the need for a shared default pickup address.
→ It’s flexible and doesn’t impose strict rules like a Master-Detail relationship, so Accounts remain independent.
→ It’s efficient, requiring only one Global Address record for multiple Accounts, which reduces data duplication and supports UC’s goal of lowering shipping costs by streamlining address management.
Reference:
Salesforce Documentation: Relationship Types (explains Lookup vs. Master-Detail relationships).
Salesforce Documentation: Custom Objects (covers creating custom objects like Global Address).
Summary:
The developer should add a Lookup field on the Account object to the Global Address object (Option C). This setup lets multiple Accounts share one Global Address, keeps Accounts independent, and supports UC’s goal of efficient shipping with minimal complexity.
A developer has a Visualforce page and custom controller to save Account records. The developer wants to display any validation rule violation to the user. How can the developer make sure that validation rule violations are displayed?
A. Add cuatom controller attributes to display the message.
B. Include
C. Use a try/catch with a custom exception class.
D. Perform the DML using the Database.upsert() method.
Explanation:
Validation rules are enforced by the Salesforce platform at the database level. When a validation rule fails during a DML operation (like insert, update), Salesforce throws a system-defined DmlException. The standard behavior of Visualforce, when coupled with a custom controller, is to automatically handle these exceptions and display any validation rule errors (or other platform errors) through the
Let's break down why this is the correct answer and why the others are not:
Why B is Correct: The
Why A is Incorrect: While you could create a custom controller attribute (e.g., a String variable) and manually set an error message in a catch block, this is entirely unnecessary and error-prone. The platform already provides the error messages automatically. Manually doing this would require catching the exception, parsing the error message, and then redirecting it to the page, which is what
Why C is Incorrect: Using a try/catch block is part of the process, but it is not the complete solution on its own. If you simply catch the DmlException, the error is caught by your code but is never displayed to the user unless you explicitly take the error messages from the exception and add them to the page. The
Why D is Incorrect: The choice of DML method (Database.upsert(), insert, etc.) does not change how validation rule violations are handled. All DML operations will respect and enforce validation rules. While Database.upsert() allows for partial success processing in bulk operations, for a single record save operation on a Visualforce page, its behavior regarding error handling and display would be the same as a standard upsert statement. The key to displaying the error remains the presence of the
Reference:
Visualforce Component Reference: apex:pageMessages - This component displays all messages that were generated for all components on the current page.
The underlying mechanism is that when a DML exception occurs, the platform adds the error messages to the ApexPages message list. The
Universal Containers wants to ensure that all new leads created in the system have a valid email address. They have already created a validation rule to enforce this requirement, but want to add an additional layer of validation using automation. What would be the best solution for this requirement?
A. Submit a REST API Callojt with a JSON payload and validate the f elds on a third patty system
B. Use an Approval Process to enforce tne completion of a valid email address using an outbound message action.
C. Use a before-save Apex trigger on the Lead object to validate the email address and display an error message If it Is invalid
D. Use a custom Lightning web component to make a callout to validate the fields on a third party system.
Explanation:
C. Use a before-save Apex trigger on the Lead object to validate the email address and display an error message if it is invalid.
A before-save Apex trigger is the most effective solution for this requirement. It executes before the record is saved to the database, allowing you to validate data and prevent the record from being created or updated if the validation fails. Triggers can display a user-friendly error message directly on the page, which is a powerful way to provide immediate feedback to the user. This approach also works for all methods of record creation, including the user interface, data imports, and APIs, ensuring the validation is applied universally. This method is an excellent way to add an "additional layer of validation" to an existing validation rule.
❌ Why the Other Options Are Incorrect?
A. Submit a REST API Callout with a JSON payload and validate the fields on a third-party system.
While you could perform an API callout from Apex, doing so in a before-save trigger is not allowed. Callouts must be made from asynchronous Apex (future methods or queueable Apex) or after-save triggers, and they don't block the DML operation. You can't use an API callout to prevent a save from happening.
B. Use an Approval Process to enforce the completion of a valid email address using an outbound message action.
An Approval Process is designed to require a record to be approved before it can be finalized. It's not a direct data validation tool that prevents a record from being saved. An Outbound Message is an action that sends data to an external system, but it cannot be used to display an error message on the Salesforce record page or prevent the record from being saved.
D. Use a custom Lightning web component to make a callout to validate the fields on a third-party system.
This solution is not comprehensive enough. A Lightning Web Component (LWC) would only enforce the validation when a user is creating a lead via that specific component. It would not apply if a lead is created through a different method, such as a standard page layout, a data import, or an API call. For universal validation, a trigger is a better choice.
Which Lightning code segment should be written to declare dependencies on a Lightning component, c:accountList, that is used in a Visualforce page?

A. Option A
B. Option B
C. Option C
D. Option D
Explanation:
A. ✅
This is the correct way:
Uses
Extends ltng:outApp (necessary to support Lightning Out).
Declares the dependency properly.
✅ Correct Answer.
B. ❌
You cannot extend ltng:outApp from a component. That’s only valid for applications.
❌ Invalid.
C. ❌
Same issue: a component can’t directly be declared as a dependency provider for Visualforce embedding.
❌ Invalid.
D. ❌
It’s missing extends="ltng:outApp", which is required for Lightning Out with Visualforce.
❌ Incomplete.
Reference:
Salesforce Docs – Use Lightning Components in Visualforce Pages
✅ Final Answer: A. Option A
Cloud kicks has a multi-screen flow that its call center agents use when handling inbound service desk calls. At one of the steps in the flow, the agents should be presented with a list of order numbers and dates that are retrieved from an external order management system in real time and displayed on the screen. What should a developer use to satisfy this requirement?
A. An Apex controller
B. An Apex REST class
C. An outbound message
D. An invocable method
Explanation:
To satisfy this requirement, a developer needs to retrieve data from an external system in real time and display it in a multi-screen flow. A flow screen component is the primary tool for displaying a user interface within a flow. This component needs a mechanism to get the data from the external system. An Apex controller is the standard way to handle complex logic, including making callouts to external web services, and passing that data back to a UI component. The flow would call the screen component, which in turn would use the Apex controller to make the real-time callout to the external order management system and retrieve the list of order numbers and dates to display on the screen.
Why the Other Options Are Incorrect?
B. An Apex REST class: An Apex REST class is used to expose Salesforce data to an external application, acting as a web service. This is the opposite of what's needed here, as the requirement is to get data from an external system, not send it to one.
C. An outbound message: An outbound message is a workflow action that sends a message to an external system. Like the Apex REST class, this is used for sending data out of Salesforce, not for receiving it in real time to display on a screen.
D. An invocable method: An invocable method can be called from a flow, but it's used for performing specific business logic or actions. While an invocable method could theoretically make a callout, the standard pattern for a screen component that needs to retrieve and display data is to use a dedicated Apex controller. An invocable method is not designed for the UI data binding that a screen component requires to display a list.
If apex code executes inside the execute() method of an Apex class when implementing the Batchable interface, which statement are true regarding governor limits? Choose 2 answers
A. The Apex governor limits might be higher due to the asynchronous nature of the transaction.
B. The apex governor limits are reset for each iteration of the execute() method.
C. The Apex governor limits are relaxed while calling the constructor of the Apex class.
D. The Apex governor limits cannot be exceeded due to the asynchronous nature of the transaction,
Explanation:
Key Concept:
Batch Apex runs asynchronously. Each batch chunk of records runs in its own separate transaction.
This means governor limits are reset for each execution of the execute() method.
Governor limits are not relaxed just because it’s asynchronous. You can still hit limits if you’re not careful.
Options Breakdown:
A. The Apex governor limits might be higher due to the asynchronous nature of the transaction. ❌
Limits are the same as other asynchronous contexts (e.g., @future). They’re not “higher” than normal asynchronous limits.
❌ Incorrect.
B. The Apex governor limits are reset for each iteration of the execute() method. ✅
Yes! Each batch execution gets its own governor limits because it’s its own transaction.
✅ Correct.
C. The Apex governor limits are relaxed while calling the constructor of the Apex class. ❌
No, constructors don’t get relaxed limits. Normal limits still apply.
❌ Incorrect.
D. The Apex governor limits cannot be exceeded due to the asynchronous nature of the transaction. ❌
You can definitely exceed them (e.g., too many SOQL queries, too many DMLs) even in Batch Apex.
❌ Incorrect.
✅ Correct Answers:
B
…and also A? Wait — let’s be extra careful here.
Actually, Salesforce does give slightly higher limits for asynchronous operations (like Batch Apex and Queueable). For example:
➡️ SOQL query rows limit: 50,000 in synchronous vs. 50,000 (but per batch execution).
➡️ Future, Batch, Queueable sometimes allow more total queries and DML statements compared to synchronous.
So A is also correct: asynchronous contexts can have higher limits compared to synchronous execution.
A developer created these three Rollup Summary fields in the custom object, Project_ct,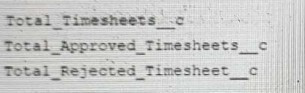
The developer is asked to create a new field that shows the ratio between rejected and approved timesheets for a given project.
Which should the developer use to Implement the business requirement in order to minimize maintenance overhead?
A. Record-triggered Flow
B. Formula field
C. Apex Trigger
D. Process Builder
Explanation:
The developer needs a field that automatically calculates the ratio using the existing Rollup Summary fields (total timesheets, approved timesheets, and rejected timesheets). Let’s look at each option to see which one is easiest to maintain:
Option A: Record-triggered Flow
A record-triggered Flow can update fields based on certain conditions or changes. To create the ratio, the developer would need to set up a Flow that checks the approved and rejected timesheet counts and calculates the ratio whenever a timesheet changes.
→ This requires building and maintaining a Flow, which involves extra steps like setting up logic and testing it whenever the business needs change.
→ It’s more work to keep updated compared to a simpler solution.
🟢 Option B: Formula field
A formula field lets you create a calculation using existing fields, like the Rollup Summary fields already on Project_ct. The developer can write a formula to divide the rejected timesheets by the approved timesheets (e.g., Rejected_Timesheets__c / Approved_Timesheets__c).
→ Since the Rollup Summary fields already update automatically, the formula field will too, without needing extra maintenance.
→ It’s easy to set up in Salesforce’s setup menu and doesn’t require ongoing updates unless the formula itself changes, which is rare.
→ This is the simplest and lowest-maintenance option.
Option C: Apex Trigger
An Apex Trigger is a piece of custom code that runs when a record is created or updated. The developer would need to write code to calculate the ratio and update a field whenever timesheet data changes.
→ This requires coding skills, testing, and ongoing maintenance if the business rules change.
→ It’s more complex and time-consuming than using built-in features like a formula field.
Option D: Process Builder
Process Builder can automate actions based on record changes, similar to a Flow. The developer would need to create a process to calculate and update the ratio field when timesheet counts change.
→ Like a Flow, this involves building and maintaining a process, which adds extra work compared to a formula field.
→ Salesforce is moving away from Process Builder, so it’s not the best long-term choice.
Why Formula Field?
A formula field is the best choice because:
→ It uses the existing Rollup Summary fields, which already track the numbers, so no extra updates are needed.
→ It calculates the ratio automatically every time you view the Project_ct record, without requiring any maintenance after it’s set up.
→ It’s built into Salesforce, so there’s no need to write code or manage complex workflows, keeping the effort low.
Example Idea (No Code):
Imagine the Rollup Summary fields show 10 approved timesheets and 2 rejected timesheets. A formula field could simply divide 2 by 10 to get a ratio of 0.2. This happens automatically whenever the numbers update, and you don’t have to do anything extra!
Reference:
Salesforce Documentation: Formula Fields (explains how to create and use formula fields).
Salesforce Documentation: Rollup Summary Fields (covers how they work with custom objects).
Summary:
The developer should use a formula field (🟢 Option B) to create the ratio between rejected and approved timesheets. It’s the easiest to set up and maintain, using the existing Rollup Summary fields to do the work automatically.
A developer must create a DrawList class that provides capabilities defined in the Sortable and Drawable interfaces. public interface Sortable { void sort(); } public interface Drawable { void draw(); } Which is the correct implementation?
A. Public class DrawList implements Sortable, Implements Drawable { public void sort() { /*implementation*/} public void draw() { /*implementation*/} ]
B. Public class DrawList extends Sortable, Drawable { public void sort() { /*implementation*/} public void draw() { /*implementation*/} }
C. Public class DrawList implements Sortable, Drawable { public void sort() { /*implementation*/} public void draw() { /*implementation*/} }
D. Public class DrawList extends Sortable, extends Sortable, extends Drawable { public void sort() { /*implementation*/ } public void draw() { /* implementation */}
Explanation:
This question tests the fundamental Apex (and Java) syntax for implementing interfaces. The key distinction is between the implements keyword (for interfaces) and the extends keyword (for inheritance from a parent class).
Why C is Correct: The syntax for implementing multiple interfaces is to use the implements keyword once, followed by a comma-separated list of the interface names. The class must then provide a concrete implementation (a method body) for every method defined in all the interfaces it implements. Option C follows this syntax perfectly.
Why A is Incorrect: This option incorrectly uses the implements keyword multiple times. The correct syntax only uses it once. The word Implements is also incorrectly capitalized.
Why B is Incorrect: This option incorrectly uses the extends keyword. extends is used for inheriting from a single parent class. Since Sortable and Drawable are interfaces, not classes, you cannot use extends to implement them. Apex does not support multiple inheritance for classes (extends can only have one class name), but it does support implementing multiple interfaces.
Why D is Incorrect: This option is syntactically invalid for multiple reasons. It redundantly and incorrectly uses the extends keyword multiple times for the same interface (Sortable). Like option B, it uses extends for interfaces, which is wrong. The syntax is completely malformed.
Reference:
Apex Developer Guide: Using Interfaces
➡️ "A class implements an interface by using the implements keyword."
➡️ "A class can implement multiple interfaces but can only extend one existing class."
➡️ "When a class implements an interface, it must provide an implementation for all methods declared in the interface."
Universal Containers needs to create a custom user interface component that allows users to enter information about their accounts. The component should be able to validate the user input before saving the information to the database. What is the best technology to create this component?
A. Flow
B. Lightning Web Components
C. Visualforce
D. VUE JavaScript framework
Explanation:
Lightning Web Components is Salesforce's modern, standards-based UI framework for building components on the Lightning Platform. It is the recommended approach for creating custom UI on Salesforce today due to its performance, reusability, and use of modern web standards like HTML, CSS, and JavaScript.
Validation in LWC is straightforward and can be implemented in two ways:
➡️ Built-in Validation: Base components like
➡️ Custom Validation: For more complex business logic, you can write JavaScript to perform custom validation checks. You can use methods like checkValidity() and reportValidity() on the input fields to display user-friendly error messages before the data is processed or saved.
Why the Other Options Are Not the Best Choice?
A. Flow: While Flow can be used to build user interfaces through Screen Flows, it is a declarative tool for automating business processes. It's great for building multi-step wizards or simple forms, but it is not the ideal technology for creating a highly customized, standalone UI component. Flow's validation capabilities are more limited compared to LWC.
C. Visualforce: Visualforce is an older, tag-based framework. While it is still supported and used in many legacy applications, it is generally considered outdated. Salesforce recommends using Lightning Web Components for all new development because they are more performant and align with the modern web development ecosystem.
D. VUE JavaScript framework: Vue is an external, general-purpose JavaScript framework. While it's possible to build a Vue application and integrate it with Salesforce, it's not a native Salesforce technology. This approach would require more effort to set up, secure, and maintain, as you would have to manage the connection to the Salesforce platform, handle authentication, and integrate with the Salesforce Lightning Design System (SLDS) manually. It's not a native component-building solution.
| Page 2 out of 20 Pages |
| Previous |