An Architect needs to document the data architecture for a multi-system, enterprise Salesforce implementation. Which two key artifacts should the Architect use? (Choose two.)
A. User stories
B. Data model
C. Integration specification
D. Non-functional requirements
Explanation:
For a multi-system Salesforce implementation, a data architect must produce artifacts that clearly represent how data is structured and how it flows between systems. A data model shows the entity relationships, attributes, and data ownership in Salesforce. An integration specification documents how Salesforce interacts with other systems, including data formats, transformation rules, and error handling. Together, these artifacts provide a comprehensive picture of how customer and business data moves through the enterprise landscape.
Why not the others?
A. User stories:
User stories are valuable in Agile projects to capture business requirements from an end-user perspective. However, they focus on functionality and business outcomes, not technical documentation of data structures or integration flows. While user stories may inform design decisions, they are not formal artifacts for documenting enterprise data architecture.
D. Non-functional requirements:
These requirements cover aspects such as scalability, performance, availability, and security. While important, they describe system qualities, not how data is structured or integrated. Non-functional requirements inform design constraints but do not serve as the architectural documentation an architect needs to illustrate data models and integration specifications.
Reference:
Salesforce Architect Guide: Data Modeling
Salesforce Integration Patterns and Practices
Get Cloudy Consulting uses an invoicing system that has specific requirements. One requirement is that attachments associated with the Invoice_c custom object be classified by Types (i.e., ""Purchase Order"", ""Receipt"", etc.) so that reporting can be performed on invoices showing the number of attachments grouped by Type. What should an Architect do to categorize the attachments to fulfill these requirements?
A. Add additional options to the standard ContentType picklist field for the Attachment object.
B. Add a ContentType picklist field to the Attachment layout and create additional picklist options
C. Create a custom picklist field for the Type on the standard Attachment object with the values
D. Create a custom object related to the Invoice object with a picklist field for the Type.
Explanation:
The Attachment object is a legacy object that does not support custom fields or custom picklists for categorization. To enable reporting by attachment type, the best approach is to create a custom object (e.g., Invoice Attachment) that relates to the Invoice object. This object can store references to the actual file (via ContentDocument or external reference) and include a custom picklist field for categorization, which makes reporting and grouping possible.
Why not the others?
A. Add additional options to the standard ContentType picklist field:
The ContentType field is not customizable. It is automatically populated by Salesforce based on the file type (e.g., PDF, JPG). You cannot add custom values such as “Purchase Order” or “Receipt,” so this option does not fulfill the business requirement.
B. Add a ContentType picklist field to the Attachment layout:
The Attachment object does not allow adding custom fields directly, including picklists. Layout customization is limited. Even if possible, the field would not integrate with Salesforce reporting in the way the requirement demands. This option is not supported in practice.
C. Create a custom picklist field for the Type on the Attachment object:
The Attachment object is system-defined and cannot be extended with custom fields. This limitation makes it impossible to track type values directly on Attachment records. Any reporting requirement would fail due to the inability to customize the object itself.
Reference:
Salesforce Help: Considerations for Attachments and Files
Salesforce Developer Guide: Working with Files and ContentDocumentLink
Universal Containers (CU) is in the process of implementing an enterprise data warehouse (EDW). UC needs to extract 100 million records from Salesforce for migration to the EDW. What data extraction strategy should a data architect use for maximum performance?
A. Install a third-party AppExchange tool.
B. Call the REST API in successive queries.
C. Utilize PK Chunking with the Bulk API.
D. Use the Bulk API in parallel mode.
Explanation:
When extracting very large datasets (hundreds of millions of records), the Bulk API with PK Chunking is the recommended approach. PK Chunking automatically breaks the extraction into manageable chunks based on the record’s primary key (Id), which reduces the chance of query timeouts and improves overall throughput. It allows efficient parallel processing while keeping each batch within governor limits. For 100 million records, this is the most scalable and proven approach for Salesforce data extraction.
🔴 Why not the others?
A. Install a third-party AppExchange tool:
Third-party tools can simplify extraction but ultimately use Salesforce APIs under the hood. They add overhead, licensing cost, and are not guaranteed to optimize for extreme high-volume exports. For a defined migration of 100 million records, direct use of Bulk API with PK Chunking is the most controlled and performant strategy.
B. Call the REST API in successive queries:
REST API is synchronous and optimized for small to medium datasets. It has strict limits on the number of records per query and would timeout or hit daily API request limits when handling 100 million records. This approach is impractical for very large-scale data migrations.
D. Use the Bulk API in parallel mode:
Bulk API in parallel mode improves throughput but without PK Chunking it risks uneven batch distribution, timeouts, or excessive failures. When datasets exceed tens of millions, PK Chunking ensures controlled segmentation. Parallel mode alone may increase the chance of hitting record lock or performance issues during extraction.
Reference:
Salesforce Help: Use PK Chunking to Extract Data with Bulk API
Salesforce Developer Guide: Bulk API 2.0 Best Practices
Northern Trail Outfitters (NTO) has a variety of customers that include householder, businesses, and individuals.
The following conditions exist within its system:
1. NTO has a total of five million customers.
2. Duplicate records exist, which is replicated across many systems, including Salesforce.
3. Given these conditions, there is a lack of consistent presentation and clear identification of a customer record.
Which three option should a data architect perform to resolve the issues with the customer data?
A. Create a unique global customer ID for each customer and store that in all system for referential identity.
B. Use Salesforce CDC to sync customer data cross all systems to keep customer record in sync.
C. Invest in data duplicate tool to de-dupe and merge duplicate records across all systems.
D. Duplicate customer records across the system and provide a two-way sync of data between the systems.
E. Create a customer master database external to Salesforce as a system of truth and sync the customer data with all systems
Explanation:
This question addresses the core concepts of Master Data Management (MDM) and strategies for achieving a "single source of truth" for customer data across a fragmented ecosystem.
✅ Why A is Correct:
The fundamental first step in resolving data silos and duplicates is to establish a single, unique identifier (a global customer ID or Golden Record ID) for each distinct customer entity. This ID acts as a primary key that can be stored in all downstream systems (including Salesforce) to provide referential integrity. This allows systems to accurately link their records back to the master record, solving the "clear identification" problem.
✅ Why C is Correct:
Before a clean master database can be established, the existing duplicate data within each system (including Salesforce) must be cleansed. A dedicated data deduplication tool is necessary to identify, merge, and purge duplicate records at scale across all systems. This is a critical cleansing step that cannot be skipped.
✅ Why E is Correct:
The ultimate goal of an MDM initiative is to create a master database that serves as the authoritative system of truth for customer data. All other systems, including Salesforce, become "spoke" systems that consume this clean, mastered data. This architecture directly resolves the issues of inconsistent presentation and duplication by ensuring every system syncs from one central, clean source.
❌ Why B is Incorrect (Use Salesforce CDC):
Change Data Capture (CDC) is a tool for streaming changes out of Salesforce. The problem states that duplicates exist across many systems, and Salesforce is just one of them. Using CDC would only push potentially dirty data from Salesforce to other systems, exacerbating the problem. It does nothing to clean the data or create a master source.
❌ Why D is Incorrect (Duplicate records and two-way sync):
This is the exact opposite of a correct solution. Duplicating records and creating a complex web of two-way syncs would guarantee data inconsistency, create endless sync conflicts, and make the duplication problem exponentially worse. Data should flow from a single master out to other systems, not be synced bi-directionally between peers.
Reference:
This solution outlines a standard MDM implementation pattern:
1) Cleanse existing data (C)
2) Establish a unique identity framework (A)
3) Create a central master system and hub-and-spoke integration model (E)
As part of addressing general data protection regulation (GDPR) requirements, UC plans to implement a data classification policy for all its internal systems that stores customer information including salesforce. What should a data architect recommend so that UC can easily classify consumer information maintained in salesforce under both standard and custom objects?
A. Use App Exchange products to classify fields based on policy.
B. Use data classification metadata fields available in field definition.
C. Create a custom picklist field to capture classification of information on customer.
D. Build reports for customer information and validate.
Explanation:
This question tests knowledge of native Salesforce features built specifically for data governance and compliance, such as GDPR.
Why B is Correct: Salesforce provides native, built-in field-level metadata for data classification. In Setup, an administrator can edit any field (standard or custom) and set its Classification (e.g., Public, Internal, Confidential, Restricted, etc.). This is the standard, scalable, and maintainable way to classify data because:
✔️ It is applied directly to the schema definition.
✔️ It is available for reporting and can be used by other tools (like Field Audit Trail) and APIs.
✔️ It doesn't consume custom fields or storage.
This feature was enhanced specifically to help organizations comply with regulations like GDPR.
Why A is Incorrect (AppExchange products): While AppExchange products might offer advanced features on top of classification, the native functionality is sufficient and recommended for the base requirement of "easily classify consumer information." Recommending a third-party paid tool before using a robust, free, native feature is not the best architectural practice.
Why C is Incorrect (Custom picklist field): This would create a massive maintenance burden. You would have to add this custom field to every object that contains customer information and then manually populate it for every field. This is error-prone, difficult to maintain, and unnecessary since the platform already provides a dedicated metadata property for this purpose.
Why D is Incorrect (Build reports): Reports can analyze data values but cannot easily classify the schema itself. This is a manual, reactive process and does not provide a systematic way to tag and manage the classification of data fields across the entire org. It does not fulfill the requirement to "classify" the information for policy purposes.
Reference: The "Field-Level Data Classification" feature is a key tool in the Salesforce data governance toolkit. It is explicitly mentioned in the context of preparing for GDPR compliance.
Cloud Kicks needs to purge detailed transactional records from Salesforce. The data should be aggregated at a summary level and available in Salesforce. What are two automated approaches to fulfill this goal? (Choose two.)
A. Third-party Integration Tool (ETL)
B. Schedulable Batch Apex
C. Third-party Business Intelligence system
D. Apex Triggers
Explanation:
This question evaluates the understanding of data archiving and aggregation strategies within the constraints of the Salesforce platform, focusing on automation and large data volumes.
Why A is Correct (Third-party Integration Tool - ETL): An Extract, Transform, Load (ETL) tool (like MuleSoft, Informatica Cloud, etc.) is a perfect fit for this automated process. It can be scheduled to:
⇒ Extract: Read the detailed transactional records from Salesforce.
⇒ Transform: Aggregate the data to the required summary level (e.g., calculate sums, averages, counts).
⇒ Load: Insert the new summary records into a custom summary object in Salesforce.
⇒ Purge: Delete the original detailed records from Salesforce.
This offloads the processing from the Salesforce platform.
Why B is Correct (Schedulable Batch Apex): For an automated solution built entirely on the Salesforce platform, a Schedulable Batch Apex job is the standard and most robust method.
⇒ Batchable: It can process the large number of transactional records in batched chunks, respecting governor limits.
⇒ Schedulable: It can be scheduled to run automatically on a regular basis (e.g., nightly, weekly).
The logic within the batch job would perform the aggregation, create the summary records, and then delete the processed detail records.
Why C is Incorrect (Third-party Business Intelligence system): A BI system (like Tableau, Einstein Analytics) is designed for querying and analyzing data. It is not designed for writing data back to Salesforce or for performing destructive operations like deleting records from the Salesforce database. It is the wrong tool for this job.
Why D is Incorrect (Apex Triggers): Triggers are event-driven and fire on a record-by-record basis in response to DML events (insert, update, delete). They are utterly unsuited for this batch archiving process. A trigger would attempt to fire for every single record being purged, would be unable to perform the aggregate calculations across the entire data set, and would almost certainly hit governor limits.
Reference: The key distinction is between tools for scheduled batch processing (ETL, Batch Apex) and tools for real-time transaction processing (Triggers) or analysis (BI systems). Data archiving and aggregation is a classic batch processing task.
Cloud Kicks has the following requirements:
- Data needs to be sent from Salesforce to an external system to generate invoices from their Order Management System (OMS).
- A Salesforce administrator must be able to customize which fields will be sent to the external system without changing code.
What are two approaches for fulfilling these requirements? (Choose two.)
A. A set (sobjectfieldset) to determine which fields to send in an HTTP callout.
B. An Outbound Message to determine which fields to send to the OMS.
C. A Field Set that determines which fields to send in an HTTP callout.
D. Enable the field -level security permissions for the fields to send.
Explanation:
Cloud Kicks needs a solution to send data from Salesforce to an external Order Management System (OMS) for invoice generation, with the ability for administrators to customize the fields sent without modifying code. Let’s evaluate each option:
Option A: A set to determine which fields to send in an HTTP callout
Salesforce does not have a native feature called a “set” for configuring fields in HTTP callouts. This option is likely referring to a generic or custom metadata solution, but it is not a standard Salesforce construct. Without a specific feature like Field Sets or Outbound Messages, this approach is not viable for administrators to customize fields without code changes.
Option B: An Outbound Message to determine which fields to send to the OMS
Outbound Messages are a workflow action in Salesforce that allows administrators to send SOAP-based messages to external systems, including selected object fields, without writing code. Administrators can configure Outbound Messages through the Salesforce UI (via Workflow Rules or Flow) and choose which fields to include in the message payload. This meets the requirement for a no-code solution that allows field customization for integration with the OMS.
Option C: A Field Set that determines which fields to send in an HTTP callout
Field Sets are a Salesforce feature that allows administrators to define a collection of fields on an object that can be referenced in code (e.g., Apex or Flow) or Visualforce pages. Developers can write an HTTP callout (e.g., using Apex) that dynamically retrieves fields from a Field Set, enabling administrators to modify the fields sent to the OMS via the Salesforce UI without code changes. This is a flexible, no-code administration solution that meets the requirements.
Option D: Enable the field-level security permissions for the fields to send
Field-level security (FLS) controls which fields users can view or edit within Salesforce, but it does not provide a mechanism for selecting fields to send to an external system via integration. FLS is unrelated to the requirement of customizing fields for an external system without code.
Why B and C are Optimal:
Outbound Messages (B) allow administrators to configure field selections for SOAP-based integrations without coding, directly addressing the requirement for no-code customization. Field Sets (C) enable administrators to define and modify fields for HTTP callouts, providing flexibility in a REST-based integration scenario when paired with minimal Apex or Flow logic. Both approaches empower administrators to customize fields sent to the OMS without requiring developer intervention.
References:
Salesforce Documentation: Outbound Messages
Salesforce Documentation: Field Sets
Salesforce Architect Guide: Integration Patterns
Universal Containers (UC) is in the process of migrating lagacy inventory data from an enterprise resources planning (ERP) system into Sales Cloud with the following requirements:
Legacy inventory data will be stored in a custom child objects called Inventory_c.
Inventory data should be related to the standard Account object.
The Inventory_c object should Inhent the same sharing rules as the Account object.
Anytime an Account record is deleted in Salesforce, the related Inventory_c record(s) should be deleted as well.
What type of relationship field should a data architect recommend in this scenario?
A. Master-detail relationship filed on Account, related to Inventory_c
B. Master-detail relationship filed on Inventory_c, related to Account
C. Indirect lookup relationship field on Account, related to Inventory_c
D. Lookup relationship fields on Inventory related to Account
Explanation:
The requirements specify that the Inventory__c object is a child of the Account object, must inherit Account’s sharing rules, and related Inventory__c records should be deleted when the parent Account is deleted. Let’s analyze each option to determine the appropriate relationship field:
🔴 Option A: Master-detail relationship field on Account, related to Inventory__c
This option is incorrectly phrased, as a master-detail relationship field is defined on the child object (Inventory__c), not the parent (Account). The relationship is created on the child object to reference the parent, so this option is not valid.
🟢 Option B: Master-detail relationship field on Inventory__c, related to Account
This is the correct approach. A master-detail relationship on Inventory__c, with Account as the parent, meets all requirements:
➡️ Child object: Inventory__c is a custom object storing inventory data, related to Account.
➡️ Sharing rules: In a master-detail relationship, the child object (Inventory__c) inherits the sharing rules and security settings of the parent (Account), ensuring consistent access control.
➡️ Cascade delete: When a master record (Account) is deleted, all related detail records (Inventory__c) are automatically deleted, satisfying the requirement for related records to be deleted.
This makes the master-detail relationship ideal for this scenario.
🔴 Option C: Indirect lookup relationship field on Account, related to Inventory__c
An indirect lookup relationship is used in scenarios involving external objects (e.g., via Salesforce Connect) or specific features like the Partner object, where the relationship is based on an external ID. This is not applicable here, as Inventory__c is a custom object within Salesforce, not an external object, and the option is incorrectly phrased (the field would be on Inventory__c, not Account).
🔴 Option D: Lookup relationship field on Inventory__c related to Account
A lookup relationship on Inventory__c to Account would allow relating inventory data to Accounts, but it does not meet two key requirements:
➡️ Sharing rules: Lookup relationships do not automatically inherit the parent’s sharing rules; the child object has its own sharing model.
➡️ Cascade delete: Deleting an Account does not automatically delete related Inventory__c records in a lookup relationship unless custom logic (e.g., a trigger) is implemented.
This makes a lookup relationship insufficient for the requirements.
🟢 Why Option B is Optimal:
A master-detail relationship on Inventory__c, with Account as the master, satisfies all requirements: it establishes Inventory__c as a child of Account, ensures Inventory__c inherits Account’s sharing rules, and enforces cascade deletion of Inventory__c records when an Account is deleted. This aligns with Salesforce’s data modeling best practices for tightly coupled, dependent relationships.
References:
Salesforce Documentation: Relationships Among Objects
Salesforce Architect Guide: Data Modeling
Salesforce Help: Master-Detail Relationships
Cloud Kicks is launching a Partner Community, which will allow users to register shipment requests that are then processed by Cloud Kicks employees. Shipment requests contain header information, and then a list of no more than 5 items being shipped. First, Cloud Kicks will introduce its community to 6,000 customers in North America, and then to 24,000 customers worldwide within the next two years. Cloud Kicks expects 12 shipment requests per week per customer, on average, and wants customers to be able to view up to three years of shipment requests and use Salesforce reports. What is the recommended solution for the Cloud Kicks Data Architect to address the requirements?
A. Create an external custom object to track shipment requests and a child external object to track shipment items. External objects are stored off-platform in Heroku’s Postgres database.
B. Create an external custom object to track shipment requests with five lookup custom fields for each item being shipped. External objects are stored off-platform in Heroku’s Postgres database.
C. Create a custom object to track shipment requests and a child custom object to track shipment items. Implement an archiving process that moves data off-platform after three years.
D. Create a custom object to track shipment requests with five lookup custom fields for each item being shipped Implement an archiving process that moves data off-platform a three years.
Explanation:
Option C is the most suitable and scalable solution. Let's break down the reasons:
✔️ Custom Objects for Active Data: The prompt specifies that customers need to view and report on up to three years of data. Using standard Salesforce custom objects is the best way to handle this because it provides native functionality for reporting, list views, and a user-friendly interface.
✔️ Parent-Child Relationship: The requirement for "header information" and a "list of no more than 5 items" is a classic parent-child data model. A custom Shipment object (parent) and a custom Shipment Item object (child) is the most flexible and scalable way to represent this. It's much better than a fixed number of lookup fields (as in option D) because it can easily accommodate changes in the number of items and is the standard relational database approach.
✔️ Archiving Process: The volume is significant. Let's calculate: 24,000 customers * 12 shipments/week * 52 weeks/year * 3 years = 44,928,000 shipments. This doesn't even include the line items (up to 5 per shipment). This volume of data over three years will rapidly consume Salesforce storage. Implementing an archiving strategy to move data off-platform after three years is essential for managing data volume and maintaining platform performance.
❌ Option A and B are incorrect. While using external objects can be a way to handle large data volumes, they are not ideal for data that needs to be actively reported on and viewed by users in a native Salesforce context. External objects retrieve data from outside sources in real-time, which can be slow for reporting and may not provide the full range of Salesforce reporting features. The prompt also states that the data needs to be available for up to three years, making the custom object + archiving approach more appropriate.
❌ Option D is incorrect. Using five lookup fields for the items is an example of a denormalized data model. This is inefficient and inflexible. What if a shipment suddenly needs 6 items? What if it only has 1? This approach wastes fields and doesn't scale well.
References:
⇒ Salesforce Data Modeling Best Practices: Trailhead modules on data modeling and architecture emphasize the use of relational models (parent-child objects) for structured data.
⇒ Large Data Volumes (LDV) Strategies: Salesforce documentation on LDV consistently highlights data archiving as a key strategy for managing a growing database.
⇒ Salesforce Connect (External Objects): Salesforce documentation outlines the use cases for external objects, which are typically for accessing data that is stored externally and doesn't need to be brought into Salesforce for transactional purposes.
Cloud Kicks has the following requirements:
• Their Shipment custom object must always relate to a Product, a Sender, and a Receiver (all separate custom objects).
• If a Shipment is currently associated with a Product, Sender, or Receiver, deletion of those records should not be allowed.
• Each custom object must have separate sharing models.
What should an Architect do to fulfill these requirements?
A. Associate the Shipment to each parent record by using a VLOOKUP formula field.
B. Create a required Lookup relationship to each of the three parent records.
C. Create a Master-Detail relationship to each of the three parent records.
D. Create two Master-Detail and one Lookup relationship to the parent records.
Explanation:
Option B correctly addresses all three requirements.
✔️ "Must always relate to...": A required lookup field ensures that a value must be entered before the record can be saved.
✔️ "Deletion of those records should not be allowed": When creating a Lookup relationship, you have the option to set the "What to do when the lookup record is deleted?" behavior. The default is "Don't allow deletion of the lookup record that's part of a lookup relationship." This setting prevents the deletion of the parent record (Product, Sender, Receiver) if it is referenced by a child record (Shipment).
✔️ "Each custom object must have separate sharing models": This is the key reason why a Lookup relationship is superior to a Master-Detail relationship here. In a Master-Detail relationship, the child record inherits sharing rules and ownership from the parent. Since each object needs a separate sharing model, a Lookup relationship is the only choice.
❌ Option A is incorrect. A VLOOKUP formula field is used to display data from a related record; it does not create a direct relationship between objects and, therefore, cannot enforce a mandatory connection or prevent deletion.
❌ Option C and D are incorrect. Master-Detail relationships are designed for tight coupling where the child record is a true "detail" of the parent. The child record's sharing and security are completely controlled by the parent. The requirement for separate sharing models for each object immediately eliminates any Master-Detail option.
References:
➡️ Salesforce Relationship Fields: Salesforce documentation and Trailhead modules (e.g., "Data Modeling" on Trailhead) provide detailed explanations of Lookup and Master-Detail relationships. They clearly outline the key differences, including the impact on record deletion and sharing.
➡️ Data Architect Certification Guide: This is a fundamental concept for the exam. Understanding the implications of different relationship types on data integrity, sharing, and security is a core competency.
Universal Containers has received complaints that customers are being called by multiple Sales Reps where the second Sales Rep that calls is unaware of the previous call by their coworker. What is a data quality problem that could cause this?
A. Missing phone number on the Contact record.
B. Customer phone number has changed on the Contact record.
C. Duplicate Contact records exist in the system.
D. Duplicate Activity records on a Contact.
Explanation:
Correct Answer: C. Duplicate Contact records exist in the system
Duplicate Contact records are a common data quality issue in CRM systems. If the same customer exists more than once, Sales Reps may log calls or activities against different records, unaware they are speaking to the same person. This creates a fragmented customer history and leads to poor customer experience, as multiple reps call the same person without visibility into prior interactions. Managing duplicates through matching rules, duplicate rules, and possibly an MDM strategy is critical.
Why not the others?
A. Missing phone number on the Contact record:
A missing phone number would prevent a call from being made at all, not cause duplicate calls. While it’s a data quality issue, it does not explain why multiple reps would contact the same customer unknowingly.
B. Customer phone number has changed on the Contact record:
If a customer’s phone number changes, the risk is inability to reach them or contacting the wrong number, not multiple reps calling the same person. This is an accuracy issue, but it doesn’t fit the scenario of duplicate outreach.
D. Duplicate Activity records on a Contact:
Duplicate activities might clutter reporting but would still be tied to the same Contact record. Reps would see that another call has already been logged if they’re viewing the same record, so this wouldn’t cause unawareness of previous calls.
Reference:
Salesforce Help: Manage Duplicates
Salesforce Architect Guide: Master Data Management
DreamHouse Realty has a data model as shown in the image. The Project object has a private sharing model, and it has Roll-Up summary fields to calculate the number of resources assigned to the project, total hours for the project, and the number of work items associated to the project. There will be a large amount of time entry records to be loaded regularly from an external system into Salesforce.
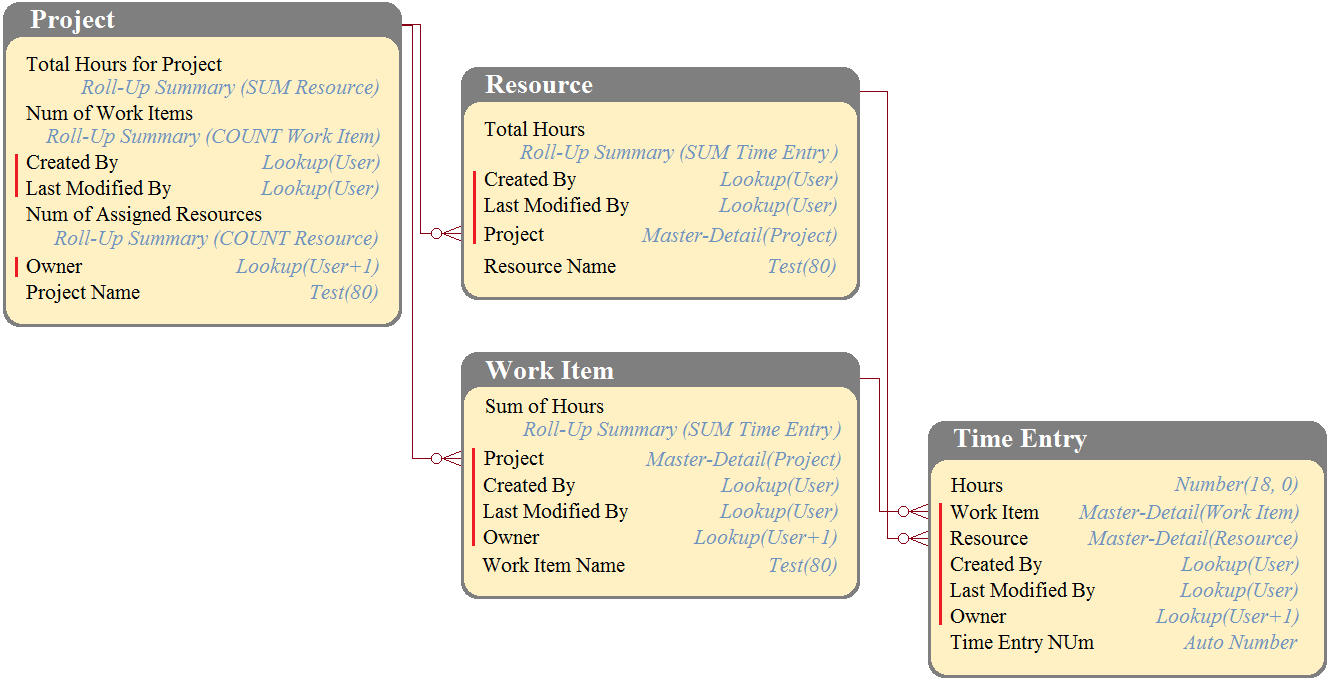
What should the Architect consider in this situation?
A. Load all data after deferring sharing calculations.
B. Calculate summary values instead of Roll-Up by using workflow.
C. Calculate summary values instead of Roll-Up by using triggers.
D. Load all data using external IDs to link to parent records.
Explanation:
✅ Correct Answer: A. Load all data after deferring sharing calculations
When loading large volumes of child records (like Time Entries) into Salesforce, performance can be severely impacted if sharing rules and recalculations are triggered during each insert/update. Since Project uses a private sharing model, every new Time Entry affects access recalculations and roll-up summaries. By using the “defer sharing calculations” option, the Architect ensures data can be loaded efficiently without constant recalculation. Once the load finishes, sharing rules can be recalculated in bulk, improving performance and stability.
Why not the others?
❌ B. Workflow for summaries:
Workflows cannot calculate aggregate values across related child records. They only update fields on the same record. Roll-Up Summaries are the native way to handle aggregation. Attempting to use workflows here is not feasible, as workflows lack the ability to roll up large datasets.
❌ C. Triggers for summaries:
Triggers could theoretically calculate roll-up values, but this adds unnecessary customization and performance risk. With millions of Time Entries, trigger logic would slow down processing, risk hitting governor limits, and duplicate functionality already provided by Salesforce’s Roll-Up Summary fields. It also creates long-term maintenance complexity.
❌ D. Load data using external IDs:
External IDs are useful for linking child records to parent objects during a data load. However, they do not address the performance issue caused by roll-up calculations and sharing recalculations. This option may help establish relationships, but it does not solve the core problem described in the scenario.
Reference:
Salesforce Help: Defer Sharing Calculations
Salesforce Best Practices for Large Data Volumes
| Page 6 out of 22 Pages |
| Previous |