A Mule application includes a subflow containing a Scatter.Gather scope. Within each log
of the Scatter.Gatter. an HTTP connector calls a PUT endpoint to modify records in
different upstream system. The subflow is called inside an Unit successful scope to retry if
a transitory exception is raised.
A technical spike is beingperformed to increase reliability of the Mule application.
Which steps should be performed within the Mule flow above the ensure idempontent
behavior?
A. A. Change the PUT requests inside the Scatter-Gather to POST requests
B. Ensure an error-handling flow performs corrective actions to roll back all changes if any leg of the Scatter-Gather fails
C. Remove the Put requests from the Scatter-Getter and perform them sequentially
D. None, the flow already exhibits idempotent behavior
Explanation:
Understanding the Problem:
The flow uses a Scatter-Gather scope to parallelly send PUT requests to multiple upstream systems.
The subflow is wrapped in an Until Successful scope to retry on transient failures.
The goal is to ensure idempotency (repeating the same operation multiple times without unintended side effects).
Why Option B is Correct?
Idempotency in Scatter-Gather:
1. If one leg fails, the entire Scatter-Gather fails (unless using on-error-continue).
2. Without rollback, some systems may be updated while others are not, leading to inconsistent data.
3. A compensating transaction (rollback) ensures that if any part fails, all changes are reverted, maintaining consistency.
PUT vs. POST (Why Not Option A?)
PUT is naturally idempotent (multiple identical requests have the same effect as one).
Changing to POST (non-idempotent) would worsen reliability.
Sequential Execution (Why Not Option C?)
Removing parallel execution defeats the purpose of Scatter-Gather (performance optimization).
Sequential execution does not inherently solve idempotency—it just makes error handling simpler.
Current Flow is Not Fully Idempotent (Why Not Option D?)
The Until Successful scope retries on failure, but if a previous PUT succeeded and a later one fails, the retry could duplicate updates.
Without rollback, partial success leads to inconsistent state.
Best Practice for Idempotency in MuleSoft:
Use compensating transactions (rollback logic) in error handling.
Consider idempotency keys (unique identifiers for requests) if the upstream systems support them.
Ensure PUT (not POST) is used for updates when possible.
Reference:
MuleSoft Docs: Scatter-Gather Error Handling
MuleSoft Docs: Idempotency in REST APIs
An API has been built to enable scheduling email provider. The front-end system does very
little data entry validation, and problems have started to appear in the email that go to
patients. A validate-customer’’ flow is added validate thedata.
What is he expected behavior of the ‘validate-customer’’ flow?

A. If only the email address Is invalid a VALIDATION.INVALID_EMAIL error is raised
B. If the email address is invalid, processing continues to see if the appointment data and customer name are also invalid
C. If the appointment date and customer name are invalid, a SCHEDULE:INVALID_APPOINTMENT_DATE error is raised
D. If all of the values are invalid the last validation error is raised:SCHEDULE:INVALID_CUSTOMER_NAME
Explanation:
This question is testing your understanding of error handling and validation flow within Mule applications, specifically how validation components typically behave and how errors are propagated.
Let's break down the options:
A. If only the email address Is invalid a VALIDATION.INVALID_EMAIL error is raised
Plausible. In a typical validation flow, if a specific validation rule fails (e.g., email format), an error related to that failure is raised immediately. This is standard behavior for "fail-fast" validation.
B. If the email address is invalid, processing continues to see if the appointment data and customer name are also invalid
Less plausible for a single validate-customer flow designed for "fail-fast". While you can design validation to collect all errors before throwing, a single validate-customer flow implies a sequence. If the email is fundamentally invalid, continuing to validate other fields for the same customer might be redundant if the overall record is already considered invalid. However, if the validate-customer flow contains multiple, independent validation components that are designed to execute regardless of prior failures (e.g., using a scatter-gather for parallel validation, or a custom approach), this could happen, but it's not the most common "expected behavior" for a named validation flow unless explicitly stated.
C. If the appointment date and customer name are invalid, a
SCHEDULE:INVALID_APPOINTMENT_DATE error is raised
Highly Unlikely. If multiple validation errors occur within a sequential flow, typically only the first error encountered will be propagated and stop the flow, unless there's specific logic to aggregate errors. If both the appointment date and customer name are invalid, and the validation for appointment date precedes customer name, then SCHEDULE:INVALID_APPOINTMENT_DATE would be raised. However, if the customer name validation precedes the appointment date, then SCHEDULE:INVALID_CUSTOMER_NAME would be raised. This option implies a specific priority, but not the general behavior when multiple validations fail sequentially.
D. If all of the values are invalid the last validation error is raised:
SCHEDULE:INVALID_CUSTOMER_NAME
Plausible if validations are sequential and CUSTOMER_NAME is the last one checked. This aligns with the "fail-fast" principle where the first encountered error stops the flow and is raised. If CUSTOMER_NAME validation is the last one in sequence and all previous ones passed (or were not reached because of an earlier failure), and then CUSTOMER_NAME fails, this would be the error raised. However, the question implies multiple validations within the validate-customer flow. If the first validation (e.g., email) fails, then subsequent validations for appointment date and customer name might not even be executed.
Re-evaluating based on "Expected Behavior"
In a typical MuleSoft validation scenario, especially with out-of-the-box validation components:
Fail-Fast is the
default: When a validation component encounters an invalid input, it typically stops further processing in that path and raises an error immediately.
Error Type Specificity: The error raised will usually be specific to the validation that failed.
Given this, let's reconsider:
If the validate-customer flow is designed to validate sequentially (email, then appointment date, then customer name):
If the email is invalid, it would raise an INVALID_EMAIL error and stop.
If the email is valid but the appointment date is invalid, it would raise an INVALID_APPOINTMENT_DATE error and stop.
If both email and appointment date are valid but the customer name is invalid, it would raise an INVALID_CUSTOMER_NAME error and stop.
Now, let's look at the options again with this understanding:
A. If only the email address Is invalid a VALIDATION.INVALID_EMAIL error is raised
This is the most accurate description of typical "fail-fast" validation behavior. If the email is the first validation to fail, it will be the error that's raised, and subsequent validations won't be performed.
B. If the email address is invalid, processing continues to see if the appointment data and customer name are also invalid
This would only happen if the validation flow is explicitly designed for all-at-once validation (e.g., using a custom aggregator or All scope with specific error handling to collect all errors). This is not the default or "expected" behavior of a simple validation flow.
C. If the appointment date and customer name are invalid, a SCHEDULE:INVALID_APPOINTMENT_DATE error is raised
This is too specific and assumes the order of validation and that the SCHEDULE:INVALID_APPOINTMENT_DATE is always the first one to fail among those two. It doesn't account for the email validation potentially failing first.
D. If all of the values are invalid the last validation error is raised: SCHEDULE:INVALID_CUSTOMER_NAME
This is only true if the customer name validation is the last one in the sequence and all preceding validations passed. If "all values are invalid," the first invalid value encountered in the sequence would typically cause the error to be raised, not necessarily the last one.
Conclusion:
The most standard and "expected" behavior of a validation flow in MuleSoft, especially when not specified otherwise (like collecting all errors), is to fail fast. This means the moment an invalid condition is met, an error specific to that condition is raised, and the flow stops.
Therefore, if the email address is the first thing validated and it's invalid, that's the error that will be raised.
The final answer is
A
Multiple individual Mute application need to use the Mule Maven plugin to deploy to
CloudHub.
The plugin configuration should .. reused where necessary and anything project, specific
should be property-based.
Where should the Mule Maven details be configured?
A. A parent pom.xml
B. Settings, xml
C. Pom, xml
D. A Bill of Materials (BOM) parent pm
Explanation:
Understanding the Problem:
Multiple Mule applications need to deploy to CloudHub using the Mule Maven Plugin.
The plugin configuration should be reusable across projects, while project-specific settings (e.g., environment, app name) should be property-driven.
The question asks where the Mule Maven Plugin details should be configured for maximum reusability.
of Options:
Option A: A parent pom.xml
Why?
1.A parent pom.xml allows centralized plugin management for multiple Mule projects.
2.Common configurations (e.g., Mule Maven Plugin version, CloudHub settings) can be inherited by child projects.
3.Project-specific values (e.g., application.name, environment) can be overridden using Maven properties (
Best Practice:
MuleSoft recommends using a parent POM for shared configurations in a multi-project setup.
Option B: settings.xml
Why?
1.settings.xml is used for Maven global settings (e.g., repositories, credentials) but not for plugin configurations.
2.It cannot define the Mule Maven Plugin behavior for deployments.
Option C: pom.xml (Partially Correct but Not Best for Reusability)
Why?
1.While you can define the Mule Maven Plugin in an individual project’s pom.xml, this does not promote reusability.
2.If multiple projects need the same plugin config, duplicating it in each pom.xml violates DRY (Don’t Repeat Yourself) principles.
Option D: A Bill of Materials (BOM) parent POM ( Incorrect for Plugin Config)
Why?
A BOM is used for dependency management (e.g., Mule runtime versions) but not for plugin configurations.
While useful, it does not solve the problem of reusable plugin setups.
Best Practice for Mule Maven Plugin Configuration:
Parent POM (pom.xml)
Define the Mule Maven Plugin in a parent POM with default configurations.
Example:
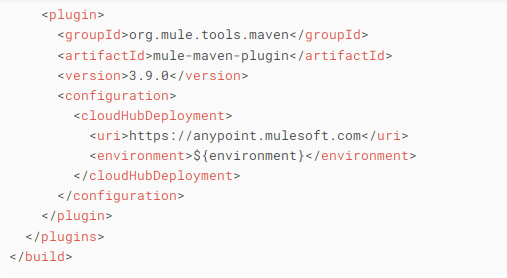
.
.
Child POM (pom.xml)
Inherit from the parent POM
.
Override project-specific properties (e.g., ${environment}, ${application.name}).
Reference:
MuleSoft Docs:
Mule Maven Plugin Configuration
Maven Docs:
POM Inheritance
A Mule application contain two policies Policy A and Policy A has order1, and Policy B has
order 2. Policy A Policy B, and a flow are defined by he configuration below.

When a HTTP request arrives at the Mule application’s endpoint, what will be the execution
order?
A. A1, B1, F1, B2, A2
B. B1, A1, F1, A2, B2
C. F1, A1, B1, B2, A2
D. F1, B1, A1, A2, B2
Explanation:
Understanding Policy Execution Order in Mule 4
Policies are applied in ascending order (lower order value executes first).
Policy A (order=1) runs before Policy B (order=2).
Policy Execution Flow:
Each policy executes before (
Step-by-Step Execution:
Request arrives → Policy A (order=1) starts:
Policy B (order=2) runs:
Main Flow (
Post-Flow Policy Execution (Reverse Order):
After
Then back to Policy A:
Visual Flow:
text
Request → A1 → B1 → F1 → B2 → A2 → Response
Why Other Options Are Incorrect?
Option B:
Incorrectly reverses Policy A/B order.
Option C/D:
Incorrectly place
Key Concept:
Policies wrap the target flow like an onion:
Pre-processing (A1, B1) runs top-down (order=1 → order=2).
Post-processing (B2, A2) runs bottom-up (order=2 → order=1).
Reference:
MuleSoft Docs:
HTTP Policy Execution Order
Conclusion:
The correct execution order is A1 → B1 → F1 → B2 → A2 (Option A).
Mule application A is deployed to CloudHub and is using Object Store v2. Mute application
B is also deployed to CloudHub.
Which approach can Mule application B use to remove values from Mule application A’S
Object Store?
A. Object Store v2 RESTAPI
B. CloudHub Connector
C. Object Store Connector
D. CloudHub REST API
Explanation
Why This Is the Right Approach
Object Store v2 is designed to store key-value data for Mule applications running on CloudHub.
Each Mule app has its own isolated Object Store, meaning App B cannot directly access App A’s store using standard connectors.
However, MuleSoft provides a REST API interface for Object Store v2 that allows authorized external access — including reading, writing, and deleting data.
This API is secured and requires proper authentication using credentials from Anypoint Platform.
How It Works Conceptually
Authentication:
App B must authenticate with Anypoint Platform to prove it has permission to access App A’s Object Store.
Targeting the Right Store: App B specifies the organization, environment, and store name associated with App A.
Performing the Action:
Once authenticated, App B can send a request to delete specific keys from App A’s Object Store.
Why Other Options Don’t Work
CloudHub Connector
Manages app lifecycle (start, stop, deploy), not Object Store data.
Object Store Connector
Only works within the same app — no cross-app access.
CloudHub REST API
Focuses on app deployment and monitoring, not data storage.
A Flight Management System publishes gate change notification events whenever a flight’s
arrival gate changes. Other systems, including Baggage Handler System. Inflight Catering
System and Passenger Notifications System, must each asynchronously receive the same
gate change notification to process the event according.
Which configuration is required in Anypoint MQ to achieve this publish/subscribe model?
A. Publish each client subscribe directly to the exchange. Have each client subscribe directly to the queue.
B. Publish the gate change notification to an Anypoint MC queue Have each client subscribe directly to the queue
C. Publish the gate change notification to an Anypoint MQ queue. Createdifferent anypoint MQ exchange meant for each of the other subscribing systems Bind the queue with each of the exchanges
D. Publish the gate change notification to an Anypoint MQ exchanhe. Create different Anypoint MQ queues meant for each of the other subscribing systems. Bind the exchange with each of the queues.
Explanation:
Scenario Requirements:
1.One Publisher, Multiple Subscribers:
The Flight Management System publishes gate change events.
Three other systems (Baggage Handler, Catering, Passenger Notifications) must each receive the same event independently.
2.Asynchronous Processing:
Subscribers should process events without interfering with each other.
Why Option D is the Correct Solution?
Anypoint MQ Pub/Sub Model:
1.Exchange as a Distributor
The publisher sends messages to an exchange, which acts as a central routing hub.
The exchange does not store messages; it forwards them to bound queues.
2.Dedicated Queues for Each Subscriber:
Each subscribing system (Baggage, Catering, Passenger) has its own queue.
This ensures:
No message loss (queues persist messages until consumed).
Independent processing (one slow system doesn’t block others).
3.Binding Queues to the Exchange:
The exchange is linked to all subscriber queues.
When a message is published, the exchange copies it to every bound queue.
Why This Works:
Guaranteed Delivery: All subscribers receive the same message via their dedicated queues.
Decoupling:
The publisher doesn’t need to know about subscribers (only the exchange).
Scalability:
New systems can be added by creating new queues and binding them.
Why Other Options Fail?
Option A:
Subscribers Directly to Exchange
Problem:
Anypoint MQ does not allow direct subscriptions to exchanges. Queues are required to receive messages.
Option B:
Single Queue for All Subscribers
Problem:
Only one subscriber gets the message (competing consumers).
Other systems never receive the event, breaking the requirement.
C: Multiple Exchanges + One Queue
Problem:
Exchanges cannot replicate messages to a single queue.
Subscribers still compete for messages, defeating the purpose.
Key Concepts:
Fanout Exchange:
Best for broadcasting messages to all bound queues (used in this scenario).
Queue Persistence:
Ensures messages are not lost if a subscriber is offline.
Decoupled Architecture:
Publishers and subscribers operate independently, improving scalability.
Reference:
Anypoint MQ Pub/Sub Documentation
A company deploys 10 public APIs to CloudHub. Each API has its individual health
endpoint defined. The platform operation team wants to configure API Functional
Monitoring to monitor the health of the APIs periodically while minimizing operational
overhead and cost.
How should API Functional Monitoring be configured?
A. From one public location with each API in its own schedule
B. From one private location with all 10 APIs in a single schedule
C. From one public location with all 10 APIs in a single schedule
D. From 10 public locations with each API in its own schedule
Explanation:
This setup is the most cost-effective and operationally efficient because:
Public APIs can be monitored from public locations, which are shared resource pools provided by MuleSoft (e.g., us-east-1, eu-central-1).
A single schedule can include multiple endpoints, allowing you to monitor all 10 APIs in one test suite.
This reduces:
Cost:
Fewer schedules and locations mean fewer resources consumed.
Operational Overhead:
Easier to manage and maintain one monitor instead of ten.
Why the Other Options Are Less Optimal:
A. One public location with each API in its own schedule
Creates 10 separate schedules — more overhead and resource usage.
B. One private location with all APIs in one schedule
Private locations are for private APIs (inside VPCs). Not needed for public APIs.
D. 10 public locations with each API in its own schedule
Excessive use of locations and schedules — high cost and complexity.
A scatter-gather router isconfigured with four routes:Route A, B, C and D. Route C false.
A. Error,errorMesage.payload.results [‘2’]
B. Payload failures[‘2’]
C. Error,errorMessage,payload.failures[‘2’]
D. Payload [‘2’]
Explanation:
The scatter-gather router in Mule 4 executes all routes concurrently and collects their responses. If a route fails (e.g., Route C), the router can be configured with a target variable to store results and failures, or it can throw an error that can be caught in an error handler. The aggregated payload typically contains a results array for successful responses and a failures array for failed routes, indexed by the route’s position. Let’s evaluate the options:
Option A: Error, errorMessage.payload.results[‘2’]
This suggests accessing the results array within an errorMessage.payload, which contains successful route outputs. However, if Route C fails, its entry in the results array would be null or undefined, not an error detail. This option is incorrect because it looks for a result where a failure occurred.
Option B: Payload.failures[‘2’]
This attempts to access the failures array directly from the payload. While the payload can contain a failures array when failures occur, this syntax is incomplete. In Mule 4, when an error is thrown (e.g., in a default error handler), the failure details are typically accessed via the error object (e.g., error.errorMessage.payload.failures), not just payload.failures alone. This option lacks the proper context and is incorrect.
Option C: Error, errorMessage, payload.failures[‘2’]
This is the correct approach. When a scatter-gather route fails and an error is raised (e.g., caught in a Try scope or global error handler), the error object contains an errorMessage with a payload. This payload includes a failures array that lists details of failed routes, indexed by their position (0 for A, 1 for B, 2 for C, 3 for D). The expression error.errorMessage.payload.failures[‘2’] accesses the failure details for Route C, which aligns with the scenario where Route C failed. The comma-separated format (e.g., "Error, errorMessage, payload.failures[‘2’]") may be a stylistic choice in the question, but it implies the full path to the failure data.
Behavior: If Route C fails (e.g., due to a connectivity issue or invalid data), the failures[‘2’] entry would contain the error details (e.g., error type, message), while results[‘2’] would be null.
Option D: Payload[‘2’]
This suggests accessing the payload directly at index 2, which might imply the aggregated payload’s structure. However, the scatter-gather payload is an object with results and failures arrays, not a simple list indexed directly. Accessing payload[‘2’] would not reliably target the failure for Route C and is incorrect without the proper failures context.
Detailed Behavior
Scatter-Gather Operation:
The router runs Routes A, B, C, and D in parallel. If Route C fails, the scatter-gather can either:
Continue and aggregate results/failures (if configured with target or no error propagation).
Throw an error (if set to fail on any route failure), which can be caught to inspect failures.
Failure Handling:
When an error is handled, the error.errorMessage.payload contains a structure like:
results:
Array of successful route outputs (e.g., [resultA, resultB, null, resultD]).
failures: Array of error details for failed routes (e.g., [null, null, {error: "Route C failed"}, null]).
Indexing:
The index [‘2’] corresponds to Route C, the third route, making failures[‘2’] the relevant data point for its failure.
Key Considerations for the MuleSoft Developer II Exam
Scatter-Gather Router:
Understand its parallel execution and aggregation of results/failures.
Error Handling: Know how to access error details using the error object, especially error.errorMessage.payload.failures.
Payload Structure:
Recognize the results and failures arrays in the scatter-gather output.
Configuration:
Be aware that scatter-gather behavior (e.g., failing on error) depends on settings like failOn="ANY".
Refer to the exhibit.
What is the result if ‘’Insecure’’ selected as part of the HTTP Listener configuration?
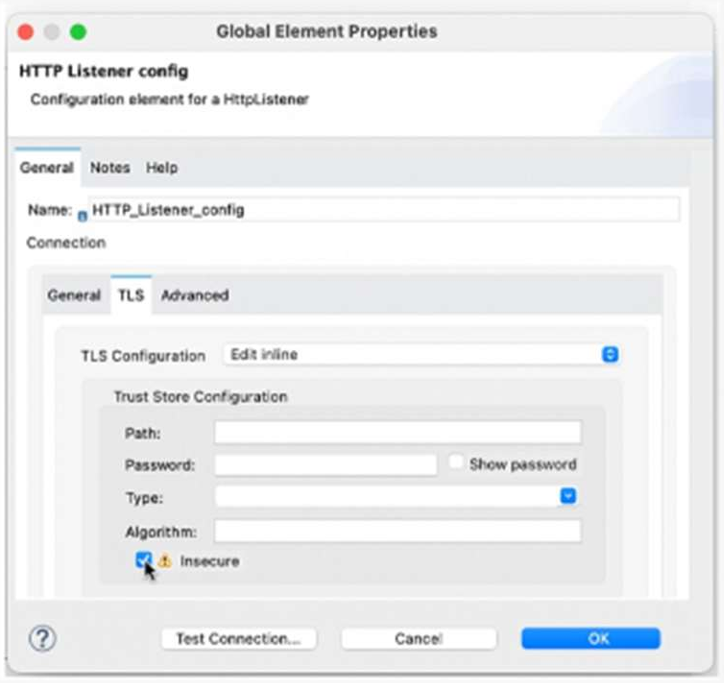
A. The HTTP Listener will trust any certificate presented by the HTTP client
B. The HTTP Lister will accept any unauthenticated request
C. The HTTP listener will only accept HTTP requests
D. Mutual TLS authentication will be enabled between this HTTP Listener and an HTTP client
Explanation:
When configuring an HTTPS Listener in MuleSoft, enabling the “Insecure” checkbox means:
The listener does not validate the client’s certificate.
It accepts any certificate, even if it’s self-signed, expired, or from an untrusted CA.
This is typically used in development or testing environments, where strict TLS validation is not required.
Why the Other Options Are Incorrect:
B. Accepts any unauthenticated request
Not accurate — it still uses HTTPS, just skips certificate validation.
C. Only accepts HTTP requests
Incorrect — “Insecure” applies to HTTPS, not HTTP.
D. Mutual TLS authentication enabled
Opposite — “Insecure” disables certificate validation, which is required for mutual TLS.
Reference:
You can read more about this in the MuleSoft HTTP Listener Configuration Guide.
Would you like to explore how to securely configure mutual TLS in MuleSoft for production environments?
Which configurations are required for HTTP Listener to enable mTLS authentication?
A. Set an appropriate reconnection strategy and use persistent connections for the listener
B. Set an appropriate keystore configuration and use persistent connections for the listener
C. Set an appropriate keystore and truststore configuration for the listener
D. Set an appropriate truststore configuration and reconnection strategy for the listener
Explanation:
Key Concept:
Mutual TLS (mTLS) in HTTP Listener
Mutual TLS (mTLS) requires both the server and client to authenticate each other using digital certificates. To enable mTLS in an HTTP Listener in MuleSoft 4, you must configure:
Keystore (Server Identity):
Contains the server’s certificate and private key.
Proves the server’s identity to the client.
Truststore (Client Validation):
Contains trusted client certificates (or CA certificates).
Validates the client’s certificate during the TLS handshake.
Why Option C is Correct?
Keystore:
Ensures the server presents a valid certificate to the client.
Truststore:
Ensures the server only accepts connections from clients with trusted certificates.
Together, they enforce mutual authentication.
Why Other Options Are Incorrect?
1.Option A (Reconnection strategy + persistent connections):
These are performance-related settings and do not enable mTLS.
2.Option B (Keystore + persistent connections):
Missing the truststore, which is mandatory for client certificate validation.
3.Option D (Truststore + reconnection strategy):
Missing the keystore, which is required for server identity.
Additional Notes:
mTLS Flow:
Client connects to the HTTP Listener.
Server presents its certificate (keystore).
Client validates the server’s certificate.
Client sends its certificate.
Server validates the client’s certificate (truststore).
Without Truststore:
The server cannot verify client certificates, breaking mTLS.
Reference:
MuleSoft TLS Configuration Guide
When implementing a synchronous API where the event source is an HTTP Listener, a
developer needs to return the same correlation ID backto the caller in the HTTP response
header.
How can this be achieved?
A. Enable the auto-generate CorrelationID option when scaffolding the flow
B. Enable the CorrelationID checkbox in the HTTP Listener configuration
C. Configure a custom correlation policy
D. NO action is needed as the correlation ID is returned to the caller in the response header by default
Explanation:
MuleSoft automatically generates a correlation ID when an event is received by an HTTP Listener.
If the incoming request includes an X-Correlation-ID header, Mule will use that value.
If not, Mule generates a new one using its correlation ID generator.
This ID is stored in the event context and is automatically propagated in the response headers unless explicitly disabled.
So, no manual configuration is required to return it — Mule does this by default for traceability and logging purposes2.
Want to verify it?
You can inspect the response headers using a tool like Postman or curl and look for:
X-Correlation-ID:
Why the Other Options Are Incorrect:
A. Auto-generate CorrelationID when scaffolding
No such scaffolding option exists — correlation ID is runtime behavior.
B. CorrelationID checkbox in HTTP Listener
There’s no checkbox for this in the HTTP Listener config.
C. Custom correlation policy
Only needed if you want to override the default behavior — not required for basic propagation.
A Mule application uses API autodiscovery to access and enforce policies for a RESTful implementation.
A. Northing because flowRef is an optional attribute which can be passed runtime
B. The name of the flow that has APlkit Console to receive all incoming RESTful operation requests.
C. Any of the APIkit generate implement flows
D.
Explanation:
API autodiscovery is used to associate a Mule application with an API instance in Anypoint Platform, allowing policies (e.g., rate limiting, security) to be applied. The flowRef attribute in the
Role of flowRef:
The flowRef must reference the flow containing the HTTP Listener that accepts incoming requests. This ensures that autodiscovery correctly ties the API instance to the flow where policies are enforced and requests are routed.
APIkit Context:
When using APIkit to implement a RESTful API, it generates flows (e.g., main flow) with an HTTP Listener to handle all operations. The flowRef should point to this flow, which acts as the root for receiving and dispatching requests to other APIkit-generated flows.
Why Option D:
The name of the flow that has HTTP listener to receive all incoming RESTful operation requests?
This is correct because the flowRef must specify the flow with the HTTP Listener that serves as the entry point for the RESTful API. In an APIkit project, this is typically the main flow (e.g., api-main) generated by APIkit, which listens for incoming requests and routes them to the appropriate operation flows. Autodiscovery uses this reference to apply policies and track the API.
Why Not the Other Options?
Option A:
Nothing because flowRef is an optional attribute which can be passed runtime
This is incorrect. The flowRef attribute is not optional in
Option B:
The name of the flow that has APIkit Console to receive all incoming RESTful operation requests
This is incorrect. The APIkit Console is a tool for testing and interacting with the API, not a flow that receives requests. The flowRef should point to a flow with an HTTP Listener, not one associated with the console, which is a separate component hosted by the Mule runtime.
Option C:
Any of the APIkit generate implement flows
This is incorrect. APIkit generates multiple flows for each operation defined in the RAML/OAS (e.g., get:\resource, post:\resource), but these are implementation flows that handle specific endpoints. The flowRef must point to the main entry flow with the HTTP Listener, not any arbitrary implementation flow, to ensure proper request routing and policy enforcement.
Detailed Behavior
Autodiscovery Setup:
The
Example Flow:
In an APIkit project, the main flow might look like a single HTTP Listener with a base path (e.g., /api/*), which routes requests to operation-specific flows. The flowRef ties this entry point to the autodiscovery configuration.
Key Considerations for the MuleSoft Developer II Exam
API Autodiscovery:
Understand the role of
APIkit:
Know how APIkit generates flows and the importance of the main flow with the HTTP Listener.
Policy Enforcement:
Recognize that autodiscovery links the API to Anypoint Platform for governance.
Configuration:
Be aware that flowRef must match an existing flow name in the application.
| Page 1 out of 5 Pages |