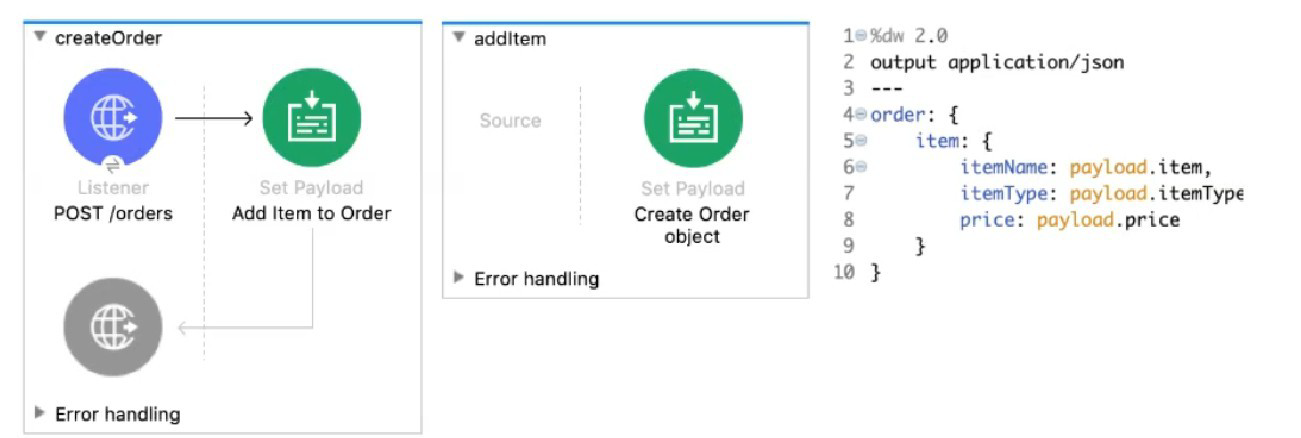
Refer to the exhibits. The Set Payload transformer in the addltem child flow uses DataWeave to create an order object.
What is the correct DataWeave code for the Set Payload transformer in the createOrder flow to use the addltem child flow to add a router call with the price of 100 to the order?
A. lookup( "addltern", { price: "100", item: "router", itemType: "cable" } )
B. addltem( { payload: { price: "100", item: "router", itemType: "cable" > } )
C. lookup( "addltem", { payload: { price: "100", item: "router", itemType: "cable" } > )
D. addltem( { price: "100", item: "router", itemType: "cable" } )
Explanation:
dataweave
%dw 2.0
output application/json
---
lookup("addItem", { payload: { price: "100", item: "router", itemType: "cable" } })
Why:
lookup( moduleName, args ) invokes the child flow named addItem.
Mule wraps your map in a payload key when calling child flows—so your input map must live under payload.
The DataWeave code matches the child flow’s expected payload.item, payload.itemType, and payload.price fields.
Other options fail because they either:
Don’t wrap under payload (A, D).
Use the wrong flow name or stray braces (B).
Which Mule component provides a real-time, graphical representation of the APIs and mule applications that are running and discoverable?
A. API Notebook
B. Runtime Manager
C. Anypoint Visualizer
D. API Manager
Explanation:
Anypoint Visualizer is the MuleSoft component that provides a real-time, graphical visualization of APIs, Mule applications, and the way they interact within your ecosystem. It shows data flow between services, helps detect anomalies, and supports architecture governance by mapping service dependencies. Visualizer pulls live data from Runtime Manager and API gateways, displaying communication paths and dependencies.
This tool is especially useful for observability in complex environments where multiple APIs and applications interact. You can filter views by layer (Experience, Process, System), environment, or policy compliance. This real-time map enables architects and ops teams to quickly understand and troubleshoot live systems.
Unlike other tools in Anypoint Platform, Visualizer focuses on topology and live traffic, not just configuration or management. It’s ideal for identifying service chokepoints, unauthorized connections, or understanding microservice architecture health in production.
Incorrect Options:
A. API Notebook – Used for interactive API testing and documentation, not visualization.
B. Runtime Manager – Manages deployments and logs; no visual mapping.
D. API Manager – Manages API policies and access control, not topology mapping.
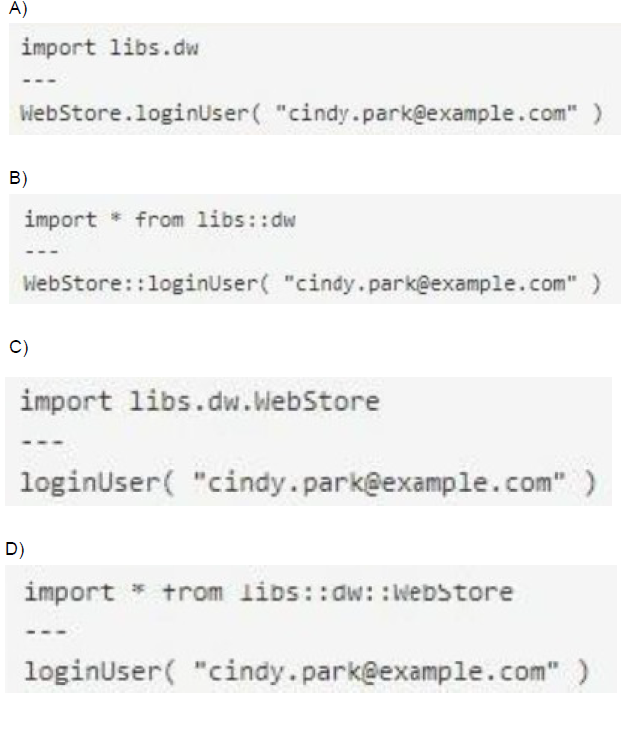
A Mule project contains a DataWeave module file WebStore dvA that defines a function named loginUser The module file is located in the projects src/main/resources/libs/dw folder
What is correct DataWeave code to import all of the WebStore.dwl file's functions and then call the loginUser function for the login "cindy.park@example.com"?
A. Option A
B. Option B
C. Option C
D. Option D
Explanation:
You need to import all functions from the WebStore.dwl module under src/main/resources/libs/dw. The correct syntax uses the from keyword with the module’s namespace libs::dw::WebStore. Then you can call loginUser directly without qualifying it:
%dw 2.0
output application/json
import * from libs::dw::WebStore
---
loginUser("cindy.park@example.com")
This brings every function in WebStore.dwl into the script’s scope and lets you call loginUser directly.
Options A and C use incorrect import paths or syntax, while B qualifies the function call instead of making it directly available.
Which of the below functionality is provided by zip operator in DataWeave?
A. Merges elements of two lists (arrays) into a single list
B. Used for sending attachments
C. Minimize the size of long text using encoding.
D. All of the above
Explanation:
The zip operator in DataWeave combines elements from two arrays/lists into a single list of pairs (or tuples). For example:
[1, 2] zip ["a", "b"] // Output: [[1, "a"], [2, "b"]]
This matches Option A.
Why Other Options Are Wrong:
B (Attachments): Unrelated—zip doesn’t handle MIME attachments.
C (Text compression): zip doesn’t encode/minimize data.
D (All): Incorrect, as only Option A is valid.
A web client submits a request to http://localhost:8081?accountType=personal. The query parameter is captured using a Set Variable transformer to a variable named accountType.
What is the correct DataWeave expression to log accountType?
A. Account Type: #[flowVars.accountType]
B. Account Type: #[message.inboundProperties.accountType]
C. Account Type: # [attributes.accountType]
D. Account Type: #[vars.accountType]
Explanation:
vars: Keyword for accessing a variable, for example, through a DataWeave expression in a Mule component, such as the Logger, or from an Input or Output parameter of an operation. If the name of your variable is myVar, you can access it like this: vars.myVar Hence correct answer is Account Type: #[vars.accountType]
An API has been created in Design Center. What is the next step to make the API discoverable?
A. Publish the API to Anypoint Exchange
B. Publish the API from inside flow designer
C. Deploy the API to a Maven repository
D. Enable autodiscovery in API Manager
Explanation:
Correct answer is Publish the API to Anypoint Exchange
1) In private exchange for internal developers
2) In a public portal for external developers/clients

An On Table Row Database listener retrieves data from a table that contains record_id, an increasing numerical column. How should the listener be configured so it retrieves new rows at most one time?
A. Set the target to store the last retrieved record_id value
B. Set the ObjectStore to store the last retrieved record_id value
C. Set the target to the record_id column
D. Set the watermark column to the record id column
Explanation:
The On Table Row Database listener in MuleSoft is designed to poll a database table for new records. To ensure it retrieves only new rows (and does not repeat the same ones), you must configure a "watermark column". This is a column with values that increase over time, such as a timestamp or a numeric ID. In this case, record_id is an increasing numeric column, making it ideal for a watermark.
When you set the watermark column to record_id, the listener will track the last retrieved value and, on the next poll, will only select rows where record_id is greater than that value. This prevents duplicate processing of previously retrieved records and ensures that each new row is only picked up once. This is the most effective and scalable way to track progress in polling operations.
While you can use an Object Store (Option B) to manually manage state, the watermark feature is built-in and more appropriate for this use case. The target setting (mentioned in Options A and C) is used to store query results, not to track which records have already been retrieved — so those are incorrect.
Incorrect Options:
A. Set the target to store the last record_id – target stores data, not progress tracking.
B. Set the ObjectStore to store last record_id – Possible, but unnecessary; watermark is built-in.
C. Set the target to the record_id column – Misuses target; it doesn’t control polling behavior.
A web client submits a request to http://localhost:8081/books/0471767840. The value "0471767840" is captured by a Set Variable transformer to a variable named booklSBN.
What is the DataWeave expression to access booklSBN later in the flow?
A. booklSBN
B. attributes.booklSBN
C. flowVars.booklSBN
D. vars. booklSBN
Explanation:
In Mule 4, variables are accessed via the vars scope. The correct syntax to retrieve the booklSBN variable is:
vars.booklSBN
Why Other Options Are Wrong:
A (booklSBN): Missing scope prefix (vars).
B (attributes.booklSBN): attributes stores metadata (e.g., query params), not flow variables.
C (flowVars.booklSBN): Mule 3 syntax (deprecated in Mule 4).
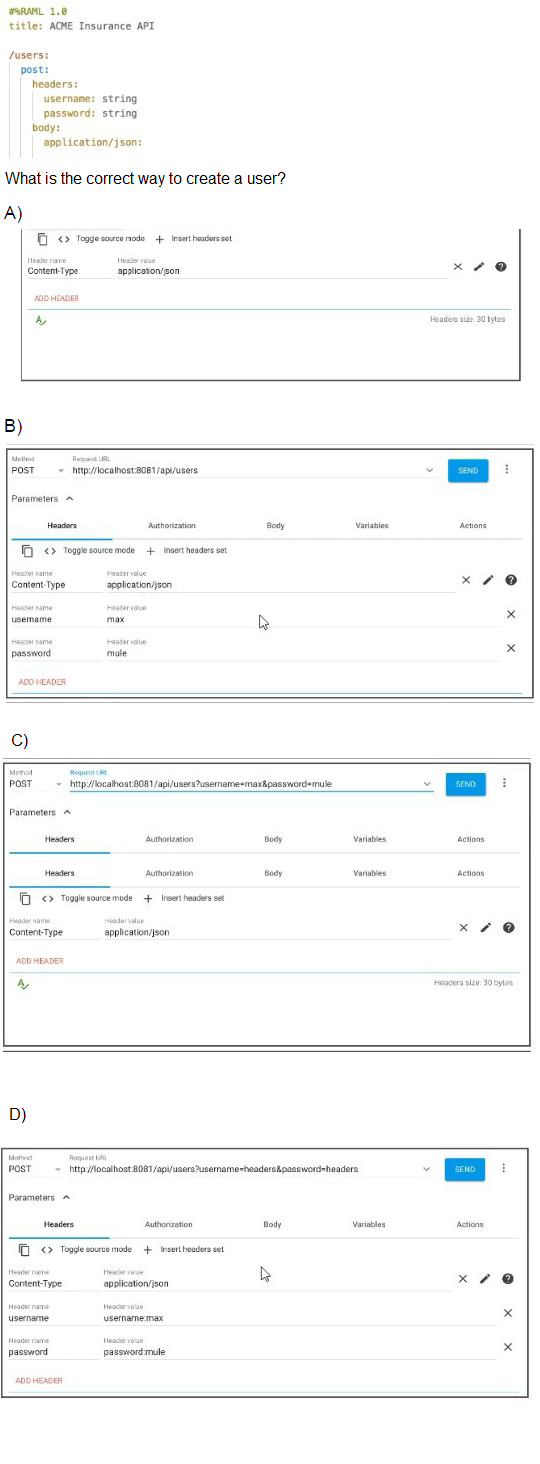
Refer to the exhibit.
A. Option A
B. Option B
C. Option C
D. Option D
Explanation:
According to the RAML specification at the top of the image, the POST /users endpoint expects:
Two headers: username and password, both as strings.
Request body: with content type application/json.
Option B correctly sets:
POST method to http://localhost:8081/api/users
Adds headers:
Content-Type: application/json
username: max
password: mule
This aligns precisely with the requirements defined in the RAML. It passes the credentials as headers and indicates the correct content type for the JSON payload (even if the payload is not shown, it's correctly structured to be accepted).
Incorrect Options:
A. Option A – Only sets Content-Type; missing username and password headers.
C. Option C – Incorrectly passes username and password as query parameters instead of headers.
D. Option D – Uses malformed header values (username.max and password.mule); also mixes query params with headers improperly.
Refer to the exhibit.
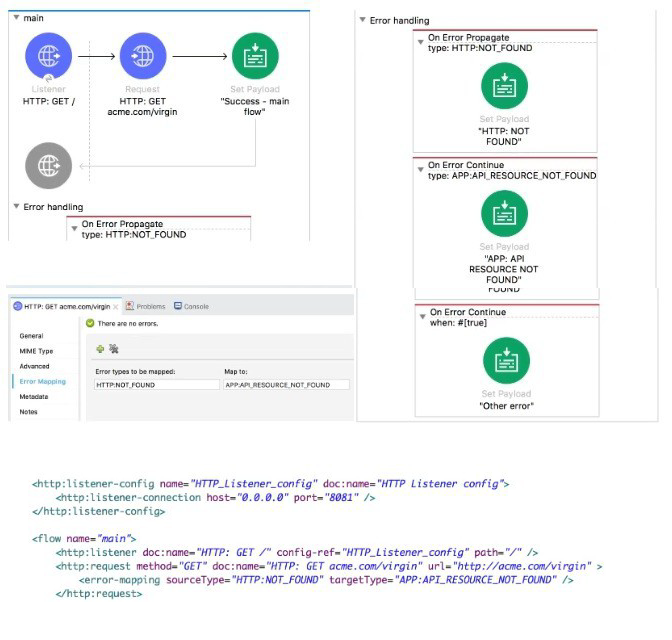
The main flow is configured with their error handlers. A web client submit a request to the HTTP Listener and the HTTP Request throws an HTTP:NOT_FOUND error.
What response message is returned?’’
What response message is returned?
A. APP: API RESOURCE NOT FOUND
B. HTTP: NOT FOUND
C. other error
D. success - main flow
Explanation:
Correct answer is APP: API RESOURCE NOT FOUND
1) A web client submits the request to the HTTP Listener.
2) The HTTP Request throws an "HTTP:NOT_FOUND" error, execution halts.
3) The On Error Propagate error Handler handles the error. In this case
,HTTP:NOT_FOUND error is mapped to custom error APP:API_RESOURCE_NOT_FOUND. This error processor sets payload to APP:API_RESOURCE_NOT_FOUND.
4) “APP:API_RESOURCE_NOT_FOUND. ” is the error message returned to the requestor in the body of the HTTP request with HTTP Status Code: 500
Refer to the exhibits.

The my-app xml file contains an Error Handier scope named "global-error-handler"
The Error Handler scope needs to be set to be the default error handler for every flow in the Mule application
Where and how should the value "global-error-handler" be added in the Mule project so that the Error Handler scope is the default error handler of the Mule application?
A. In the mule-artifact json file, as the value of a key-value pair
B. In the Validation folder as the value of a global element in the error-handling yaml file
C. In the pom.xml file, as the value of a global element
D. In the my-app.xml file, as an attribute of a configuration element
Explanation:
In MuleSoft, to apply a default global error handler across all flows, you must define the error handler globally and reference it at the application level. This is done using the defaultErrorHandler attribute inside the
This declaration tells MuleSoft to apply the global-error-handler (as defined in the
Incorrect Options:
A. mule-artifact.json – Manages deployment and app metadata, not flow behavior.
B. Validation folder – Not related to error handling configuration.
C. pom.xml – Used for dependency and build configuration, not error handling setup.
Refer to the exhibits.
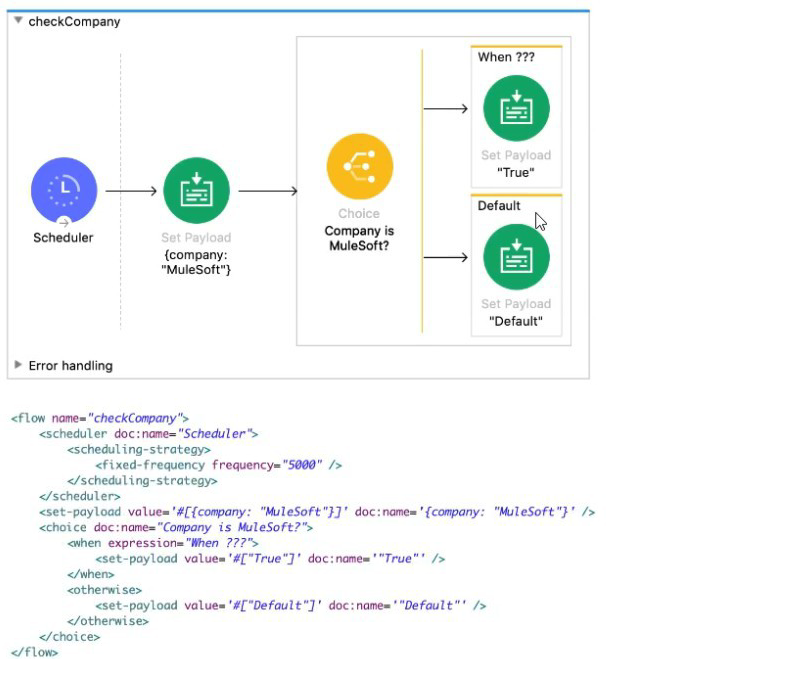
The
What is a valid
A. #['MuleSoft' == paytoad.company]
B. #[ company = "MuleSoft" ]
C. #[ if( company = "MuleSoft") ]
D. #[ if( 'MuleSoff == payload.company) ]
Explanation:
• In a Choice router you write a DataWeave boolean expression that returns true when you want to take the non-default branch.
• Here you need to compare the incoming event’s payload.company field to the literal "MuleSoft".
• The syntax is #[ 'MuleSoft' == payload.company ]—first string, then the equality operator, then the field reference.
Why the others don’t work:
• B (#[ company = "MuleSoft" ]) uses a single equals (assignment), not a comparison, and omits payload.
• C and D wrap things in if(…) unnecessarily and D even has a typo ('MuleSoff). So option A is the only valid boolean expression to route to your non-default flow.
| Page 4 out of 20 Pages |
| Previous |