How many Mule applications can run on a CloudHub worker?
A. At most one
B. At least one
C. Depends
D. None of these
Explanation:
On CloudHub, each worker is a dedicated runtime instance managed by MuleSoft’s cloud infrastructure. By design, each worker can run only one Mule application at a time. This ensures resource isolation, security, and performance consistency. This architecture allows scaling by adding more workers per application, but not by running multiple apps on one worker.
If you deploy two Mule applications, each will be assigned its own worker, depending on your configuration. This design simplifies application lifecycle management, logging, monitoring, and fault isolation. Unlike on-prem Mule runtimes (where multiple apps can share a runtime), CloudHub enforces the one-app-per-worker model.
This approach is deliberate to prevent conflicts in resource usage and to maintain high availability and scalability for each application. If you need to run multiple apps, you’ll need multiple workers or deploy them separately. The worker size (0.1 vCores, 1 vCore, etc.) only affects capacity — it doesn’t allow you to host more than one app per worker.
Incorrect Options:
B. At least one – Misleading; only one app can run per worker, not multiple.
C. Depends – No dependency here; the rule is fixed on CloudHub.
D. None of these – Incorrect; option A is valid.
Refer to the exhibits.
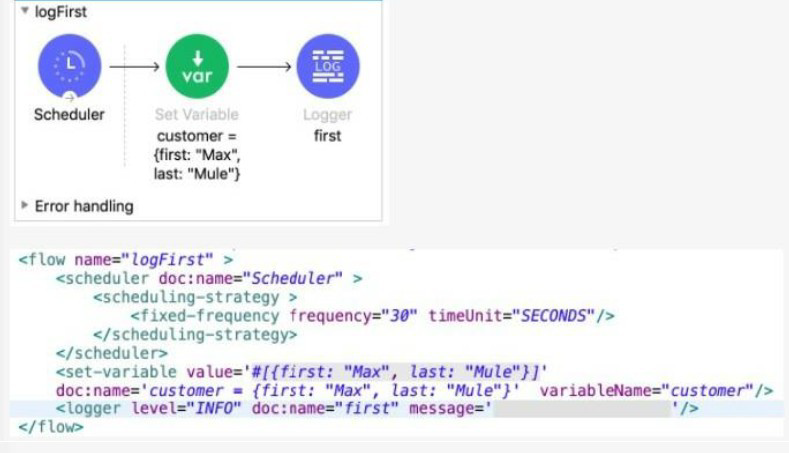
The Set Variable transformer is set with value #[ [ first "Max" last "Mule"} ].
What is a valid DataWeave expression to set as the message attribute of the Logger to access the value "Max" from the Mule event?
A. vars "customer first"
B. "customer first"
C. customer first
D. vars "customer" "first"
Explanation:
In MuleSoft, when you create a variable using the Set Variable component, the value is stored in the vars object. In this example, the variable named customer is an object with two key-value pairs: {first: "Max", last: "Mule"}. To access nested properties in a variable, you use dot notation. So to get the first name "Max", the correct expression is vars.customer.first.
This value can be used directly in a Logger or any other component that supports expressions. For the Logger's message attribute, setting it to #[vars.customer.first] will evaluate to "Max" at runtime, which is exactly the desired output based on the structure of the customer variable.
Using incorrect syntax like "customer first" or separating keys with spaces instead of dots will result in runtime errors or null values. Following the proper DataWeave expression syntax ensures that values stored in variables can be accurately accessed and used in other parts of the Mule application.
Incorrect Options:
B. "customer first" – Invalid string format; not a DataWeave expression.
C. customer first – Missing vars. and not wrapped in #[ ].
D. vars "customer" "first" – Not valid syntax; incorrect string/property access.
What MuleSoft product enables publishing, sharing, and searching of APIs?
A. Runtime Manager
B. API Notebook
C. API Designer
D. Anypoint Exchange
Explanation:
Anypoint Exchange is the MuleSoft product designed for publishing, sharing, and discovering APIs, connectors, templates, and other assets across teams. It acts as a centralized catalog where developers can search, reuse, and collaborate on API resources (Option D).
Why Other Options Are Wrong
A (Runtime Manager): Manages deployment and monitoring, not API sharing.
B (API Notebook): A deprecated tool for testing APIs interactively.
C (API Designer): Used for designing APIs (RAML/OAS), not publishing/sharing.
Refer to the exhibits.
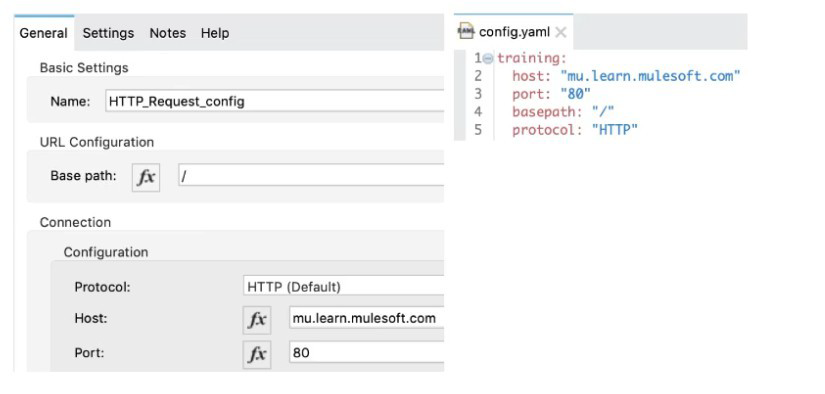
A Mule application has an HTTP Request that is configured with hardcoded values. To change this, the Mule application is configured to use a properties file named config.yaml.
what valid expression can the HTTP Request host value be set to so that it is no longer hardcoded?
A. ${training.host}
B. ${training:host}
C. #[training:host]
D. #[training.host]
Explanation:
Correct answer is ${training.host}
How to Configure Properties to Mule 4.X Platform?
1) Go to /src/main/resources project directory.
2) Create a configuration file with the name configuration.yaml inside the newly created config folder.
3) Go To Project > Global Element > Create > General >select the configuration.yaml file create in step- 2)
4) To verify develop a simple flow with HTTP listener which has above entries. Put the logger that prints the values on console.
5) Additional info: Similarly, when you want to access this port in DataWeave you need to use p function
According to Semantic Versioning, which version would you change for incompatible API changes?
A. No change
B. MINOR
C. MAJOR
D. PATCH
Explanation:
Correct answer is MAJOR
MAJOR version when you make incompatible API changes, MINOR version when you add functionality in a backwards compatible manner, and PATCH version when you make backwards compatible bug fixes.
A RAML specification is defined to manage customers with a unique identifier for each customer record. What URI does MuleSoft recommend to uniquely access the customer identified with the unique ID 1234?
A. /customers?custid=true&custid=1234
B. /customers/1234
C. /customers/custid=1234
D. /customers?operation=get&custid=1234
Explanation:
URI parameter (Path Param) is basically used to identify a specific resource or resources . For eg : the URL to get employee details on the basis of employeeID will be GET /employees/{employeeID} where employees is resource and {employeeID} is URI parameter. Hence option 1is the correct answer
Refer to the exhibit.
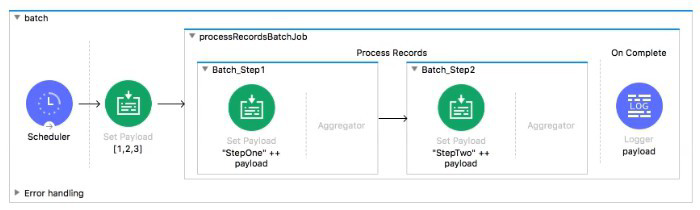
What is the output payload in the On Complete phase
A. summary statistics with NO record data
B. The records processed by the last batch step: [StepTwol, StepTwo2, StepTwo3]
C. The records processed by all batch steps: [StepTwostepOnel, stepTwostepOne2, StepTwoStepOne3]
D. The original payload: [1,2,31
Explanation:
In Mule’s Batch Job, the On Complete phase is designed to emit a summary of execution rather than the transformed record payloads. By default, it collects and outputs statistics such as total records processed, number of successful or failed items, and any errors encountered. It doesn’t return the per-record payloads that were produced in your Batch_Step1 or Batch_Step2.
Even though each record was transformed to values like “StepTwoStepOne1”, the On Complete logger will show only the batch statistics object—not an array of those strings. If you inspect #[payload] in On Complete, you’ll see something like: { recordsProcessed: 3, recordsFailed: 0, // other summary fields… }
To capture the actual record outputs in On Complete, you must explicitly aggregate them during your batch steps (for example using a VM queue or a payload accumulator) and then reference that collection in On Complete. Otherwise, Mule purges the record details once the summary is emitted.
Refer to the exhibit.

What data is expected by the POST /accounts endpoint?
A. Option A
B. Option B
C. Option C
D. Option D
Explanation:
The POST /accounts endpoint in the RAML specification expects a JSON payload with name, address, customer_since (and optionally other fields). Option D matches the exact structure shown in the RAML's example under post (minus id, which is server-generated).
Why Other Options Are Wrong:
A: Includes id (generated by server, not client input).
B: XML format (not JSON, as specified in RAML).
C: XML format + extra field (bank_agent_id) not in RAML example.
What is the difference between a subflow and a sync flow?
A. No difference
B. Subflow has no error handling of its own and sync flow does
C. Sync flow has no error handling of its own and subflow does
D. Subflow is synchronous and sync flow is asynchronous
Explanation:
In MuleSoft, Subflows and Synchronous flows (sync flows) are both reusable flow types, but they behave differently, especially regarding error handling. A Subflow is a lightweight flow that always runs synchronously and shares the error handling context of the calling flow — it cannot have its own error handler. This makes subflows ideal for simple, reusable logic that doesn't need custom error control.
On the other hand, a Sync Flow (also referred to as a regular flow with a flow-ref) can have its own error handling and can be reused like a subflow. Though it also executes synchronously when invoked via flow-ref, it allows for defining custom error handling logic within itself, making it more flexible for complex logic that may need isolation or custom fault tolerance.
This distinction is critical in designing robust Mule applications. If you need custom error handling for a reusable block of logic, a synchronous flow is the better choice. If the logic is straightforward and should share error handling with the parent, a subflow is lighter and easier to use.
Incorrect Options:
A. No difference – Incorrect; error handling behavior differs.
C. Sync flow has no error handling... – Sync flows can have their own error handlers.
D. Subflow is synchronous and sync flow is asynchronous – Both are synchronous by default.
Refer to the exhibits.

A web client sends a POST request to the HTTP Listener with the payload "Hello-". What response is returned to the web client?
What response is returned to the web client?
A. Hello- HTTP-] MS2-Three
B. HTTP-JMS2-Three
C. Helb-JMS1-HTTP-JMS2 -Three
D. Hello-HTTP-Three
Explanation:
The flow processes the initial payload ("Hello-") sequentially:
HTTP POST /data fails (simulated error), triggering the HTTP error handler, which appends "HTTP-".
JMS two then fails, triggering the JMS error handler, which appends "JMS2-".
Finally, the set-payload appends "Three".
Result: "Hello-HTTP-JMS2-Three" (Option A).
Why Other Options Are Wrong:
B: Missing initial "Hello-".
C: Incorrectly includes "JMS1-" (not triggered in this flow).
D: Missing "JMS2-" from the second error handler.
A Batch Job scope has five batch steps. An event processor throws an error in the second batch step because the input data is incomplete. What is the default behavior of the batch job after the error is thrown?
A. All processing of the batch job stops.
B. Event processing continues to the next batch step.
C. Error is ignored
D. Batch is retried
Explanation:
In case of an error , batch job completes in flight steps and stops further processing. MuleSoft Doc Ref : Handling Errors During Batch Job | MuleSoft Documentation The default is all processing will stop but we can change it by Max Failed Record field. General -> Max Failed Records: Mule has three options for handling a record-level error: Finish processing, Continue processing and Continue processing until the batch job accumulates a maximum number of failed records. This behavior can be controlled by Max Failed Records.
The default value is Zero which corresponds to Finish processing. The value -1, corresponds to Continue processing.
The value +ve integer, corresponds to Continue processing until the batch job accumulates a maximum number of failed records.
Refer to exhibits.
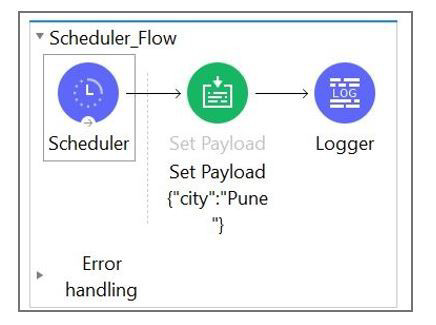
What message should be added to Logger component so that logger prints "The city is Pune" (Double quote should not be part of logged message)?
A. #["The city is" ++ payload.City]
B. The city is + #[payload.City]
C. The city is #[payload.City]
D. #[The city is ${payload.City}
Explanation: Correct answer is The city is #[payload.City] Answer can get confused with the option #["The city is" ++ payload.City] But note that this option will not print the space between is and city name. This will print The city isPune
| Page 3 out of 20 Pages |
| Previous |