In which two scenarios would it be necessary to use Proxy IDs when configuring site-to-site VPN Tunnels? (Choose two.)
A. Firewalls which support policy-based VPNs.
B. The remote device is a non-Palo Alto Networks firewall.
C. Firewalls which support route-based VPNs.
D. The remote device is a Palo Alto Networks firewall.
Explanation:
Proxy IDs are used in IPSec VPN configurations to define the specific traffic selectors (source and destination subnets) that should be protected by the VPN tunnel. They are especially necessary when interoperability or policy-based VPN behavior is involved.
✅ A. Firewalls which support policy-based VPNs
Policy-based VPNs (common in vendors like Fortinet, Cisco ASA, and older Juniper devices) rely on proxy IDs to define which traffic should be encrypted.
Palo Alto Networks firewalls use route-based VPNs, but when connecting to a policy-based peer, proxy IDs must be explicitly configured to match the peer’s expectations.
✅ B. The remote device is a non-Palo Alto Networks firewall
Non-Palo Alto firewalls often require explicit proxy ID definitions to match their encryption domains.
Without matching proxy IDs, the VPN tunnel may establish but traffic won’t flow due to mismatched selectors.
❌ Why C and D Are Incorrect:
C. Firewalls which support route-based VPNs Route-based VPNs (like Palo Alto to Palo Alto) do not require proxy IDs unless there's a specific need to define traffic selectors. They use tunnel interfaces and routing to direct traffic.
D. The remote device is a Palo Alto Networks firewall When both ends are Palo Alto firewalls, proxy IDs are optional. The firewalls can dynamically negotiate traffic selectors unless strict matching is needed for policy enforcement.
🔗 References:
Palo Alto Networks official guide on Proxy ID for IPSec VPN
Ace4Sure PCNSE Practice Question
What action does a firewall take when a Decryption profile allows unsupported modes and unsupported traffic with TLS 1.2 protocol traverses the firewall?
A. It blocks all communication with the server indefinitely.
B. It downgrades the protocol to ensure compatibility.
C. It automatically adds the server to the SSL Decryption Exclusion list
D. It generates an decryption error message but allows the traffic to continue decryption
Explanation:
When you enable SSL Forward Proxy or SSL Inbound Inspection, the firewall needs to decrypt TLS traffic. However, sometimes the firewall can’t decrypt due to unsupported cipher suites, key exchanges, or extensions.
If the Decryption Profile is configured to allow unsupported modes, the firewall won’t break the session.
Instead, it will automatically add the server to the SSL Decryption Exclusion list and allow traffic in a pass-through (not decrypted) mode.
This prevents application breakage while still letting the connection go through.
❌ Why the other options are wrong:
A. Blocks all communication indefinitely
Incorrect. That would only happen if the Decryption Profile was set to block unsupported modes.
B. Downgrades the protocol
The firewall does not downgrade TLS versions; it either decrypts, excludes, or blocks.
D. Generates an error message but continues decryption
Wrong, because if the mode is unsupported, the firewall cannot continue decryption. It must bypass.
📖 Reference:
Palo Alto Networks TechDocs – Decryption Profiles:
A security team has enabled real-time WildFire signature lookup on all its firewalls. Which additional action will further reduce the likelihood of newly discovered malware being allowed through the firewalls?
A. increase the frequency of the applications and threats dynamic updates.
B. Increase the frequency of the antivirus dynamic updates
C. Enable the "Hold Mode" option in Objects > Security Profiles > Antivirus
D. Enable the "Report Grayware Files" option in Device > Setup > WildFire.
Explanation:
Enabling real-time WildFire signature lookup allows Palo Alto Networks firewalls to query the WildFire cloud for the latest verdicts on unknown files before allowing them through. However, this lookup happens in parallel with traffic flow—meaning the file may be delivered before the verdict is returned, potentially allowing malware through.
To further reduce the likelihood of newly discovered malware being allowed:
✅ Enable "Hold Mode" in Antivirus Profiles
This feature pauses file delivery until the WildFire cloud returns a verdict.
If the verdict is malicious, the firewall can block the file before it reaches the user.
This prevents patient zero scenarios where malware is delivered before detection.
You can configure this under:
Objects > Security Profiles > Antivirus
And globally under:
Device > Setup > Content-ID > Real-Time Signature Lookup > Enable Hold Mode
❌ Why Other Options Are Incorrect:
A. Increase the frequency of applications and threats dynamic updates This helps with known threats, but not zero-day malware. Real-time lookup is already faster.
B. Increase the frequency of antivirus dynamic updates Antivirus updates are periodic and reactive. They don’t help with real-time detection.
D. Enable "Report Grayware Files" This improves visibility but doesn’t block malware. It’s a reporting feature, not a prevention mechanism.
🔗 Authoritative Reference:
Palo Alto Networks TechDocs: Hold Mode for WildFire Real-Time Signature Lookup
An administrator is creating a new Dynamic User Group to quarantine users for suspicious activity. Which two objects can Dynamic User Groups use as match conditions for group membership? (Choose two.)
A. Source IP address
B. Dynamic tags
C. Static tags
D. Ldap attributes
Explanation:
A Dynamic User Group (DUG) is a user group whose membership changes automatically based on conditions. It’s especially useful for things like quarantining suspicious users.
DUGs can use the following as match conditions:
Dynamic Tags (B)
Tags can be automatically assigned by policy actions, scripts, or integrations (e.g., a firewall can tag a user if they trigger a threat log).
DUGs can then match on that tag to include the user.
LDAP Attributes (D)
You can build conditions based on user attributes pulled from LDAP (like department, title, group membership).
This allows role- or identity-based dynamic grouping.
❌ Why the others are wrong:
A. Source IP address
DUGs are tied to users, not IPs. While User-ID can map an IP → user, you can’t directly use a source IP as a DUG match condition.
C. Static tags
Static tags don’t change dynamically. DUGs are about changing membership.
You would use Dynamic Tags, not static.
📖 Reference:
Palo Alto Networks TechDocs – Dynamic User Groups:
A company has recently migrated their branch office's PA-220S to a centralized Panorama. This Panorama manages a number of PA-7000 Series and PA-5200 Series devices All device group and template configuration is managed solely within Panorama. They notice that commit times have drastically increased for the PA-220S after the migration. What can they do to reduce commit times?
A. Disable "Share Unused Address and Service Objects with Devices" in Panorama Settings.
B. Update the apps and threat version using device-deployment
C. Perform a device group push using the "merge with device candidate config" option
D. Use "export or push device config bundle" to ensure that the firewall is integrated with the Panorama config.
Explanation:
By default, Panorama shares all objects (addresses, services, app groups, etc.) with all managed firewalls, even if they’re not used.
On small appliances (like PA-220), this leads to long commit times because the device has to process a very large object set — most of which it doesn’t need.
Disabling “Share Unused Address and Service Objects with Devices” tells Panorama to only push objects actually used in policy for that firewall, drastically reducing commit load/time.
This is a best practice when a Panorama manages both large chassis devices and small branch devices.
❌ Why the other options are wrong:
B. Update the apps and threat version using device-deployment
Good maintenance practice, but it has no impact on commit time.
C. Perform a device group push using “merge with device candidate config”
This just changes whether Panorama merges its config with the firewall’s candidate. It doesn’t optimize commit time.
D. Use “export or push device config bundle”
That’s for ensuring initial Panorama-to-firewall config sync, especially after RMA or Panorama migration. It won’t reduce ongoing commit times.
📖 Reference:
Palo Alto TechDocs – Panorama Commit Optimization:
An enterprise Information Security team has deployed policies based on AD groups to restrict user access to critical infrastructure systems. However, a recent phishing campaign against the organization has prompted Information Security to look for more controls that can secure access to critical assets. For users that need to access these systems. Information Security wants to use PAN-OS multi-factor authentication (MFA) integration to enforce MFA. What should the enterprise do to use PAN-OS MFA?
A. Configure a Captive Portal authentication policy that uses an authentication sequence.
B. Configure a Captive Portal authentication policy that uses an authentication profile that references a RADIUS profile.
C. Create an authentication profile and assign another authentication factor to be used by a Captive Portal authentication policy.
D. Use a Credential Phishing agent to detect, prevent, and mitigate credential phishing campaigns.
Explanation:
To enforce multi-factor authentication (MFA) for users accessing critical infrastructure, Palo Alto Networks firewalls use Authentication Policies in conjunction with Captive Portal. The correct approach involves:
Creating an Authentication Profile for the first factor (e.g., LDAP, RADIUS).
Adding an MFA Server Profile for the second factor (e.g., via vendor API or RADIUS).
Configuring a Captive Portal Authentication Policy that references both profiles.
This setup allows the firewall to:
Redirect users to a web form for initial authentication.
Trigger additional authentication factors via integrated MFA services.
Dynamically enforce access control based on user identity and authentication status.
❌ Why Other Options Are Incorrect:
A. Configure a Captive Portal authentication policy that uses an authentication sequence Authentication sequences are used for fallback across multiple profiles—not for MFA chaining.
B. Configure a Captive Portal authentication policy that uses an authentication profile that references a RADIUS profile This only handles single-factor authentication unless combined with an MFA server profile.
D. Use a Credential Phishing agent to detect, prevent, and mitigate credential phishing campaigns This is a separate feature for threat detection—not for enforcing MFA.
🔗 Authoritative Reference:
Palo Alto Networks TechDocs: Configure Multi-Factor Authentication
An engineer needs to collect User-ID mappings from the company's existing proxies. What two methods can be used to pull this data from third party proxies? (Choose two.)
A. Client probing
B. Syslog
C. XFF Headers
D. Server Monitoring
Explanation:
This question tests your knowledge of how the Palo Alto Networks firewall integrates with third-party systems to gather User-ID information, specifically when a proxy server is involved in the traffic path.
The Core Concept: User-ID from Proxies
In a network where all user traffic flows through a proxy server, the firewall often only sees the proxy's IP address as the source of traffic. To apply user-based policies, the firewall needs to learn which user is behind the proxy's IP address at any given time. The firewall has specific methods to extract this user-to-IP mapping information from proxy servers.
Analyzing the Correct Options:
Why Option B (Syslog) is Correct:
This is the most common and reliable method for integrating with third-party proxies.
How it works: The proxy server is configured to send its audit or access logs to the Palo Alto Networks firewall via syslog (typically on UDP port 514). These logs contain entries that tie a username to an internal IP address.
The firewall's User-ID agent includes a Syslog Parser. You configure this parser with a specific regular expression to "teach" the firewall how to read the proxy's log format and extract the key fields: timestamp, username, and IP address.
Example: A syslog entry from a proxy might look like:
2023-10-27 10:15:30 user=jdoe src=192.168.1.100 url=example.com
The regex would be built to capture jdoe as the user and 192.168.1.100 as the IP.
Once parsed, the firewall adds this mapping to its User-IP mapping table and can apply policies based on the user jdoe.
Why Option C (XFF Headers) is Correct:
1.X-Forwarded-For (XFF) is a standard HTTP header used by proxies, load balancers, and other intermediaries to identify the originating IP address of a client connecting to a web server.
2.How it works: When the proxy forwards an HTTP/HTTPS request to the destination server, it adds an X-Forwarded-For: header containing the original client's IP address.
The Palo Alto Networks firewall can be configured to monitor this header. In the User-ID configuration (Device > User Identification > User Mapping > Monitor HTTP Headers), you can enable monitoring for the X-Forwarded-For header.
When the firewall sees traffic from the proxy's IP address and detects an X-Forwarded-For header with an IP inside it, it can map that internal IP to the user. This mapping is often combined with another method (like captive portal or client probing) to finally get the username for that IP.
Why the Other Options Are Incorrect:
Why Option A (Client Probing) is Incorrect:
1.Client Probing (or WMI probing) is a method where the firewall directly queries Windows hosts (via WMI) or UNIX hosts (via SSH) to ask "which user is logged in?"
This method bypasses the proxy. It queries the endpoint directly on the network. It does not "pull data from" the proxy itself. The question specifically asks for methods to get data from the third-party proxies.
Why Option D (Server Monitoring) is Incorrect:
1.Server Monitoring is a method where the firewall monitors authentication logs directly from servers (e.g., Windows Event Logs from a Domain Controller via WMI or syslog from a RADIUS server).
2.Similar to client probing, this method gets data from the authentication source or the endpoint, not from the proxy server. The proxy is not involved in this data collection method.
Reference and Key Concepts for the PCNSE Exam:
1.Primary Use Case:
The classic scenario for using these methods is when the firewall is deployed in front of a proxy server (e.g., a forward proxy in a DMZ). All internal users egress through this proxy, so the firewall only sees the proxy's IP. To apply user-based policies, it must learn the mappings from the proxy.
2.GUI Path for Syslog Parsing:
Device > User Identification > User Mapping > Add Syslog Parsing Rule
3.GUI Path for HTTP Header Monitoring:
Device > User Identification > User Mapping > Monitor HTTP Headers
4.Combination of Methods:
Often, you use both methods together. The firewall uses the XFF header to learn the internal IP address of the user behind the proxy. It then uses another method (like client probing or server monitoring) to map that internal IP address to a specific username.
5Key Differentiator:
Remember, if the question is about getting data from the proxy itself, the answers will always revolve around syslog and HTTP headers.
A firewall administrator is configuring an IPSec tunnel between Site A and Site B. The Site
A firewall uses a DHCP assigned address on the outside interface of the firewall, and the
Site B firewall uses a static IP address assigned to the outside interface of the firewall.
However, the use of dynamic peering is not working.
Refer to the two sets of configuration settings provided. Which two changes will allow the
configurations to work? (Choose two.)
Site A configuration: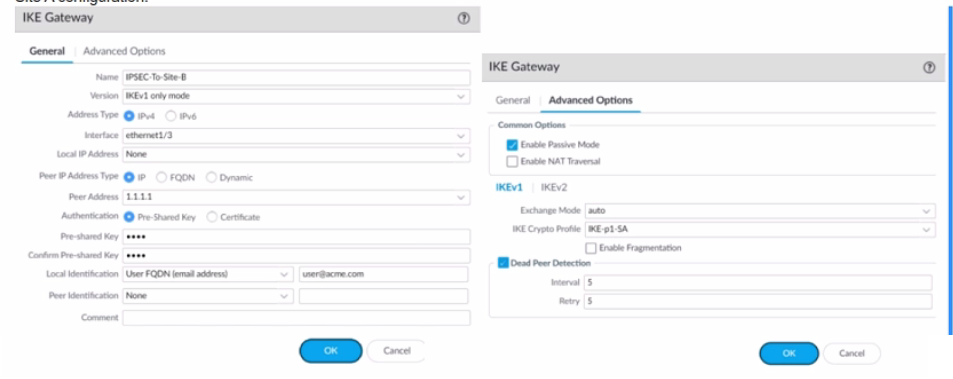
A. Enable NAT Traversal on Site B firewall
B. Configure Local Identification on Site firewall
C. Disable passive mode on Site A firewall
D. Match IKE version on both firewalls.
Explanation:
When configuring a VPN tunnel with a dynamic peer, specific settings must be matched on both sides of the connection to ensure successful negotiation.
A. Enable NAT Traversal on Site B firewall: NAT traversal (NAT-T) is essential when one or both endpoints have a dynamic public IP address and might be behind a NAT device. The Site A firewall uses a DHCP-assigned address, which means its address can change. If the Site B firewall is behind a NAT device or if the connection passes through one, enabling NAT-T ensures that the VPN packets can correctly traverse the NAT boundary. Without this, the connection will likely fail.
D. Match IKE version on both firewalls: The IKE Gateway configuration for Site A shows IKEv1 only mode. For a successful tunnel, the remote peer (Site B) must also be configured to use IKEv1. If Site B is set to IKEv2 or a different mode, the IKE negotiation will fail. Matching the IKE version is a fundamental requirement for any IPSec tunnel setup.
Why the Other Options Are Incorrect
B. Configure Local Identification on Site A firewall:
The provided image of the Site A configuration already shows that the Local Identification is configured as FQDN (email address) with the value user@acme.com. No change is needed for this setting.
C. Disable passive mode on Site A firewall:
The "Passive Mode" option on the Site A configuration is currently disabled (unchecked). Passive mode would cause the firewall to only listen for incoming connections and not initiate the connection itself. Since Site A has a dynamic IP address, it must be the initiator of the tunnel, so disabling passive mode is the correct setting. Therefore, this option does not require a change.
A root cause analysis investigation into a recent security incident reveals that several decryption rules have been disabled. The security team wants to generate email alerts when decryption rules are changed. How should email log forwarding be configured to achieve this goal?
A. With the relevant configuration log filter inside Device > Log Settings
B. With the relevant system log filter inside Objects > Log Forwarding
C. With the relevant system log filter inside Device > Log Settings
D. With the relevant configuration log filter inside Objects > Log Forwarding
Explanation:
To generate email alerts when decryption rules are changed, you need to monitor configuration logs, because changes to security policies—including decryption rules—are recorded as configuration events.
The correct place to configure this is:
Device > Log Settings
Under Configuration Logs, apply a filter that matches changes to decryption rules.
Set up email forwarding for those filtered logs.
This ensures that any modification, disabling, or deletion of decryption rules triggers an email alert to the security team.
❌ Why Other Options Are Incorrect:
B. System log filter inside Objects > Log Forwarding System logs capture operational events, not configuration changes.
C. System log filter inside Device > Log Settings Again, system logs don’t track policy changes.
D. Configuration log filter inside Objects > Log Forwarding You must configure log forwarding for configuration logs under Device > Log Settings, not under Objects.
🔗 Authoritative Reference:
PUPUWEB: Configuring Email Alerts for Decryption Rule Changes
A network security engineer is going to enable Zone Protection on several security zones How can the engineer ensure that Zone Protection events appear in the firewall's logs?
A. Select the check box "Log packet-based attack events" in the Zone Protection profile
B. No action is needed Zone Protection events appear in the threat logs by default
C. Select the check box "Log Zone Protection events" in the Content-ID settings of the firewall
D. Access the CLI in each firewall and enter the command set system setting additionalthreat- log on
Explanation:
Zone Protection profiles defend against floods, reconnaissance, and packet-based attacks (e.g., SYN flood, malformed packets).
To actually see these events in the Threat log, you must check “Log packet-based attack events” inside the Zone Protection profile.
If you don’t enable this option, the firewall enforces the protection but does not generate a log entry.
❌ Why the others are wrong:
B. No action is needed; Zone Protection events appear in the threat logs by default
Incorrect. Zone Protection actions don’t log unless explicitly enabled.
C. "Log Zone Protection events" in Content-ID settings
There is no such setting in Content-ID. Logging is controlled within the Zone Protection profile.
D. CLI set system setting additionalthreat-log on
This enables additional system logging, but it does not affect Zone Protection logs.
📖 Reference:
Palo Alto TechDocs – Configure Zone Protection:
A firewall administrator has been tasked with ensuring that all Panorama configuration is committed and pushed to the devices at the end of the day at a certain time. How can they achieve this?
A. Use the Scheduled Config Push to schedule Commit to Panorama and also Push to Devices.
B. Use the Scheduled Config Push to schedule Push to Devices and separately schedule an API call to commit all Panorama changes.
C. Use the Scheduled Config Export to schedule Push to Devices and separately schedule an API call to commit all Panorama changes
D. Use the Scheduled Config Export to schedule Commit to Panorama and also Push to Devices
Explanation:
Panorama provides a Scheduled Config Push feature.
With it, you can:
Commit to Panorama (save changes to Panorama’s running config), and
Push to Devices (send the committed Panorama config down to managed firewalls).
You can schedule both actions to happen automatically at a specified time (e.g., end of day).
That exactly matches the requirement: ensure all Panorama configuration is committed and pushed to devices at a certain time.
❌ Why the other options are wrong:
B. Scheduled Config Push + API call
Overcomplicates it. Panorama already supports scheduled commit and push natively—no API scripting needed.
C. Scheduled Config Export + API call
Config Export only saves/exports the config to a file; it doesn’t commit or push to devices. Wrong feature.
D. Scheduled Config Export to commit and push
Same issue—Config Export is about saving, not applying configs.
📖 Reference:
Palo Alto TechDocs – Schedule a Config Push
An administrator is attempting to create policies tor deployment of a device group and template stack. When creating the policies, the zone drop down list does not include the required zone. What must the administrator do to correct this issue?
A. Specify the target device as the master device in the device group
B. Enable "Share Unused Address and Service Objects with Devices" in Panorama settings
C. Add the template as a reference template in the device group
D. Add a firewall to both the device group and the template
Explanation:
In Panorama, when creating policies for a device group and template stack, the zone dropdown list will only show zones that are defined in the template and associated with a firewall. If no firewall is added to both the device group and the template, Panorama cannot correlate the zone definitions with a real device, and the dropdown will appear incomplete.
To fix this:
Ensure that the firewall is added to both:
The device group (for policy management)
The template (for interface and zone definitions)
This allows Panorama to correctly populate zone objects in the policy editor.
❌ Why Other Options Are Incorrect:
A. Specify the target device as the master device in the device group This is used for reference configuration comparison, not for zone population.
B. Enable "Share Unused Address and Service Objects with Devices" This affects object sharing, not zone visibility.
C. Add the template as a reference template in the device group Reference templates are used for inheritance, not for linking zones to policies.
🔗 Reference:
Exam4Training PCNSE Question
Palo Alto Networks KB: New Zone Not Visible in Panorama
| Page 11 out of 27 Pages |
| 789101112131415 |
| PCNSE Practice Test Home |
Real-World Scenario Mastery: Our PCNSE practice exam don't just test definitions. They present you with the same complex, scenario-based problems you'll encounter on the actual exam.
Strategic Weakness Identification: Each practice session reveals exactly where you stand. Discover which domains need more attention, before Palo Alto Networks Certified Security Engineer (PCNSE) PAN-OS 10.2 exam day arrives.
Confidence Through Familiarity: There's no substitute for knowing what to expect. When you've worked through our comprehensive PCNSE practice exam questions pool covering all topics, the real exam feels like just another practice session.
Copyright © All Rights Reserved