A developer creates an Integration Procedure with a Set Values and a DataRaptor Extract Action that requires AccountId as a key. When the developer previews the Integration Procedure, thedeveloper enters the AccountId correctly and execute the Preview. The developer sees the data extract by the DataRaptor in the Debug Log, but the response is empty. What is the likely cause of this issue?
A. The DataRaptor Action did not have the add response Ro Response JSON property set to true.
B. The Response cannot be previewed directly.
C. A Response Action was not added to the integration Procedure.
D. The AccountId used for the preview is invalid.
Summary
The issue is that while the DataRaptor runs successfully (as seen in the Debug Log), its extracted data is not being included in the final response of the Integration Procedure. An Integration Procedure's response is built by explicitly defining what data to return. Without a final step to package the data, the procedure will execute all actions but return an empty JSON object to the calling client.
Correct Option
C. A Response Action was not added to the Integration Procedure.
The Response Action is a dedicated element that must be the final step in an Integration Procedure. Its purpose is to define the structure of the JSON response. Even if previous actions like a DataRaptor Extract run correctly and store data in the pipeline, this data is not automatically sent back. Without a Response Action to map the pipeline data into the response, the output will always be empty.
Incorrect Option
A. The DataRaptor Action did not have the Add Response To Response JSON property set to true.
This property is used to merge a DataRaptor's output directly into the final response JSON, which can be useful in specific cases. However, it is not the primary or required method for returning data. A properly configured Response Action can return the data regardless of this setting on the individual DataRaptor action.
B. The Response cannot be previewed directly.
This is incorrect. The Preview tab for an Integration Procedure is specifically designed to show the final JSON response. If the Integration Procedure is configured correctly with a Response Action, the preview will display the returned data. The ability to preview the response is a core feature of the tool.
D. The AccountId used for the preview is invalid.
The scenario states that the developer "sees the data extracted by the DataRaptor in the Debug Log." This is definitive proof that the DataRaptor ran successfully and found data for the provided AccountId. If the ID were invalid, the DataRaptor would have returned an empty result or an error, which would be visible in the debug log.
Reference
Salesforce OmniStudio Developer Guide: Response Action
A developer needs tocreateDataRaptor to retrieve the name of an account for a contact. Following best practices, how should a developer configure the extraction steps?
A. Define an extraction step for the Contact object and set the Extract JSON Path to Contact Account.Name
B. Define extraction steps for the Contact and the Account objects, and set the Extract JSON Path to Contact Account.Name
C. Define extraction steps for the Contact and the Account objects, and set the Extract 3SON Path to Account.Name
D. Define an extractionstep for the Account object, and set the Extract JSON Path to AccountContact.Name
Summary
The requirement is to retrieve a field (Name) from a parent object (Account) for a starting record (Contact). In a DataRaptor, this is accomplished by leveraging a lookup relationship. The correct approach is to define the extraction starting from the source object (Contact) and then use a JSON Path that traverses the relationship field (Account) to the target field (Name), without needing separate extraction steps for each object.
Correct Option
A. Define an extraction step for the Contact object and set the Extract JSON Path to Contact.Account.Name
This is the correct and most efficient best practice. A single DataRaptor Extract step starting from the Contact object can traverse the Account relationship to get the Account.Name using the JSONPath Contact.Account.Name. The DataRaptor internally handles the SOQL join, eliminating the need for multiple, manually configured extraction steps and simplifying the configuration.
Incorrect Option
B. Define extraction steps for the Contact and the Account objects, and set the Extract JSON Path to Contact.Account.Name
This is redundant and not a best practice. Defining a separate step for the Account object is unnecessary because the relationship from Contact to Account can be traversed directly in the JSON Path within a single step. Multiple steps would complicate the DataRaptor without providing any benefit for this simple lookup.
C. Define extraction steps for the Contact and the Account objects, and set the Extract JSON Path to Account.Name
This is incorrect. The JSON Path Account.Name is not rooted in the starting object of the extraction. The first step is based on the Contact object, so the pipeline data at that point is a Contact record. Referring directly to Account.Name without the Contact. prefix would be invalid as the context is wrong.
D. Define an extraction step for the Account object, and set the Extract JSON Path to Account.Contact.Name
This reverses the relationship logic. The requirement is to start from a Contact and get its parent Account's name. This option starts from the Account and tries to traverse to a child Contact (Account.Contact.Name), which is not a standard relationship and would not work. The relationship is Contact.Account, not Account.Contact.
Reference
Salesforce OmniStudio Developer Guide: Configure a DataRaptor Extract
A developer creates a Flexcardthat displaysa contact’s mailing address and passes the contact’s postal code to a child FlexCard. When configuration text elements in the child FlexCard, what syntax should a developer use to refer to the contact’s postal code?
A. {Postalcode}
B. {Parent.postalcode}
C. {Records.postalcode}
D. {Params.postalcode}
Summary
In OmniStudio, when data is passed from a parent component to a child component, such as from a parent FlexCard to a child FlexCard, it is received as a parameter. The child component does not directly access the parent's data context. Instead, it must reference the specific parameter name that was defined in the data passing configuration. The syntax to reference these passed-in values uses the Params namespace.
Correct Option
D. {Params.postalcode}
This is the correct syntax. The Params object is the designated namespace for accessing any data passed into a FlexCard from an external source, including a parent card. When the parent card passes the postal code, it becomes a named parameter in the child card's context. Using {Params.postalcode} (or the exact parameter name defined in the action) allows the child card's text element to correctly display the received value.
Incorrect Option
A. {Postalcode}
This syntax would only work if "Postalcode" were a field on the base record that the child FlexCard is directly querying for itself. Since the data is being passed from the parent, it exists in the parameters collection, not in the root data context of the child card.
B. {Parent.postalcode}
There is no built-in Parent namespace for directly accessing a parent component's data within a child FlexCard. Data must be explicitly passed from parent to child using parameters. This syntax is invalid and will not resolve to any value.
C. {Records.postalcode}
The Records namespace is typically used within the parent FlexCard itself to reference fields from the record(s) it queried. A child card does not automatically inherit this context. The child card must receive the data via parameters and then reference it using Params.
Reference
Salesforce OmniStudio Developer Guide: Configure Actions for a FlexCard
A developer has a requirement to create a child FlexCard that contains all of its parent FlexCard’s records In a Datable How should the developer configure the parent FlexCard’s Node?
A. {Records {0}}
B. {Records}
C. {Params, records}
D. {Recorded}
Summary
To pass all records from a parent FlexCard to a child FlexCard, the developer must reference the correct data context node from the parent's data source. The parent FlexCard's query typically returns a collection of records, which is stored in a default node. The child component needs access to this entire collection to display it in its own DataTable.
Correct Option
B. {Records}
This is the correct node to use. In a parent FlexCard, the {Records} node represents the root array of records returned by the card's DataRaptor or query. By setting this as the source in the parent's action configuration, the entire collection of records is passed to the child card. The child card can then bind its DataTable directly to the received parameter, which will now contain the full set of data.
Incorrect Option
A. {Records[0]}
This syntax refers only to the first record ([0]) within the {Records} array. Passing this would send a single object representing the first record to the child card, not the entire collection. The child's DataTable would not have the full list of records to display.
C. {Params.records}
The Params namespace is used within a child component to access data passed into it. In the parent card's configuration, you reference your own local data context ({Records}), not a Params object. Using {Params.records} in the parent would imply the parent is expecting to receive data, which is the reverse of the intended data flow.
D. {Recorded}
This is an invalid and non-existent node within the OmniStudio context. The standard and reserved node name for the collection of records in a FlexCard is {Records}. Using {Recorded} would result in no data being passed to the child card.
Reference
Salesforce OmniStudio Developer Guide: Configure Actions for a FlexCard
A developer is troubleshooting an Integration Procedure with two elements: A Remote Action named FetchCart and a Response Action namedResponseCart.
In Preview, what JSON node shows the data sent to the Response Action?
A. FetchCart
B. Response
C. ResponseCartDebug
D. ResponseCart
Summary
When previewing an Integration Procedure, the output panel shows a detailed JSON structure representing the execution. Each element in the procedure has its own node containing its specific result. The Response Action is the final element that defines the procedure's output, and its results are displayed in a node named after the action itself, allowing developers to verify the exact data being returned.
Correct Option
D. ResponseCart
This is the correct node. In the Integration Procedure's preview debug output, each action has a dedicated JSON node named after the action's "Name" property. The ResponseCart node will contain the final, structured JSON output as defined by the mapping within that specific Response Action. This is the definitive data that the Integration Procedure would send back to the calling OmniScript or application.
Incorrect Option
A. FetchCart
The FetchCart node shows the input, output, and debug information for the Remote Action, not the Response Action. It displays the request sent to the external service and the raw response received from it, which is the data that will be fed into the pipeline for the Response Action to use.
B. Response
While "Response" is the type of the action, it is not the node name used in the debug output. The preview uses the custom name assigned to the action instance by the developer (in this case, ResponseCart), not its generic type. The node Response does not exist in this context.
C. ResponseCartDebug
This is a fabricated node name. The debug output does not append "Debug" to action names. The primary output and result of the Response Action named ResponseCart is contained directly within the ResponseCart node itself.
Reference
Salesforce OmniStudio Developer Guide: Test an Integration Procedure
A developer creates a DataRaptor Extract to retrieve data to pass to an external service. The external service expects the field value to be an integer. However, the DataRaptor is sending it as a string. Which action can the developer take to fix this?
A. In the DataRaptor Output tab, select the Output Data Type of that field to Integer.
B. In the DataRaptor Output tab, enter the default value as 0 on the field.
C. In the DataRaptor Extract tab, set the Input Data Type field to Integer.
D. In the DataRaptor Formula tab, define a formula using the function TOINTEGER and usethe formula as output.
E.
Summary
The issue is a data type mismatch where a field value extracted from Salesforce is being cast as a string in the resulting JSON, but the external service requires an integer. The solution requires actively converting the data type before it is placed in the output. This type conversion is not handled by simple configuration in the Output tab but requires a data manipulation step.
Correct Option
D. In the DataRaptor Formula tab, define a formula using the function TOINTEGER and use the formula as output.
This is the correct and most direct solution. The Formula tab allows you to apply functions to your data. By creating a formula that uses the TOINTEGER() function on the source field, you explicitly convert the string value to a number. You then map this formula's result to the output field instead of the original source field, ensuring the JSON contains an integer.
Incorrect Option
A. In the DataRaptor Output tab, select the Output Data Type of that field to Integer.
The "Output Data Type" dropdown in the Output tab (e.g., String, Number, Boolean) is primarily for documentation and has limited functional impact on the actual JSON structure for basic extracts. It does not reliably perform type conversion. The field will often still be serialized as a string in the final JSON output.
B. In the DataRaptor Output tab, enter the default value as 0 on the field.
Setting a default value only provides a fallback if the source field is null or empty. It does not change the data type of an existing value. If the source field contains the string "123", the default value is ignored, and "123" is still sent as a string. This does not solve the type conversion problem.
C. In the DataRaptor Extract tab, set the Input Data Type field to Integer.
The "Input Data Type" in the Extract tab defines the data type of the parameters being passed into the DataRaptor (e.g., the filter value). It has no effect on the data type of the fields being extracted from the Salesforce object and output by the DataRaptor.
Reference
Salesforce OmniStudio Developer Guide: DataRaptor Formula Functions
A developer is building an OmniScript and needs to retrieve data from a single field in a Salesforce record. Which OmniScript element does this?
A. Lookup
B. Select
C. HTTP Action
D. DataRaptor Post Action
Summary
The requirement is to retrieve data for a single field from a Salesforce record directly within an OmniScript. This is a common need for populating a field based on a selected record ID, such as getting an Account's phone number after an Account Id is entered. The element must perform a lightweight, real-time data lookup without the overhead of a full DataRaptor or external call.
Correct Option
A. Lookup
The Lookup element is specifically designed for this purpose. It is a dual-purpose element that provides a searchable interface to find a record and, upon selection, can automatically populate other fields on the OmniScript with data from that selected record. Its "Pre-fill Field Mappings" property allows a developer to map a field from the selected record (e.g., Account.Phone) to a field in the OmniScript, efficiently retrieving the value for a single field.
Incorrect Option
B. Select
The Select element is used to present a static or dynamically sourced list of options for a user to choose from (like a picklist). It does not perform a real-time data retrieval from a Salesforce record based on an ID. It is for user selection, not for auto-populating field values from a database.
C. HTTP Action
An HTTP Action is used to call an external REST API or web service. It is not the right tool for a simple, internal data retrieval from a Salesforce record. Using it for this purpose would be overly complex, require custom Apex, and violate the principle of using the simplest tool for the job.
D. DataRaptor Post Action
A DataRaptor Post Action is used to create, update, or upsert records in the database. It is a data loading tool, not a data retrieval tool. For extracting a single field value, a DataRaptor Extract would be more appropriate, but even that is more heavyweight than a Lookup element for this specific single-field use case.
Reference
Salesforce OmniStudio Developer Guide: Lookup Element
A developer writes an OmniScript that includes a DataRaptor that updates the Account status based on information provided from the OmniScript. The information must be updated only if the Account record already exists. Otherwise, a new account must be created. How should the developer accomplish this task?
A. Check the Upsert Key checkbox on the Account Status field
B. Check the Upsert Key and Is Required for Upsert check boxes on the Account Id field
C. Populate the Lookup Object and Lookup Fields
D. Check Overwrite Target for All Null Inputs checkbox on the Account Id field
Summary
The requirement is to update an existing Account if it exists, or create a new one if it does not. This is the definition of an "upsert" operation. In a DataRaptor Load, an upsert requires specifying a unique field to match on (the Upsert Key). The Account Id (the Salesforce record ID) is the standard field for this, as it uniquely identifies an existing record. If provided, the record is updated; if not, a new one is created.
Correct Option
B. Check the Upsert Key and Is Required for Upsert checkboxes on the Account Id field
This is the correct configuration. Checking Upsert Key on the Account Id field tells the DataRaptor to use this field to find an existing record. Checking Is Required for Upsert ensures the upsert logic is dependent on this field. If the OmniScript provides an Account Id, the existing record is updated. If the Account Id is null/empty, the DataRaptor will create a new Account record, fulfilling the requirement.
Incorrect Option
A. Check the Upsert Key checkbox on the Account Status field
Using the "Account Status" field as the Upsert Key is incorrect. The upsert key must be a unique identifier for the record, like the Id or a custom external ID field. "Account Status" is a data field that is not unique, so using it as a key would cause errors or update the wrong record if multiple accounts shared the same status.
C. Populate the Lookup Object and Lookup Fields
The Lookup fields in a DataRaptor are used to populate a relationship field on the record being saved (e.g., looking up a Contact to set the AccountId on an Opportunity). They are not used to determine whether to update an existing record or create a new one. This is unrelated to the upsert operation.
D. Check Overwrite Target for All Null Inputs checkbox on the Account Id field
This setting controls how null values from the input are handled during an update. If checked, a null input would overwrite an existing value on the target record with null. It has no bearing on the core logic of deciding between an insert or an update (upsert).
Reference
Salesforce OmniStudio Developer Guide: Configure a DataRaptor Load
A developer needs to limit the of a DataRaptor Extract to a maximum of one result. How should the developer configure this?
A. Define a formula with the Filter function
B. Use a Custom Output Type when creating the DataRaptor
C. Use the LIMIT filter on the Extract definition
D. Set the Limit Property on the Action that calls the DataRaptor Extract.
E.
Summary
To limit the number of records returned by a DataRaptor Extract, the configuration must be applied within the DataRaptor itself. This ensures the limit is enforced at the database query level, which is the most efficient approach. Applying the limit at the source reduces the data volume processed by the platform and guarantees that only the specified number of records is ever retrieved, regardless of how the DataRaptor is called.
Correct Option
C. Use the LIMIT filter on the Extract definition
This is the correct and most efficient method. In the DataRaptor Extract's configuration, under the "Filter" section, you can add a LIMIT clause. Setting this to 1 ensures the underlying SOQL query includes LIMIT 1, so the database returns only one record at most. This is a best practice as it optimizes performance by restricting results at the source.
Incorrect Option
A. Define a formula with the Filter function
Formula functions operate on data after it has been retrieved from the database. Using a FILTER function would first fetch all records matching the query and then apply the limit in memory. This is inefficient for large data sets and does not prevent the performance cost of initially retrieving multiple records.
B. Use a Custom Output Type when creating the DataRaptor
The Custom Output Type determines the structure of the returned JSON (e.g., "SObject" vs. "Custom"). It does not have a setting to limit the number of records returned by the query. This configuration is unrelated to result set sizing.
D. Set the Limit Property on the Action that calls the DataRaptor Extract.
There is no standard "Limit" property on the Integration Procedure or OmniScript action that calls a DataRaptor. The limiting logic must be defined within the DataRaptor's own configuration. The calling action can pass parameters to the DataRaptor but cannot directly impose a row limit on its results.
Reference
Salesforce OmniStudio Developer Guide: Configure a DataRaptor Extract
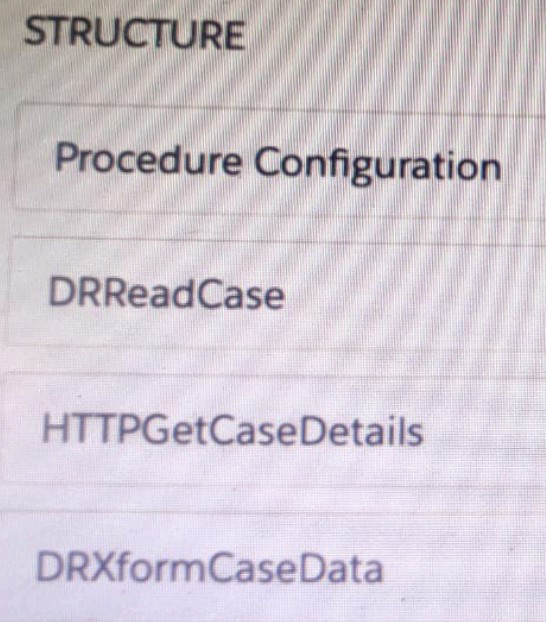
Refer to the exhibit below. What is the marge code needed for this integration procedure structure to pass a CaseNumber node from theDRReadCase DataRaptor Extract Action to the HTTP Action’s HTTP URL?
A. %DRReadCase: CaseNumber%
B. ((DRRCase, CaseNumber))
C. MTTOPDetCaseDetail: CaseNumber%
D. ((CaseNumber))
Summary
In an Integration Procedure, data is passed between actions through a data pipeline. To reference an output from a previous action, you use a merge field syntax. The correct syntax follows a specific pattern that identifies the source action and the specific data node you want to access. This allows you to dynamically build values, such as a URL, with data retrieved earlier in the procedure's execution.
Correct Option
A. %DRReadCase:CaseNumber%
This is the correct merge field syntax for referencing data from a previous action within an Integration Procedure. It uses percent signs % to denote the merge field, followed by the name of the previous action (DRReadCase), a colon :, and the name of the specific output node from that action (CaseNumber). This tells the Integration Procedure to insert the value of the CaseNumber from the DRReadCase action's output into the HTTP URL.
Incorrect Option
B. ((DRRCase,CaseNumber))
This syntax is invalid. It uses parentheses and a comma, which are not part of the standard merge field syntax in Integration Procedures. The correct format uses percent signs and a colon as the delimiter.
C. %HTTPGetCaseDetails:CaseNumber%
This is incorrect because it references the HTTPGetCaseDetails action, which is the action that needs the value, not the action that provides it. The DRReadCase action occurs before HTTPGetCaseDetails in the procedure flow, so only DRReadCase's output is available at the time the HTTP Action is configured.
D. ((CaseNumber))
This syntax is incomplete and incorrect. It does not specify which action in the procedure is the source of the CaseNumber data. Without specifying the source action (e.g., DRReadCase), the Integration Procedure cannot resolve where to get the value from.
Reference
Salesforce OmniStudio Developer Guide: Integration Procedure Data Pipelining
Which two of these options can a developer use to retrieve data from a Salesforce object?
(Choose 2 answers)
A. A DataRaptor Load Action
B. A DataRaptor Extract Action
C. A Lookup Input Element
D. A DataRapt or Post Action
Summary
Retrieving data from a Salesforce object involves querying and reading records. In OmniStudio, specific tools are designed for this purpose. The correct options will be components whose primary function is to fetch data from the database and make it available within the OmniScript or Integration Procedure, as opposed to components designed for writing data or capturing user input.
Correct Option
B. A DataRaptor Extract Action
This is a primary tool for data retrieval. A DataRaptor Extract is explicitly designed to read data from one or more Salesforce objects. It can be configured with SOQL-like filters and relationships to return specific sets of data, which can then be used to populate an OmniScript or be processed within an Integration Procedure.
C. A Lookup Input Element
The Lookup element serves a dual purpose. While it provides a user interface to search for a record, it also automatically retrieves and pre-fills data from the selected record into other fields on the OmniScript. This inherently involves querying and reading data from a Salesforce object based on the user's selection.
Incorrect Option
A. A DataRaptor Load Action
A DataRaptor Load Action is used for writing data to the database. Its purpose is to create, update, or upsert records in a Salesforce object. It does not retrieve data for use in the application; it persists data from the application to the database.
D. A DataRaptor Post Action
This is not a standard OmniStudio action type. "DataRaptor Post" is likely a distractor and is not a recognized category. DataRaptors are categorized as Extract, Transform, or Load. There is no "Post" type, and if it refers to anything, it would be synonymous with a Load action, which is for data creation/update, not retrieval.
Reference
Salesforce OmniStudio Developer Guide: DataRaptor Extract
A developer configures a FlexCard with a Data Mapper data source that uses the
params.id as an input. When the developer clicks "View Data" on the FlexCard, valid data
displays. However, when the developer previews the layout, the FlexCard does not display.
What could cause this error? Choose 2 answers
A. The Record Id in the Test Data Source Settings is for the wrong record type
B. There is no Salesforce record for the FlexCard based on the RecordId in the layout's Test Data Source Settings.
C. The Data Node field for the FlexCard is empty.
D. The Attributes haven't been configured to pass the data to the fields.
Explanation:
B. No Salesforce record for the RecordId in Test Data Source Settings
The Test Data Source Settings in a FlexCard layout determine which record is used during preview.
If the RecordId provided doesn’t exist in Salesforce (or points to a deleted/nonexistent record), the FlexCard will fail to display in preview.
This explains why “View Data” works (it uses the Data Mapper directly with params.id), but preview fails (it relies on the layout’s test settings).
C. Data Node field is empty
The Data Node defines the root of the JSON structure that the FlexCard binds to.
If the Data Node field is left empty, the FlexCard has no reference point to map the incoming data to its UI elements.
Result: Even though data is retrieved, nothing is displayed in the FlexCard preview.
❌ Why not A or D?
A. Wrong RecordId type → If the RecordId is of the wrong type, Salesforce would still return data (or an error). The key issue here is no record at all, not wrong type.
D. Attributes not configured → Attributes are used to pass data between parent and child FlexCards or OmniScripts. In this case, the FlexCard is directly bound to the Data Mapper, so missing attributes wouldn’t prevent display.
📚 Reference
Salesforce OmniStudio Docs: FlexCards Data Source Configuration
Key principle: FlexCard preview depends on valid Test Data Source settings and a properly defined Data Node.
👉 Memory tip for the exam:
If “View Data” works but preview fails → check Test Data Source settings and Data Node.
| Page 2 out of 15 Pages |
| 12345 |
| OmniStudio-Developer Practice Test Home |
Real-World Scenario Mastery: Our OmniStudio-Developer practice exam don't just test definitions. They present you with the same complex, scenario-based problems you'll encounter on the actual exam.
Strategic Weakness Identification: Each practice session reveals exactly where you stand. Discover which domains need more attention, before Salesforce Certified OmniStudio Developer - Plat-Dev-210 exam day arrives.
Confidence Through Familiarity: There's no substitute for knowing what to expect. When you've worked through our comprehensive OmniStudio-Developer practice exam questions pool covering all topics, the real exam feels like just another practice session.
Copyright © All Rights Reserved