A company wants to classify user behavior as either fraudulent or normal. Based on
internal research, a Machine Learning Specialist would like to build a binary classifier
based on two features: age of account and transaction month. The class distribution for
these features is illustrated in the figure provided.
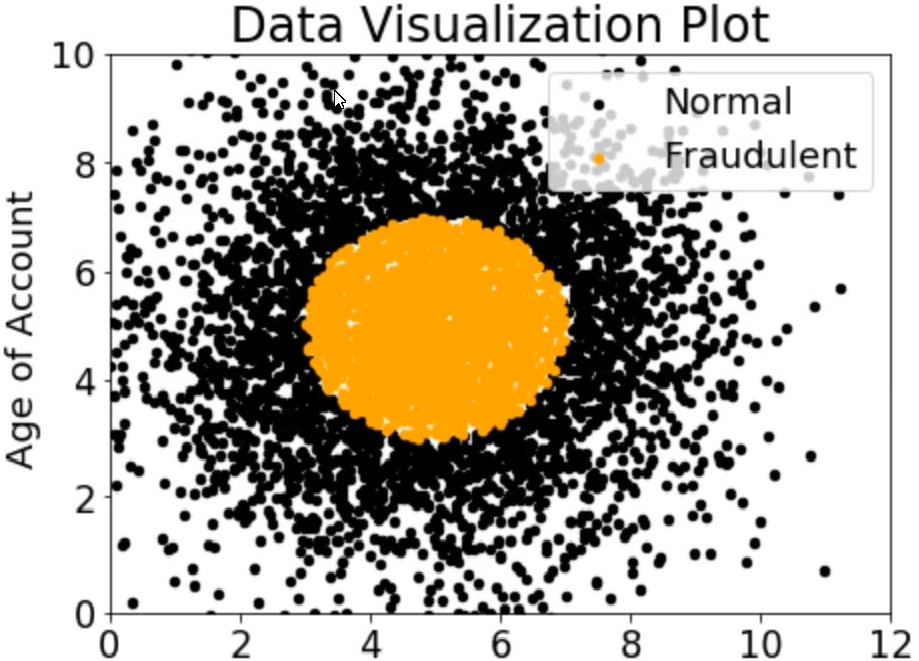
Based on this information which model would have the HIGHEST accuracy?
A. Long short-term memory (LSTM) model with scaled exponential linear unit (SELL))
B. Logistic regression
C. Support vector machine (SVM) with non-linear kernel
D. Single perceptron with tanh activation function
Explanation: Based on the figure provided, the data is not linearly separable. Therefore, a non-linear model such as SVM with a non-linear kernel would be the best choice. SVMs are particularly effective in high-dimensional spaces and are versatile in that they can be used for both linear and non-linear data. Additionally, SVMs have a high level of accuracy and are less prone to overfitting.
A Data Scientist is developing a binary classifier to predict whether a patient has a particular disease on a series of test results. The Data Scientist has data on 400 patients randomly selected from the population. The disease is seen in 3% of the population. Which cross-validation strategy should the Data Scientist adopt?
A. A k-fold cross-validation strategy with k=5
B. A stratified k-fold cross-validation strategy with k=5
C. A k-fold cross-validation strategy with k=5 and 3 repeats
D. An 80/20 stratified split between training and validation
Explanation: A stratified k-fold cross-validation strategy is a technique that preserves the class distribution in each fold. This is important for imbalanced datasets, such as the one in the question, where the disease is seen in only 3% of the population. If a random k-fold cross-validation strategy is used, some folds may have no positive cases or very few, which would lead to poor estimates of the model performance. A stratified k-fold cross validation strategy ensures that each fold has the same proportion of positive and negative cases as the whole dataset, which makes the evaluation more reliable and robust. A k-fold cross-validation strategy with k=5 and 3 repeats is also a possible option, but it is more computationally expensive and may not be necessary if the stratification is done properly. An 80/20 stratified split between training and validation is another option, but it uses less data for training and validation than k-fold cross-validation, which may result in higher variance and lower accuracy of the estimates.
A trucking company is collecting live image data from its fleet of trucks across the globe. The data is growing rapidly and approximately 100 GB of new data is generated every day. The company wants to explore machine learning uses cases while ensuring the data is only accessible to specific IAM users. Which storage option provides the most processing flexibility and will allow access control with IAM?
A. Use a database, such as Amazon DynamoDB, to store the images, and set the IAM policies to restrict access to only the desired IAM users.
B. Use an Amazon S3-backed data lake to store the raw images, and set up the permissions using bucket policies.
C. Setup up Amazon EMR with Hadoop Distributed File System (HDFS) to store the files, and restrict access to the EMR instances using IAM policies.
D. Configure Amazon EFS with IAM policies to make the data available to Amazon EC2 instances owned by the IAM users.
Explanation: The best storage option for the trucking company is to use an Amazon S3- backed data lake to store the raw images, and set up the permissions using bucket policies. A data lake is a centralized repository that allows you to store all your structured and unstructured data at any scale. Amazon S3 is the ideal choice for building a data lake because it offers high durability, scalability, availability, and security. You can store any type of data in Amazon S3, such as images, videos, audio, text, etc. You can also use AWS services such as Amazon Rekognition, Amazon SageMaker, and Amazon EMR to analyze and process the data in the data lake. To ensure the data is only accessible to specific IAM users, you can use bucket policies to grant or deny access to the S3 buckets based on the IAM user’s identity or role. Bucket policies are JSON documents that specify the permissions for the bucket and the objects in it. You can use conditions to restrict access based on various factors, such as IP address, time, source, etc. By using bucket policies, you can control who can access the data in the data lake and what actions they can perform on it.
A machine learning (ML) specialist is administering a production Amazon SageMaker endpoint with model monitoring configured. Amazon SageMaker Model Monitor detects violations on the SageMaker endpoint, so the ML specialist retrains the model with the latest dataset. This dataset is statistically representative of the current production traffic. The ML specialist notices that even after deploying the new SageMaker model and running the first monitoring job, the SageMaker endpoint still has violations. What should the ML specialist do to resolve the violations?
A. Manually trigger the monitoring job to re-evaluate the SageMaker endpoint traffic sample.
B. Run the Model Monitor baseline job again on the new training set. Configure Model Monitor to use the new baseline.
C. Delete the endpoint and recreate it with the original configuration.
D. Retrain the model again by using a combination of the original training set and the new training set.
Explanation: The ML specialist should run the Model Monitor baseline job again on the new training set and configure Model Monitor to use the new baseline. This is because the baseline job computes the statistics and constraints for the data quality and model quality metrics, which are used to detect violations. If the training set changes, the baseline job should be updated accordingly to reflect the new distribution of the data and the model performance. Otherwise, the old baseline may not be representative of the current production traffic and may cause false alarms or miss violations.
A company is observing low accuracy while training on the default built-in image classification algorithm in Amazon SageMaker. The Data Science team wants to use an Inception neural network architecture instead of a ResNet architecture. Which of the following will accomplish this? (Select TWO.)
A. Customize the built-in image classification algorithm to use Inception and use this for model training.
B. Create a support case with the SageMaker team to change the default image classification algorithm to Inception.
C. Bundle a Docker container with TensorFlow Estimator loaded with an Inception network and use this for model training.
D. Use custom code in Amazon SageMaker with TensorFlow Estimator to load the model with an Inception network and use this for model training.
E. Download and apt-get install the inception network code into an Amazon EC2 instance and use this instance as a Jupyter notebook in Amazon SageMaker.
Explanation: The best options to use an Inception neural network architecture instead of a
ResNet architecture for image classification in Amazon SageMaker are:
A manufacturing company has structured and unstructured data stored in an Amazon S3 bucket A Machine Learning Specialist wants to use SQL to run queries on this data. Which solution requires the LEAST effort to be able to query this data?
A. Use AWS Data Pipeline to transform the data and Amazon RDS to run queries.
B. Use AWS Glue to catalogue the data and Amazon Athena to run queries
C. Use AWS Batch to run ETL on the data and Amazon Aurora to run the quenes
D. Use AWS Lambda to transform the data and Amazon Kinesis Data Analytics to run queries
Explanation: AWS Glue is a serverless data integration service that can catalogue, clean, enrich, and move data between various data stores. Amazon Athena is an interactive query service that can run SQL queries on data stored in Amazon S3. By using AWS Glue to catalogue the data and Amazon Athena to run queries, the Machine Learning Specialist can leverage the existing data in Amazon S3 without any additional data transformation or loading. This solution requires the least effort compared to the other options, which involve more complex and costly data processing and storage services.
A retail company is using Amazon Personalize to provide personalized product recommendations for its customers during a marketing campaign. The company sees a significant increase in sales of recommended items to existing customers immediately after deploying a new solution version, but these sales decrease a short time after deployment. Only historical data from before the marketing campaign is available for training. How should a data scientist adjust the solution?
A. Use the event tracker in Amazon Personalize to include real-time user interactions.
B. Add user metadata and use the HRNN-Metadata recipe in Amazon Personalize.
C. Implement a new solution using the built-in factorization machines (FM) algorithm in Amazon SageMaker.
D. Add event type and event value fields to the interactions dataset in Amazon Personalize.
Explanation: The best option is to use the event tracker in Amazon Personalize to include
real-time user interactions. This will allow the model to learn from the feedback of the
customers during the marketing campaign and adjust the recommendations accordingly.
The event tracker can capture click-through, add-to-cart, purchase, and other types of
events that indicate the user’s preferences. By using the event tracker, the company can
improve the relevance and freshness of the recommendations and avoid the decrease in
sales.
The other options are not as effective as using the event tracker. Adding user metadata
and using the HRNN-Metadata recipe in Amazon Personalize can help capture the user’s
attributes and preferences, but it will not reflect the changes in user behavior during the
marketing campaign. Implementing a new solution using the built-in factorization machines
(FM) algorithm in Amazon SageMaker can also provide personalized recommendations,
but it will require more time and effort to train and deploy the model. Adding event type and
event value fields to the interactions dataset in Amazon Personalize can help capture the
importance and context of each interaction, but it will not update the model with the latest
user feedback.
A Data Scientist is developing a machine learning model to classify whether a financial
transaction is fraudulent. The labeled data available for training consists of 100,000 nonfraudulent
observations and 1,000 fraudulent observations.
The Data Scientist applies the XGBoost algorithm to the data, resulting in the following
confusion matrix when the trained model is applied to a previously unseen validation
dataset. The accuracy of the model is 99.1%, but the Data Scientist has been asked to
reduce the number of false negatives.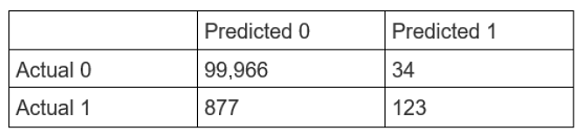
Which combination of steps should the Data Scientist take to reduce the number of false
positive predictions by the model? (Select TWO.)
A. Change the XGBoost eval_metric parameter to optimize based on rmse instead of error.
B. Increase the XGBoost scale_pos_weight parameter to adjust the balance of positive and negative weights.
C. Increase the XGBoost max_depth parameter because the model is currently underfitting the data.
D. Change the XGBoost evaljnetric parameter to optimize based on AUC instead of error.
E. Decrease the XGBoost max_depth parameter because the model is currently overfitting the data.
Explanation:
The XGBoost algorithm is a popular machine learning technique for classification
problems. It is based on the idea of boosting, which is to combine many weak
learners (decision trees) into a strong learner (ensemble model).
The XGBoost algorithm can handle imbalanced data by using
the scale_pos_weight parameter, which controls the balance of positive and
negative weights in the objective function. A typical value to consider is the ratio of
negative cases to positive cases in the data. By increasing this parameter, the
algorithm will pay more attention to the minority class (positive) and reduce the
number of false negatives.
The XGBoost algorithm can also use different evaluation metrics to optimize the
model performance. The default metric is error, which is the misclassification rate.
However, this metric can be misleading for imbalanced data, as it does not
account for the different costs of false positives and false negatives. A better
metric to use is AUC, which is the area under the receiver operating characteristic
(ROC) curve. The ROC curve plots the true positive rate against the false positive
rate for different threshold values. The AUC measures how well the model can
distinguish between the two classes, regardless of the threshold. By changing
the eval_metric parameter to AUC, the algorithm will try to maximize the AUC
score and reduce the number of false negatives.
Therefore, the combination of steps that should be taken to reduce the number of
false negatives are to increase the scale_pos_weight parameter and change
the eval_metric parameter to AUC.
A company needs to quickly make sense of a large amount of data and gain insight from it. The data is in different formats, the schemas change frequently, and new data sources are added regularly. The company wants to use AWS services to explore multiple data sources, suggest schemas, and enrich and transform the data. The solution should require the least possible coding effort for the data flows and the least possible infrastructure management. Which combination of AWS services will meet these requirements?
A. Amazon EMR for data discovery, enrichment, and transformation
Amazon Athena for querying and analyzing the results in Amazon S3 using standard SQL
Amazon QuickSight for reporting and getting insights
B. Amazon Kinesis Data Analytics for data ingestion
Amazon EMR for data discovery, enrichment, and transformation
Amazon Redshift for querying and analyzing the results in Amazon S3
C. AWS Glue for data discovery, enrichment, and transformation
Amazon Athena for querying and analyzing the results in Amazon S3 using standard SQL
Amazon QuickSight for reporting and getting insights
D. AWS Data Pipeline for data transfer
AWS Step Functions for orchestrating AWS Lambda jobs for data discovery, enrichment,
and transformation
Amazon Athena for querying and analyzing the results in Amazon S3 using standard SQL
Amazon QuickSight for reporting and getting insights
Explanation: The best combination of AWS services to meet the requirements of data
discovery, enrichment, transformation, querying, analysis, and reporting with the least
coding and infrastructure management is AWS Glue, Amazon Athena, and Amazon
QuickSight. These services are:
AWS Glue for data discovery, enrichment, and transformation. AWS Glue is a
serverless data integration service that automatically crawls, catalogs, and
prepares data from various sources and formats. It also provides a visual interface
called AWS Glue DataBrew that allows users to apply over 250 transformations to
clean, normalize, and enrich data without writing code1.
Amazon Athena for querying and analyzing the results in Amazon S3 using
standard SQL. Amazon Athena is a serverless interactive query service that allows
users to analyze data in Amazon S3 using standard SQL. It supports a variety of
data formats, such as CSV, JSON, ORC, Parquet, and Avro. It also integrates with
AWS Glue Data Catalog to provide a unified view of the data sources and
schemas2.
Amazon QuickSight for reporting and getting insights. Amazon QuickSight is a
serverless business intelligence service that allows users to create and share
interactive dashboards and reports. It also provides ML-powered features, such as
anomaly detection, forecasting, and natural language queries, to help users
discover hidden insights from their data3.
The other options are not suitable because they either require more coding effort, more
infrastructure management, or do not support the desired use cases. For example:
Option A uses Amazon EMR for data discovery, enrichment, and transformation.
Amazon EMR is a managed cluster platform that runs Apache Spark, Apache
Hive, and other open-source frameworks for big data processing. It requires users
to write code in languages such as Python, Scala, or SQL to perform data
integration tasks. It also requires users to provision, configure, and scale the
clusters according to their needs4.
Option B uses Amazon Kinesis Data Analytics for data ingestion. Amazon Kinesis
Data Analytics is a service that allows users to process streaming data in real time
using SQL or Apache Flink. It is not suitable for data discovery, enrichment, and
transformation, which are typically batch-oriented tasks. It also requires users to
write code to define the data processing logic and the output destination5.
Option D uses AWS Data Pipeline for data transfer and AWS Step Functions for
orchestrating AWS Lambda jobs for data discovery, enrichment, and
transformation. AWS Data Pipeline is a service that helps users move data
between AWS services and on-premises data sources. AWS Step Functions is a
service that helps users coordinate multiple AWS services into workflows. AWS
Lambda is a service that lets users run code without provisioning or managing
servers. These services require users to write code to define the data sources,
destinations, transformations, and workflows. They also require users to manage
the scalability, performance, and reliability of the data pipelines.
A company needs to deploy a chatbot to answer common questions from customers. The chatbot must base its answers on company documentation. Which solution will meet these requirements with the LEAST development effort?
A. Index company documents by using Amazon Kendra. Integrate the chatbot with Amazon Kendra by using the Amazon Kendra Query API operation to answer customer questions.
B. Train a Bidirectional Attention Flow (BiDAF) network based on past customer questions and company documents. Deploy the model as a real-time Amazon SageMaker endpoint. Integrate the model with the chatbot by using the SageMaker Runtime InvokeEndpoint API operation to answer customer questions.
C. Train an Amazon SageMaker BlazingText model based on past customer questions and company documents. Deploy the model as a real-time SageMaker endpoint. Integrate the model with the chatbot by using the SageMaker Runtime InvokeEndpoint API operation to answer customer questions.
D. Index company documents by using Amazon OpenSearch Service. Integrate the chatbot with OpenSearch Service by using the OpenSearch Service k-nearest neighbors (k-NN) Query API operation to answer customer questions.
Explanation: The solution A will meet the requirements with the least development effort
because it uses Amazon Kendra, which is a highly accurate and easy to use intelligent
search service powered by machine learning. Amazon Kendra can index company
documents from various sources and formats, such as PDF, HTML, Word, and more.
Amazon Kendra can also integrate with chatbots by using the Amazon Kendra Query API
operation, which can understand natural language questions and provide relevant answers
from the indexed documents. Amazon Kendra can also provide additional information, such as document excerpts, links, and FAQs, to enhance the chatbot experience1.
The other options are not suitable because:
Option B: Training a Bidirectional Attention Flow (BiDAF) network based on past
customer questions and company documents, deploying the model as a real-time
Amazon SageMaker endpoint, and integrating the model with the chatbot by using
the SageMaker Runtime InvokeEndpoint API operation will incur more
development effort than using Amazon Kendra. The company will have to write the
code for the BiDAF network, which is a complex deep learning model for question
answering. The company will also have to manage the SageMaker endpoint, the
model artifact, and the inference logic2.
Option C: Training an Amazon SageMaker BlazingText model based on past
customer questions and company documents, deploying the model as a real-time
SageMaker endpoint, and integrating the model with the chatbot by using the
SageMaker Runtime InvokeEndpoint API operation will incur more development
effort than using Amazon Kendra. The company will have to write the code for the
BlazingText model, which is a fast and scalable text classification and word
embedding algorithm. The company will also have to manage the SageMaker
endpoint, the model artifact, and the inference logic3.
Option D: Indexing company documents by using Amazon OpenSearch Service
and integrating the chatbot with OpenSearch Service by using the OpenSearch
Service k-nearest neighbors (k-NN) Query API operation will not meet the
requirements effectively. Amazon OpenSearch Service is a fully managed service
that provides fast and scalable search and analytics capabilities. However, it is not
designed for natural language question answering, and it may not provide accurate
or relevant answers for the chatbot. Moreover, the k-NN Query API operation is
used to find the most similar documents or vectors based on a distance function,
not to find the best answers based on a natural language query4.
A Machine Learning Specialist is building a convolutional neural network (CNN) that will classify 10 types of animals. The Specialist has built a series of layers in a neural network that will take an input image of an animal, pass it through a series of convolutional and pooling layers, and then finally pass it through a dense and fully connected layer with 10 nodes The Specialist would like to get an output from the neural network that is a probability distribution of how likely it is that the input image belongs to each of the 10 classes. Which function will produce the desired output?
A. Dropout
B. Smooth L1 loss
C. Softmax
D. Rectified linear units (ReLU)
Explanation: The softmax function is a function that can transform a vector of arbitrary real values into a vector of real values in the range (0,1) that sum to 1. This means that the softmax function can produce a valid probability distribution over multiple classes. The softmax function is often used as the activation function of the output layer in a neural network, especially for multi-class classification problems. The softmax function can assign higher probabilities to the classes with higher scores, which allows the network to make predictions based on the most likely class. In this case, the Machine Learning Specialist wants to get an output from the neural network that is a probability distribution of how likely it is that the input image belongs to each of the 10 classes of animals. Therefore, the softmax function is the most suitable function to produce the desired output.
A retail company wants to build a recommendation system for the company's website. The system needs to provide recommendations for existing users and needs to base those recommendations on each user's past browsing history. The system also must filter out any items that the user previously purchased. Which solution will meet these requirements with the LEAST development effort?
A. Train a model by using a user-based collaborative filtering algorithm on Amazon SageMaker. Host the model on a SageMaker real-time endpoint. Configure an Amazon API Gateway API and an AWS Lambda function to handle real-time inference requests that the web application sends. Exclude the items that the user previously purchased from the results before sending the results back to the web application.
B. Use an Amazon Personalize PERSONALIZED_RANKING recipe to train a model. Create a real-time filter to exclude items that the user previously purchased. Create and deploy a campaign on Amazon Personalize. Use the GetPersonalizedRanking API operation to get the real-time recommendations.
C. Use an Amazon Personalize USER_ PERSONAL IZATION recipe to train a model Create a real-time filter to exclude items that the user previously purchased. Create and deploy a campaign on Amazon Personalize. Use the GetRecommendations API operation to get the real-time recommendations.
D. Train a neural collaborative filtering model on Amazon SageMaker by using GPU instances. Host the model on a SageMaker real-time endpoint. Configure an Amazon API Gateway API and an AWS Lambda function to handle real-time inference requests that the web application sends. Exclude the items that the user previously purchased from the results before sending the results back to the web application.
Explanation: Amazon Personalize is a fully managed machine learning service that makes it easy for developers to create personalized user experiences at scale. It uses the same recommender system technology that Amazon uses to create its own personalized recommendations. Amazon Personalize provides several pre-built recipes that can be used to train models for different use cases. The USER_PERSONALIZATION recipe is designed to provide personalized recommendations for existing users based on their past interactions with items. The PERSONALIZED_RANKING recipe is designed to re-rank a list of items for a user based on their preferences. The USER_PERSONALIZATION recipe is more suitable for this use case because it can generate recommendations for each user without requiring a list of candidate items. To filter out the items that the user previously purchased, a real-time filter can be created and applied to the campaign. A real-time filter is a dynamic filter that uses the latest interaction data to exclude items from the recommendations. By using Amazon Personalize, the development effort is minimized because it handles the data processing, model training, and deployment automatically. The web application can use the GetRecommendations API operation to get the real-time recommendations from the campaign.
| Page 7 out of 26 Pages |
| 345678910 |
| MLS-C01 Practice Test Home |
Real-World Scenario Mastery: Our MLS-C01 practice exam don't just test definitions. They present you with the same complex, scenario-based problems you'll encounter on the actual exam.
Strategic Weakness Identification: Each practice session reveals exactly where you stand. Discover which domains need more attention, before AWS Certified Machine Learning - Specialty exam day arrives.
Confidence Through Familiarity: There's no substitute for knowing what to expect. When you've worked through our comprehensive MLS-C01 practice exam questions pool covering all topics, the real exam feels like just another practice session.
Copyright © All Rights Reserved