A manufacturing company has a large set of labeled historical sales data The manufacturer would like to predict how many units of a particular part should be produced each quarter Which machine learning approach should be used to solve this problem?
A. Logistic regression
B. Random Cut Forest (RCF)
C. Principal component analysis (PCA)
D. Linear regression
Explanation: Linear regression is a machine learning approach that can be used to solve this problem. Linear regression is a supervised learning technique that can model the relationship between one or more input variables (features) and an output variable (target). In this case, the input variables could be the historical sales data of the part, such as the quarter, the demand, the price, the inventory, etc. The output variable could be the number of units to be produced for the part. Linear regression can learn the coefficients (weights) of the input variables that best fit the output variable, and then use them to make predictions for new data. Linear regression is suitable for problems that involve continuous and numeric output variables, such as predicting house prices, stock prices, or sales volumes.
A company wants to detect credit card fraud. The company has observed that an average of 2% of credit card transactions are fraudulent. A data scientist trains a classifier on a year's worth of credit card transaction data. The classifier needs to identify the fraudulent transactions. The company wants to accurately capture as many fraudulent transactions as possible. Which metrics should the data scientist use to optimize the classifier? (Select TWO.)
A. Specificity
B. False positive rate
C. Accuracy
D. Fl score
E. True positive rate
Explanation: The F1 score is a measure of the harmonic mean of precision and recall, which are both important for fraud detection. Precision is the ratio of true positives to all predicted positives, and recall is the ratio of true positives to all actual positives. A high F1 score indicates that the classifier can correctly identify fraudulent transactions and avoid false negatives. The true positive rate is another name for recall, and it measures the proportion of fraudulent transactions that are correctly detected by the classifier. A high true positive rate means that the classifier can capture as many fraudulent transactions as possible.
A data scientist uses Amazon SageMaker Data Wrangler to analyze and visualize data.
The data scientist wants to refine a training dataset by selecting predictor variables that are
strongly predictive of the target variable. The target variable correlates with other predictor
variables.
The data scientist wants to understand the variance in the data along various directions in
the feature space.
Which solution will meet these requirements?
A. Use the SageMaker Data Wrangler multicollinearity measurement features with a variance inflation factor (VIF) score. Use the VIF score as a measurement of how closely the variables are related to each other.
B. Use the SageMaker Data Wrangler Data Quality and Insights Report quick model visualization to estimate the expected quality of a model that is trained on the data.
C. Use the SageMaker Data Wrangler multicollinearity measurement features with the principal component analysis (PCA) algorithm to provide a feature space that includes all of the predictor variables.
D. Use the SageMaker Data Wrangler Data Quality and Insights Report feature to review features by their predictive power.
Explanation: Principal Component Analysis (PCA) is a dimensionality reduction technique
that captures the variance within the feature space, helping to understand the directions in
which data varies most. In SageMaker Data Wrangler, the multicollinearity measurement
and PCA features allow the data scientist to analyze interdependencies between predictor
variables while reducing redundancy. PCA transforms correlated features into a set of
uncorrelated components, helping to simplify the dataset without significant loss of
information, making it ideal for refining features based on variance.
Options A and D offer methods to understand feature relevance but are less effective for
managing multicollinearity and variance representation in the data.
An e commerce company wants to launch a new cloud-based product recommendation feature for its web application. Due to data localization regulations, any sensitive data must not leave its on-premises data center, and the product recommendation model must be trained and tested using nonsensitive data only. Data transfer to the cloud must use IPsec. The web application is hosted on premises with a PostgreSQL database that contains all the data. The company wants the data to be uploaded securely to Amazon S3 each day for model retraining. How should a machine learning specialist meet these requirements?
A. Create an AWS Glue job to connect to the PostgreSQL DB instance. Ingest tables without sensitive data through an AWS Site-to-Site VPN connection directly into Amazon S3.
B. Create an AWS Glue job to connect to the PostgreSQL DB instance. Ingest all data through an AWS Site- to-Site VPN connection into Amazon S3 while removing sensitive data using a PySpark job.
C. Use AWS Database Migration Service (AWS DMS) with table mapping to select PostgreSQL tables with no sensitive data through an SSL connection. Replicate data directly into Amazon S3.
D. Use PostgreSQL logical replication to replicate all data to PostgreSQL in Amazon EC2 through AWS Direct Connect with a VPN connection. Use AWS Glue to move data from Amazon EC2 to Amazon S3.
Explanation: The best option is to use AWS Database Migration Service (AWS DMS) with
table mapping to select PostgreSQL tables with no sensitive data through an SSL
connection. Replicate data directly into Amazon S3. This option meets the following
requirements:
The other options are not as effective or feasible as the option above. Creating an AWS
Glue job to connect to the PostgreSQL DB instance and ingest data through an AWS Siteto-
Site VPN connection directly into Amazon S3 is possible, but it requires more steps and
resources than using AWS DMS. Also, it does not specify how to filter out the sensitive
data from the tables. Creating an AWS Glue job to connect to the PostgreSQL DB instance
and ingest all data through an AWS Site-to-Site VPN connection into Amazon S3 while
removing sensitive data using a PySpark job is also possible, but it is more complex and
error-prone than using AWS DMS. Also, it does not use IPsec as required. Using
PostgreSQL logical replication to replicate all data to PostgreSQL in Amazon EC2 through
AWS Direct Connect with a VPN connection, and then using AWS Glue to move data from
Amazon EC2 to Amazon S3 is not feasible, because PostgreSQL logical replication does
not support replicating only a subset of data4. Also, it involves unnecessary data
movement and additional costs.
A Machine Learning Specialist receives customer data for an online shopping website. The data includes demographics, past visits, and locality information. The Specialist must develop a machine learning approach to identify the customer shopping patterns, preferences and trends to enhance the website for better service and smart recommendations. Which solution should the Specialist recommend?
A. Latent Dirichlet Allocation (LDA) for the given collection of discrete data to identify patterns in the customer database.
B. A neural network with a minimum of three layers and random initial weights to identify patterns in the customer database
C. Collaborative filtering based on user interactions and correlations to identify patterns in the customer database
D. Random Cut Forest (RCF) over random subsamples to identify patterns in the customer database
Explanation: Collaborative filtering is a machine learning technique that recommends products or services to users based on the ratings or preferences of other users. This technique is well-suited for identifying customer shopping patterns and preferences because it takes into account the interactions between users and products.
A Machine Learning Specialist is creating a new natural language processing application
that processes a dataset comprised of 1 million sentences The aim is to then run
Word2Vec to generate embeddings of the sentences and enable different types of
predictions -
Here is an example from the dataset
"The quck BROWN FOX jumps over the lazy dog "
Which of the following are the operations the Specialist needs to perform to correctly
sanitize and prepare the data in a repeatable manner? (Select THREE)
A. Perform part-of-speech tagging and keep the action verb and the nouns only
B. Normalize all words by making the sentence lowercase
C. Remove stop words using an English stopword dictionary.
D. Correct the typography on "quck" to "quick."
E. One-hot encode all words in the sentence
F. Tokenize the sentence into words.
Explanation: To prepare the data for Word2Vec, the Specialist needs to perform some
preprocessing steps that can help reduce the noise and complexity of the data, as well as
improve the quality of the embeddings. Some of the common preprocessing steps for
Word2Vec are:
Normalizing all words by making the sentence lowercase: This can help reduce the
vocabulary size and treat words with different capitalizations as the same word.
For example, “Fox” and “fox” should be considered as the same word, not two
different words.
Removing stop words using an English stopword dictionary: Stop words are words
that are very common and do not carry much semantic meaning, such as “the”,
“a”, “and”, etc. Removing them can help focus on the words that are more relevant
and informative for the task.
Tokenizing the sentence into words: Tokenization is the process of splitting a
sentence into smaller units, such as words or subwords. This is necessary for
Word2Vec, as it operates on the word level and requires a list of words as input.
The other options are not necessary or appropriate for Word2Vec:
Performing part-of-speech tagging and keeping the action verb and the nouns
only: Part-of-speech tagging is the process of assigning a grammatical category to
each word, such as noun, verb, adjective, etc. This can be useful for some natural
language processing tasks, but not for Word2Vec, as it can lose some important
information and context by discarding other words.
Correcting the typography on “quck” to “quick”: Typo correction can be helpful for
some tasks, but not for Word2Vec, as it can introduce errors and inconsistencies
in the data. For example, if the typo is intentional or part of a dialect, correcting it
can change the meaning or style of the sentence. Moreover, Word2Vec can learn
to handle typos and variations in spelling by learning similar embeddings for them.
One-hot encoding all words in the sentence: One-hot encoding is a way of
representing words as vectors of 0s and 1s, where only one element is 1 and the
rest are 0. The index of the 1 element corresponds to the word’s position in the
vocabulary. For example, if the vocabulary is [“cat”, “dog”, “fox”], then “cat” can be
encoded as [1, 0, 0], “dog” as [0, 1, 0], and “fox” as [0, 0, 1]. This can be useful for
some machine learning models, but not for Word2Vec, as it does not capture the
semantic similarity and relationship between words. Word2Vec aims to learn
dense and low-dimensional embeddings for words, where similar words have
similar vectors.
A company wants to classify user behavior as either fraudulent or normal. Based on
internal research, a Machine Learning Specialist would like to build a binary classifier
based on two features: age of account and transaction month. The class distribution for
these features is illustrated in the figure provided.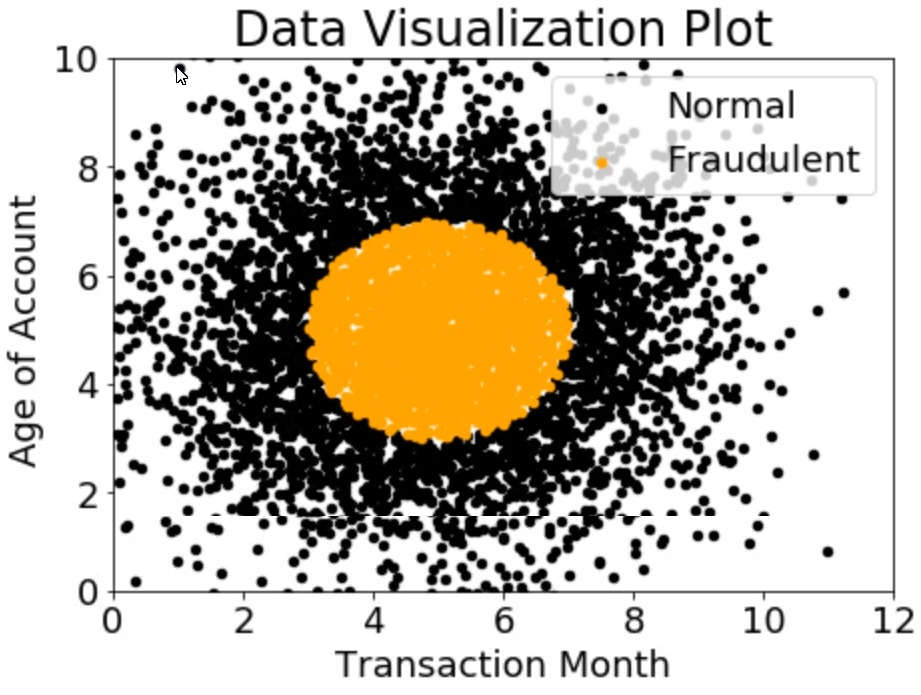
Based on this information, which model would have the HIGHEST recall with respect to the
fraudulent class?
A. Decision tree
B. Linear support vector machine (SVM)
C. Naive Bayesian classifier
D. Single Perceptron with sigmoidal activation function
Explanation: Based on the figure provided, a decision tree would have the highest recall
with respect to the fraudulent class. Recall is a model evaluation metric that measures the
proportion of actual positive instances that are correctly classified by the model. Recall is
calculated as follows:
A large mobile network operating company is building a machine learning model to predict
customers who are likely to unsubscribe from the service. The company plans to offer an
incentive for these customers as the cost of churn is far greater than the cost of the
incentive.
The model produces the following confusion matrix after evaluating on a test dataset of 100
customers:
Based on the model evaluation results, why is this a viable model for production?
A. The model is 86% accurate and the cost incurred by the company as a result of false negatives is less than the false positives.
B. The precision of the model is 86%, which is less than the accuracy of the model.
C. The model is 86% accurate and the cost incurred by the company as a result of false positives is less than the false negatives.
D. The precision of the model is 86%, which is greater than the accuracy of the model.
Explanation: Based on the model evaluation results, this is a viable model for production because the model is 86% accurate and the cost incurred by the company as a result of false positives is less than the false negatives. The accuracy of the model is the proportion of correct predictions out of the total predictions, which can be calculated by adding the true positives and true negatives and dividing by the total number of observations. In this case, the accuracy of the model is (10 + 76) / 100 = 0.86, which means that the model correctly predicted 86% of the customers’ churn status. The cost incurred by the company as a result of false positives and false negatives is the loss or damage that the company suffers when the model makes incorrect predictions. A false positive is when the model predicts that a customer will churn, but the customer actually does not churn. A false negative is when the model predicts that a customer will not churn, but the customer actually churns. In this case, the cost of a false positive is the incentive that the company offers to the customer who is predicted to churn, which is a relatively low cost. The cost of a false negative is the revenue that the company loses when the customer churns, which is a relatively high cost. Therefore, the cost of a false positive is less than the cost of a false negative, and the company would prefer to have more false positives than false negatives. The model has 10 false positives and 4 false negatives, which means that the company’s cost is lower than if the model had more false negatives and fewer false positives.
A Data Engineer needs to build a model using a dataset containing customer credit card information. How can the Data Engineer ensure the data remains encrypted and the credit card information is secure?
A. Use a custom encryption algorithm to encrypt the data and store the data on an Amazon SageMaker instance in a VPC. Use the SageMaker DeepAR algorithm to randomize the credit card numbers.
B. Use an IAM policy to encrypt the data on the Amazon S3 bucket and Amazon Kinesis to automatically discard credit card numbers and insert fake credit card numbers.
C. Use an Amazon SageMaker launch configuration to encrypt the data once it is copied to the SageMaker instance in a VPC. Use the SageMaker principal component analysis (PCA) algorithm to reduce the length of the credit card numbers.
D. Use AWS KMS to encrypt the data on Amazon S3 and Amazon SageMaker, and redact the credit card numbers from the customer data with AWS Glue.
Explanation: AWS KMS is a service that provides encryption and key management for
data stored in AWS services and applications. AWS KMS can generate and manage
encryption keys that are used to encrypt and decrypt data at rest and in transit. AWS KMS
can also integrate with other AWS services, such as Amazon S3 and Amazon SageMaker,
to enable encryption of data using the keys stored in AWS KMS. Amazon S3 is a service
that provides object storage for data in the cloud. Amazon S3 can use AWS KMS to
encrypt data at rest using server-side encryption with AWS KMS-managed keys (SSEKMS).
Amazon SageMaker is a service that provides a platform for building, training, and
deploying machine learning models. Amazon SageMaker can use AWS KMS to encrypt
data at rest on the SageMaker instances and volumes, as well as data in transit between
SageMaker and other AWS services. AWS Glue is a service that provides a serverless
data integration platform for data preparation and transformation. AWS Glue can use AWS
KMS to encrypt data at rest on the Glue Data Catalog and Glue ETL jobs. AWS Glue can
also use built-in or custom classifiers to identify and redact sensitive data, such as credit
card numbers, from the customer data.
The other options are not valid or secure ways to encrypt the data and protect the credit
card information. Using a custom encryption algorithm to encrypt the data and store the
data on an Amazon SageMaker instance in a VPC is not a good practice, as custom
encryption algorithms are not recommended for security and may have flaws or vulnerabilities. Using the SageMaker DeepAR algorithm to randomize the credit card
numbers is not a good practice, as DeepAR is a forecasting algorithm that is not designed
for data anonymization or encryption. Using an IAM policy to encrypt the data on the
Amazon S3 bucket and Amazon Kinesis to automatically discard credit card numbers and
insert fake credit card numbers is not a good practice, as IAM policies are not meant for
data encryption, but for access control and authorization. Amazon Kinesis is a service that
provides real-time data streaming and processing, but it does not have the capability to
automatically discard or insert data values. Using an Amazon SageMaker launch
configuration to encrypt the data once it is copied to the SageMaker instance in a VPC is
not a good practice, as launch configurations are not meant for data encryption, but for
specifying the instance type, security group, and user data for the SageMaker instance.
Using the SageMaker principal component analysis (PCA) algorithm to reduce the length of
the credit card numbers is not a good practice, as PCA is a dimensionality reduction
algorithm that is not designed for data anonymization or encryption.
The Chief Editor for a product catalog wants the Research and Development team to build a machine learning system that can be used to detect whether or not individuals in a collection of images are wearing the company's retail brand The team has a set of training data Which machine learning algorithm should the researchers use that BEST meets their requirements?
A. Latent Dirichlet Allocation (LDA)
B. Recurrent neural network (RNN)
C. K-means
D. Convolutional neural network (CNN)
Explanation: A convolutional neural network (CNN) is a type of machine learning
algorithm that is suitable for image classification tasks. A CNN consists of multiple layers
that can extract features from images and learn to recognize patterns and objects. A CNN
can also use transfer learning to leverage pre-trained models that have been trained on
large-scale image datasets, such as ImageNet, and fine-tune them for specific tasks, such
as detecting the company’s retail brand. A CNN can achieve high accuracy and
performance for image classification problems, as it can handle complex and diverse
images and reduce the dimensionality and noise of the input data. A CNN can be
implemented using various frameworks and libraries, such as TensorFlow, PyTorch, Keras, MXNet, etc.
The other options are not valid or relevant for the image classification task. Latent Dirichlet
Allocation (LDA) is a type of machine learning algorithm that is suitable for topic modeling
tasks. LDA can discover the hidden topics and their proportions in a collection of text
documents, such as news articles, tweets, reviews, etc. LDA is not applicable for image
data, as it requires textual input and output. LDA can be implemented using various
frameworks and libraries, such as Gensim, Scikit-learn, Mallet, etc.
Recurrent neural network (RNN) is a type of machine learning algorithm that is suitable for
sequential data tasks. RNN can process and generate data that has temporal or sequential
dependencies, such as natural language, speech, audio, video, etc. RNN is not optimal for
image data, as it does not capture the spatial features and relationships of the pixels. RNN
can be implemented using various frameworks and libraries, such as TensorFlow, PyTorch,
Keras, MXNet, etc.
K-means is a type of machine learning algorithm that is suitable for clustering tasks. Kmeans
can partition a set of data points into a predefined number of clusters, based on the
similarity and distance between the data points. K-means is not suitable for image
classification tasks, as it does not learn to label the images or detect the objects of interest.
K-means can be implemented using various frameworks and libraries, such as Scikit-learn,
TensorFlow, PyTorch, etc.
A Machine Learning Specialist has completed a proof of concept for a company using a small data sample and now the Specialist is ready to implement an end-to-end solution in AWS using Amazon SageMaker The historical training data is stored in Amazon RDS Which approach should the Specialist use for training a model using that data?
A. Write a direct connection to the SQL database within the notebook and pull data in
B. Push the data from Microsoft SQL Server to Amazon S3 using an AWS Data Pipeline and provide the S3 location within the notebook.
C. Move the data to Amazon DynamoDB and set up a connection to DynamoDB within the notebook to pull data in
D. Move the data to Amazon ElastiCache using AWS DMS and set up a connection within the notebook to pull data in for fast access.
Explanation: Pushing the data from Microsoft SQL Server to Amazon S3 using an AWS Data Pipeline and providing the S3 location within the notebook is the best approach for training a model using the data stored in Amazon RDS. This is because Amazon SageMaker can directly access data from Amazon S3 and train models on it. AWS Data Pipeline is a service that can automate the movement and transformation of data between different AWS services. It can also use Amazon RDS as a data source and Amazon S3 as a data destination. This way, the data can be transferred efficiently and securely without writing any code within the notebook.
A financial services company wants to automate its loan approval process by building a machine learning (ML) model. Each loan data point contains credit history from a thirdparty data source and demographic information about the customer. Each loan approval prediction must come with a report that contains an explanation for why the customer was approved for a loan or was denied for a loan. The company will use Amazon SageMaker to build the model. Which solution will meet these requirements with the LEAST development effort?
A. Use SageMaker Model Debugger to automatically debug the predictions, generate the explanation, and attach the explanation report.
B. Use AWS Lambda to provide feature importance and partial dependence plots. Use the plots to generate and attach the explanation report.
C. Use SageMaker Clarify to generate the explanation report. Attach the report to the predicted results.
D. Use custom Amazon Cloud Watch metrics to generate the explanation report. Attach the report to the predicted results.
Explanation:
The best solution for this scenario is to use SageMaker Clarify to generate the explanation
report and attach it to the predicted results. SageMaker Clarify provides tools to help
explain how machine learning (ML) models make predictions using a model-agnostic
feature attribution approach based on SHAP values. It can also detect and measure
potential bias in the data and the model. SageMaker Clarify can generate explanation
reports during data preparation, model training, and model deployment. The reports include
metrics, graphs, and examples that help understand the model behavior and predictions.
The reports can be attached to the predicted results using the SageMaker SDK or the
SageMaker API.
The other solutions are less optimal because they require more development effort and
additional services. Using SageMaker Model Debugger would require modifying the
training script to save the model output tensors and writing custom rules to debug and
explain the predictions. Using AWS Lambda would require writing code to invoke the ML
model, compute the feature importance and partial dependence plots, and generate and
attach the explanation report. Using custom Amazon CloudWatch metrics would require
writing code to publish the metrics, create dashboards, and generate and attach the
explanation report.
| Page 10 out of 26 Pages |
| 678910111213 |
| MLS-C01 Practice Test Home |
Real-World Scenario Mastery: Our MLS-C01 practice exam don't just test definitions. They present you with the same complex, scenario-based problems you'll encounter on the actual exam.
Strategic Weakness Identification: Each practice session reveals exactly where you stand. Discover which domains need more attention, before AWS Certified Machine Learning - Specialty exam day arrives.
Confidence Through Familiarity: There's no substitute for knowing what to expect. When you've worked through our comprehensive MLS-C01 practice exam questions pool covering all topics, the real exam feels like just another practice session.
Copyright © All Rights Reserved