A set of tests must be performed prior to deploying API implementations to a staging
environment. Due to data security and access restrictions, untested APIs cannot be
granted access to the backend systems, so instead mocked data must be used for these
tests. The amount of available mocked data and its contents is sufficient to entirely test the
API implementations with no active connections to the backend systems. What type of
tests should be used to incorporate this mocked data?
A.
Integration tests
B.
Performance tests
C.
Functional tests (Blackbox)
D.
Unit tests (Whitebox)
Unit tests (Whitebox)
Explanation: Explanation
Correct Answer: Unit tests (Whitebox)
*****************************************
Reference: https://docs.mulesoft.com/mule-runtime/3.9/testing-strategies
As per general IT testing practice and MuleSoft recommended practice, Integration and
Performance tests should be done on full end to end setup for right evaluation. Which
means all end systems should be connected while doing the tests. So, these options are
OUT and we are left with Unit Tests and Functional Tests.
As per attached reference documentation from MuleSoft:
Unit Tests - are limited to the code that can be realistically exercised without the need to
run it inside Mule itself. So good candidates are Small pieces of modular code, Sub Flows,
Custom transformers, Custom components, Custom expression evaluators etc.
Functional Tests - are those that most extensively exercise your application configuration.
In these tests, you have the freedom and tools for simulating happy and unhappy paths.
You also have the possibility to create stubs for target services and make them success or
fail to easily simulate happy and unhappy paths respectively.
As the scenario in the question demands for API implementation to be tested before
deployment to Staging and also clearly indicates that there is enough/ sufficient amount of
mock data to test the various components of API implementations with no active
connections to the backend systems, Unit Tests are the one to be used to incorporate this
When must an API implementation be deployed to an Anypoint VPC?
A.
When the API Implementation must invoke publicly exposed services that are deployed outside of CloudHub in a customer- managed AWS instance
B.
When the API implementation must be accessible within a subnet of a restricted customer-hosted network that does not allow public access
C.
When the API implementation must be deployed to a production AWS VPC using the Mule Maven plugin
D.
When the API Implementation must write to a persistent Object Store
When the API Implementation must invoke publicly exposed services that are deployed outside of CloudHub in a customer- managed AWS instance
Refer to the exhibit.
A developer is building a client application to invoke an API deployed to the STAGING
environment that is governed by a client ID enforcement policy.
What is required to successfully invoke the API?
A.
The client ID and secret for the Anypoint Platform account owning the API in the STAGING environment
B.
The client ID and secret for the Anypoint Platform account's STAGING environment
C.
The client ID and secret obtained from Anypoint Exchange for the API instance in the
STAGING environment
D.
A valid OAuth token obtained from Anypoint Platform and its associated client ID and
secret
The client ID and secret obtained from Anypoint Exchange for the API instance in the
STAGING environment
Explanation: Explanation
Correct Answer: The client ID and secret obtained from Anypoint Exchange for the API
instance in the STAGING environment
*****************************************
>> We CANNOT use the client ID and secret of Anypoint Platform account or any individual
environments for accessing the APIs
>> As the type of policy that is enforced on the API in question is "Client ID Enforcment
Policy", OAuth token based access won't work.
Right way to access the API is to use the client ID and secret obtained from Anypoint
Exchange for the API instance in a particular environment we want to work on.
References:
Managing API instance Contracts on API Manager
https://docs.mulesoft.com/api-manager/1.x/request-access-to-api-task
https://docs.mulesoft.com/exchange/to-request-access
https://docs.mulesoft.com/api-manager/2.x/policy-mule3-client-id-based-policies
What is true about API implementations when dealing with legal regulations that require all data processing to be performed within a certain jurisdiction (such as in the USA or the EU)?
A.
They must avoid using the Object Store as it depends on services deployed ONLY to the US East region
B.
They must use a Jurisdiction-local external messaging system such as Active MQ rather than Anypoint MQ
C.
They must te deployed to Anypoint Platform runtime planes that are managed by Anypoint Platform control planes, with both planes in the same Jurisdiction
D.
They must ensure ALL data is encrypted both in transit and at rest
They must te deployed to Anypoint Platform runtime planes that are managed by Anypoint Platform control planes, with both planes in the same Jurisdiction
Explanation: Explanation
Correct Answer: They must be deployed to Anypoint Platform runtime planes that are
managed by Anypoint Platform control planes, with both planes in the same Jurisdiction.
*****************************************
>> As per legal regulations, all data processing to be performed within a certain jurisdiction.
Meaning, the data in USA should reside within USA and should not go out. Same way, the
data in EU should reside within EU and should not go out.
>> So, just encrypting the data in transit and at rest does not help to be compliant with the
rules. We need to make sure that data does not go out too.
>> The data that we are talking here is not just about the messages that are published to
Anypoint MQ. It includes the apps running, transaction states, application logs, events,
metric info and any other metadata. So, just replacing Anypoint MQ with a locally hosted
ActiveMQ does NOT help.
>> The data that we are talking here is not just about the key/value pairs that are stored in
Object Store. It includes the messages published, apps running, transaction states,
application logs, events, metric info and any other metadata. So, just avoiding using Object
Store does NOT help.
>> The only option left and also the right option in the given choices is to deploy application
on runtime and control planes that are both within the jurisdiction.
An API implementation returns three X-RateLimit-* HTTP response headers to a requesting API client. What type of information do these response headers indicate to the API client?
A.
The error codes that result from throttling
B.
A correlation ID that should be sent in the next request
C.
The HTTP response size
D.
The remaining capacity allowed by the API implementation
The remaining capacity allowed by the API implementation
Explanation: Explanation
Correct Answer: The remaining capacity allowed by the API implementation.
*****************************************
>> Reference: https://docs.mulesoft.com/api-manager/2.x/rate-limiting-and-throttling-slabased-
policies#response-headers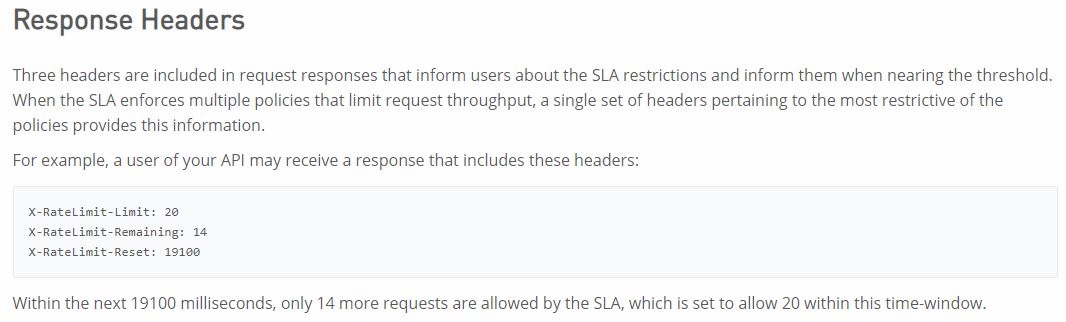
In an organization, the InfoSec team is investigating Anypoint Platform related data traffic. From where does most of the data available to Anypoint Platform for monitoring and alerting originate?
A.
From the Mule runtime or the API implementation, depending on the deployment model
B.
From various components of Anypoint Platform, such as the Shared Load Balancer, VPC, and Mule runtimes
C.
From the Mule runtime or the API Manager, depending on the type of data
D.
From the Mule runtime irrespective of the deployment model
From the Mule runtime irrespective of the deployment model
Explanation: Explanation
Correct Answer: From the Mule runtime irrespective of the deployment model
*****************************************
>> Monitoring and Alerting metrics are always originated from Mule Runtimes irrespective
of the deployment model.
>> It may seems that some metrics (Runtime Manager) are originated from Mule Runtime
and some are (API Invocations/ API Analytics) from API Manager. However, this is
realistically NOT TRUE. The reason is, API manager is just a management tool for API
instances but all policies upon applying on APIs eventually gets executed on Mule
Runtimes only (Either Embedded or API Proxy).
>> Similarly all API Implementations also run on Mule Runtimes.
So, most of the day required for monitoring and alerts are originated fron Mule Runtimes
only irrespective of whether the deployment model is MuleSoft-hosted or Customer-hosted
or Hybrid.
A retail company with thousands of stores has an API to receive data about purchases and
insert it into a single database. Each individual store sends a batch of purchase data to the
API about every 30 minutes. The API implementation uses a database bulk insert
command to submit all the purchase data to a database using a custom JDBC driver
provided by a data analytics solution provider. The API implementation is deployed to a
single CloudHub worker. The JDBC driver processes the data into a set of several
temporary disk files on the CloudHub worker, and then the data is sent to an analytics
engine using a proprietary protocol. This process usually takes less than a few minutes.
Sometimes a request fails. In this case, the logs show a message from the JDBC driver
indicating an out-of-file-space message. When the request is resubmitted, it is successful.
What is the best way to try to resolve this throughput issue?
A.
se a CloudHub autoscaling policy to add CloudHub workers
B.
Use a CloudHub autoscaling policy to increase the size of the CloudHub worker
C.
Increase the size of the CloudHub worker(s)
D.
Increase the number of CloudHub workers
Increase the number of CloudHub workers
Explanation: Explanation
Correct Answer: Increase the size of the CloudHub worker(s)
*****************************************
The key details that we can take out from the given scenario are:
>> API implementation uses a database bulk insert command to submit all the purchase
data to a database
>> JDBC driver processes the data into a set of several temporary disk files on the
CloudHub worker
>> Sometimes a request fails and the logs show a message indicating an out-of-file-space
message
Based on above details:
>> Both auto-scaling options does NOT help because we cannot set auto-scaling rules
based on error messages. Auto-scaling rules are kicked-off based on CPU/Memory usages
and not due to some given error or disk space issues.
>> Increasing the number of CloudHub workers also does NOT help here because the
reason for the failure is not due to performance aspects w.r.t CPU or Memory. It is due to
disk-space.
>> Moreover, the API is doing bulk insert to submit the received batch data. Which means,
all data is handled by ONE worker only at a time. So, the disk space issue should be
tackled on "per worker" basis. Having multiple workers does not help as the batch may still
fail on any worker when disk is out of space on that particular worker.
Therefore, the right way to deal this issue and resolve this is to increase the vCore size of
the worker so that a new worker with more disk space will be provisioned.
What Mule application deployment scenario requires using Anypoint Platform Private Cloud Edition or Anypoint Platform for Pivotal Cloud Foundry?
A.
When it Is required to make ALL applications highly available across multiple data centers
B.
When it is required that ALL APIs are private and NOT exposed to the public cloud
C.
When regulatory requirements mandate on-premises processing of EVERY data item, including meta-data
D.
When ALL backend systems in the application network are deployed in the
organization's intranet
When regulatory requirements mandate on-premises processing of EVERY data item, including meta-data
Explanation: Explanation
Correct Answer: When regulatory requirements mandate on-premises processing of EVERY data item, including meta-data.
*****************************************
We need NOT require to use Anypoint Platform PCE or PCF for the below. So these
options are OUT.
>> We can make ALL applications highly available across multiple data centers using
CloudHub too.
>> We can use Anypoint VPN and tunneling from CloudHub to connect to ALL backend
systems in the application network that are deployed in the organization's intranet.
>> We can use Anypoint VPC and Firewall Rules to make ALL APIs private and NOT
exposed to the public cloud.
Only valid reason in the given options that requires to use Anypoint Platform PCE/ PCF is -
When regulatory requirements mandate on-premises processing of EVERY data item,
including meta-data
An API experiences a high rate of client requests (TPS) vwth small message paytoads.
How can usage limits be imposed on the API based on the type of client application?
A.
Use an SLA-based rate limiting policy and assign a client application to a matching SLA
tier based on its type
B.
Use a spike control policy that limits the number of requests for each client application
type
C.
Use a cross-origin resource sharing (CORS) policy to limit resource sharing between
client applications, configured by the client application type
D.
Use a rate limiting policy and a client ID enforcement policy, each configured by the
client application type
Use an SLA-based rate limiting policy and assign a client application to a matching SLA
tier based on its type
Explanation: Correct Answer: Use an SLA-based rate limiting policy and assign a client
application to a matching SLA tier based on its type.
*****************************************
>> SLA tiers will come into play whenever any limits to be imposed on APIs based on client
type
Reference: https://docs.mulesoft.com/api-manager/2.x/rate-limiting-and-throttling-slabased-
policies
The application network is recomposable: it is built for change because it "bends but does
not break"
A.
TRUE
B.
FALSE
TRUE
Explanation: *****************************************
>> Application Network is a disposable architecture.
>> Which means, it can be altered without disturbing entire architecture and its
components.
>> It bends as per requirements or design changes but does not break
Reference: https://www.mulesoft.com/resources/api/what-is-an-application-network
An API has been updated in Anypoint Exchange by its API producer from version 3.1.1 to
3.2.0 following accepted semantic versioning practices and the changes have been
communicated via the API's public portal.
The API endpoint does NOT change in the new version.
How should the developer of an API client respond to this change?
A.
The update should be identified as a project risk and full regression testing of the functionality that uses this API should be run
B.
The API producer should be contacted to understand the change to existing functionality
C.
The API producer should be requested to run the old version in parallel with the new one
D.
The API client code ONLY needs to be changed if it needs to take advantage of new
features
The API client code ONLY needs to be changed if it needs to take advantage of new
features
Reference: https://docs.mulesoft.com/exchange/to-change-raml-version
What is true about the technology architecture of Anypoint VPCs?
A.
The private IP address range of an Anypoint VPC is automatically chosen by CloudHub
B.
Traffic between Mule applications deployed to an Anypoint VPC and on-premises
systems can stay within a private network
C.
Each CloudHub environment requires a separate Anypoint VPC
D.
VPC peering can be used to link the underlying AWS VPC to an on-premises (non
AWS) private network
Traffic between Mule applications deployed to an Anypoint VPC and on-premises
systems can stay within a private network
Explanation: Explanation
Correct Answer: Traffic between Mule applications deployed to an Anypoint VPC and onpremises
systems can stay within a private network
*****************************************
>> The private IP address range of an Anypoint VPC is NOT automatically chosen by
CloudHub. It is chosen by us at the time of creating VPC using thr CIDR blocks.
CIDR Block: The size of the Anypoint VPC in Classless Inter-Domain Routing (CIDR)
notation.
For example, if you set it to 10.111.0.0/24, the Anypoint VPC is granted 256 IP addresses
from 10.111.0.0 to 10.111.0.255.
Ideally, the CIDR Blocks you choose for the Anypoint VPC come from a private IP space,
and should not overlap with any other Anypoint VPC’s CIDR Blocks, or any CIDR Blocks in
use in your corporate network.
| Page 4 out of 13 Pages |
| 2345 |
| MCPA-Level-1 Practice Test Home |
Real-World Scenario Mastery: Our MCPA-Level-1 practice exam don't just test definitions. They present you with the same complex, scenario-based problems you'll encounter on the actual exam.
Strategic Weakness Identification: Each practice session reveals exactly where you stand. Discover which domains need more attention, before MuleSoft Certified Platform Architect - Level 1 exam day arrives.
Confidence Through Familiarity: There's no substitute for knowing what to expect. When you've worked through our comprehensive MCPA-Level-1 practice exam questions pool covering all topics, the real exam feels like just another practice session.
Copyright © All Rights Reserved