An organization is deploying their new implementation of the OrderStatus System API to
multiple workers in CloudHub. This API fronts the organization's on-premises Order
Management System, which is accessed by the API implementation over an IPsec tunnel.
What type of error typically does NOT result in a service outage of the OrderStatus System
API?
A.
A CloudHub worker fails with an out-of-memory exception
B.
API Manager has an extended outage during the initial deployment of the API
implementation
C.
The AWS region goes offline with a major network failure to the relevant AWS data centers
D.
The Order Management System is Inaccessible due to a network outage in the
organization's on-premises data center
A CloudHub worker fails with an out-of-memory exception
Explanation: Explanation
Correct Answer: A CloudHub worker fails with an out-of-memory exception.
*****************************************
>> An AWS Region itself going down will definitely result in an outage as it does not matter
how many workers are assigned to the Mule App as all of those in that region will go down.
This is a complete downtime and outage.
>> Extended outage of API manager during initial deployment of API implementation will of
course cause issues in proper application startup itself as the API Autodiscovery might fail
or API policy templates and polices may not be downloaded to embed at the time of
applicaiton startup etc... there are many reasons that could cause issues.
>> A network outage onpremises would of course cause the Order Management System
not accessible and it does not matter how many workers are assigned to the app they all
will fail and cause outage for sure.
The only option that does NOT result in a service outage is if a cloudhub worker fails with
an out-of-memory exception. Even if a worker fails and goes down, there are still other
workers to handle the requests and keep the API UP and Running. So, this is the right
answer.
Due to a limitation in the backend system, a system API can only handle up to 500
requests per second. What is the best type of API policy to apply to the system API to avoid overloading the backend system?
A.
Rate limiting
B.
HTTP caching
C.
Rate limiting - SLA based
D.
Spike control
Spike control
Explanation: Explanation
Correct Answer: Spike control
*****************************************
>> First things first, HTTP Caching policy is for purposes different than avoiding the
backend system from overloading. So this is OUT.
>> Rate Limiting and Throttling/ Spike Control policies are designed to limit API access, but
have different intentions.
>> Rate limiting protects an API by applying a hard limit on its access.
>> Throttling/ Spike Control shapes API access by smoothing spikes in traffic.
That is why, Spike Control is the right option
A company requires Mule applications deployed to CloudHub to be isolated between nonproduction
and production environments. This is so Mule applications deployed to nonproduction
environments can only access backend systems running in their customerhosted
non-production environment, and so Mule applications deployed to production
environments can only access backend systems running in their customer-hosted
production environment. How does MuleSoft recommend modifying Mule applications,
configuring environments, or changing infrastructure to support this type of perenvironment
isolation between Mule applications and backend systems?
A.
Modify properties of Mule applications deployed to the production Anypoint Platform
environments to prevent access from non-production Mule applications
B.
Configure firewall rules in the infrastructure inside each customer-hosted environment so
that only IP addresses from the corresponding Anypoint Platform environments are allowed
to communicate with corresponding backend systems
C.
Create non-production and production environments in different Anypoint Platform
business groups
D.
Create separate Anypoint VPCs for non-production and production environments, then configure connections to the backend systems in the corresponding customer-hosted
environments
Create separate Anypoint VPCs for non-production and production environments, then configure connections to the backend systems in the corresponding customer-hosted
environments
Explanation: Explanation
Correct Answer: Create separate Anypoint VPCs for non-production and production
environments, then configure connections to the backend systems in the corresponding
customer-hosted environments.
*****************************************
>> Creating different Business Groups does NOT make any difference w.r.t accessing the
non-prod and prod customer-hosted environments. Still they will be accessing from both
Business Groups unless process network restrictions are put in place.
>> We need to modify or couple the Mule Application Implementations with the
environment. In fact, we should never implements application coupled with environments
by binding them in the properties. Only basic things like endpoint URL etc should be
bundled in properties but not environment level access restrictions.
>> IP addresses on CloudHub are dynamic until unless a special static addresses are
assigned. So it is not possible to setup firewall rules in customer-hosted infrastrcture. More
over, even if static IP addresses are assigned, there could be 100s of applications running
on cloudhub and setting up rules for all of them would be a hectic task, non-maintainable
and definitely got a good practice.
>> The best practice recommended by Mulesoft (In fact any cloud provider), is to have
your Anypoint VPCs seperated for Prod and Non-Prod and perform the VPC peering or
VPN tunneling for these Anypoint VPCs to respective Prod and Non-Prod customer-hosted
environment networks.
: https://docs.mulesoft.com/runtime-manager/virtual-private-cloud
Bottom of Form
Top of Form
What correctly characterizes unit tests of Mule applications?
A.
They test the validity of input and output of source and target systems
B.
They must be run in a unit testing environment with dedicated Mule runtimes for the environment
C.
They must be triggered by an external client tool or event source
D.
They are typically written using MUnit to run in an embedded Mule runtime that does not require external connectivity
They are typically written using MUnit to run in an embedded Mule runtime that does not require external connectivity
Explanation: Explanation
Correct Answer: They are typically written using MUnit to run in an embedded Mule runtime
that does not require external connectivity.
*****************************************
Below TWO are characteristics of Integration Tests but NOT unit tests:
>> They test the validity of input and output of source and target systems.
>> They must be triggered by an external client tool or event source.
It is NOT TRUE that Unit Tests must be run in a unit testing environment with dedicated
Mule runtimes for the environment.
MuleSoft offers MUnit for writing Unit Tests and they run in an embedded Mule Runtime
without needing any separate/ dedicated Runtimes to execute them. They also do NOT
need any external connectivity as MUnit supports mocking via stubs.
https://dzone.com/articles/munit-framework
A company uses a hybrid Anypoint Platform deployment model that combines the EU
control plane with customer-hosted Mule runtimes. After successfully testing a Mule API
implementation in the Staging environment, the Mule API implementation is set with
environment-specific properties and must be promoted to the Production environment.
What is a way that MuleSoft recommends to configure the Mule API implementation and
automate its promotion to the Production environment?
A.
Bundle properties files for each environment into the Mule API implementation's deployable
archive, then promote the Mule API implementation to the Production environment using
Anypoint CLI or the Anypoint Platform REST APIsB.
B.
Modify the Mule API implementation's properties in the API Manager Properties tab, then
promote the Mule API implementation to the Production environment using API Manager
C.
Modify the Mule API implementation's properties in Anypoint Exchange, then promote the
Mule API implementation to the Production environment using Runtime Manager
D.
Use an API policy to change properties in the Mule API implementation deployed to the
Staging environment and another API policy to deploy the Mule API implementation to the
Production environment
Bundle properties files for each environment into the Mule API implementation's deployable
archive, then promote the Mule API implementation to the Production environment using
Anypoint CLI or the Anypoint Platform REST APIsB.
Explanation: Explanation
Correct Answer: Bundle properties files for each environment into the Mule API
implementation's deployable archive, then promote the Mule API implementation to the
Production environment using Anypoint CLI or the Anypoint Platform REST APIs
*****************************************
>> Anypoint Exchange is for asset discovery and documentation. It has got no provision to
modify the properties of Mule API implementations at all.
>> API Manager is for managing API instances, their contracts, policies and SLAs. It has
also got no provision to modify the properties of API implementations.
>> API policies are to address Non-functional requirements of APIs and has again got no
provision to modify the properties of API implementations.
So, the right way and recommended way to do this as part of development practice is to
bundle properties files for each environment into the Mule API implementation and just
point and refer to respective file per environment.
The responses to some HTTP requests can be cached depending on the HTTP verb used
in the request. According to the HTTP specification, for what HTTP verbs is this safe to do?
A.
PUT, POST, DELETE
B.
GET, HEAD, POST
C.
GET, PUT, OPTIONS
D.
GET, OPTIONS, HEAD
GET, OPTIONS, HEAD
An API implementation is deployed to CloudHub.
What conditions can be alerted on using the default Anypoint Platform functionality, where
the alert conditions depend on the end-to-end request processing of the API
implementation?
A.
When the API is invoked by an unrecognized API client
B.
When a particular API client invokes the API too often within a given time period
C.
When the response time of API invocations exceeds a threshold
D.
When the API receives a very high number of API invocations
When the response time of API invocations exceeds a threshold
Explanation: Explanation
Correct Answer: When the response time of API invocations exceeds a threshold
*****************************************
>> Alerts can be setup for all the given options using the default Anypoint Platform
functionality
>> However, the question insists on an alert whose conditions depend on the end-to-end
request processing of the API implementation.
>> Alert w.r.t "Response Times" is the only one which requires end-to-end request
processing of API implementation in order to determine if the threshold is exceeded or not.
Reference: https://docs.mulesoft.com/api-manager/2.x/using-api-alerts
A REST API is being designed to implement a Mule application.
What standard interface definition language can be used to define REST APIs?
A.
Web Service Definition Language(WSDL)
B.
OpenAPI Specification (OAS)
C.
YAML
D.
AsyncAPI Specification
OpenAPI Specification (OAS)
A system API is deployed to a primary environment as well as to a disaster recovery (DR)
environment, with different DNS names in each environment. A process API is a client to
the system API and is being rate limited by the system API, with different limits in each of
the environments. The system API's DR environment provides only 20% of the rate limiting
offered by the primary environment. What is the best API fault-tolerant invocation strategy
to reduce overall errors in the process API, given these conditions and constraints?
A.
Invoke the system API deployed to the primary environment; add timeout and retry logic to
the process API to avoid intermittent failures; if it still fails, invoke the system API deployed
to the DR environment
B.
Invoke the system API deployed to the primary environment; add retry logic to the process
API to handle intermittent failures by invoking the system API deployed to the DR
environment
C.
In parallel, invoke the system API deployed to the primary environment and the system API
deployed to the DR environment; add timeout and retry logic to the process API to avoid
intermittent failures; add logic to the process API to combine the results
D.
Invoke the system API deployed to the primary environment; add timeout and retry logic to
the process API to avoid intermittent failures; if it still fails, invoke a copy of the process API
deployed to the DR environment
Invoke the system API deployed to the primary environment; add timeout and retry logic to
the process API to avoid intermittent failures; if it still fails, invoke the system API deployed
to the DR environment
Explanation: Explanation
Correct Answer: Invoke the system API deployed to the primary environment; add timeout
and retry logic to the process API to avoid intermittent failures; if it still fails, invoke the
system API deployed to the DR environment
*****************************************
There is one important consideration to be noted in the question which is - System API in
DR environment provides only 20% of the rate limiting offered by the primary environment.
So, comparitively, very less calls will be allowed into the DR environment API opposed to
its primary environment. With this in mind, lets analyse what is the right and best faulttolerant
invocation strategy.
1. Invoking both the system APIs in parallel is definitely NOT a feasible approach because
of the 20% limitation we have on DR environment. Calling in parallel every time would
easily and quickly exhaust the rate limits on DR environment and may not give chance to
genuine intermittent error scenarios to let in during the time of need.
2. Another option given is suggesting to add timeout and retry logic to process API while
invoking primary environment's system API. This is good so far. However, when all retries
failed, the option is suggesting to invoke the copy of process API on DR environment which
is not right or recommended. Only system API is the one to be considered for fallback and
not the whole process API. Process APIs usually have lot of heavy orchestration calling
many other APIs which we do not want to repeat again by calling DR's process API. So this
option is NOT right.
3. One more option given is suggesting to add the retry (no timeout) logic to process API to
directly retry on DR environment's system API instead of retrying the primary environment
system API first. This is not at all a proper fallback. A proper fallback should occur only
after all retries are performed and exhausted on Primary environment first. But here, the
option is suggesting to directly retry fallback API on first failure itself without trying main
API. So, this option is NOT right too.
This leaves us one option which is right and best fit.
- Invoke the system API deployed to the primary environment
- Add Timeout and Retry logic on it in process API
- If it fails even after all retries, then invoke the system API deployed to the DR
environment.
Select the correct Owner-Layer combinations from below options
A.
1. App Developers owns and focuses on Experience Layer APIs
2. Central IT owns and focuses on Process Layer APIs
3. LOB IT owns and focuses on System Layer APIs
B.
1. Central IT owns and focuses on Experience Layer APIs
2. LOB IT owns and focuses on Process Layer APIs
3. App Developers owns and focuses on System Layer APIs
C.
1. App Developers owns and focuses on Experience Layer APIs
2. LOB IT owns and focuses on Process Layer APIs
3. Central IT owns and focuses on System Layer APIs
1. App Developers owns and focuses on Experience Layer APIs
2. LOB IT owns and focuses on Process Layer APIs
3. Central IT owns and focuses on System Layer APIs
Explanation: Explanation
Correct Answer:
1. App Developers owns and focuses on Experience Layer APIs
2. LOB IT owns and focuses on Process Layer APIs
3. Central IT owns and focuses on System Layer APIs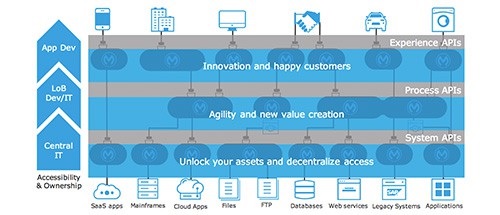
References:
https://blogs.mulesoft.com/biz/api/experience-api-ownership/
https://blogs.mulesoft.com/biz/api/process-api-ownership/
https://blogs.mulesoft.com/biz/api/system-api-ownership
What best describes the Fully Qualified Domain Names (FQDNs), also known as DNS entries, created when a Mule application is deployed to the CloudHub Shared Worker Cloud?
A.
A fixed number of FQDNs are created, IRRESPECTIVE of the environment and VPC design
B.
The FQDNs are determined by the application name chosen, IRRESPECTIVE of the region
C.
The FQDNs are determined by the application name, but can be modified by an
administrator after deployment
D.
The FQDNs are determined by both the application name and the Anypoint Platform
organization
The FQDNs are determined by the application name chosen, IRRESPECTIVE of the region
Explanation: Explanation
Correct Answer: The FQDNs are determined by the application name chosen,
IRRESPECTIVE of the region
*****************************************
>> When deploying applications to Shared Worker Cloud, the FQDN are always
determined by application name chosen.
>> It does NOT matter what region the app is being deployed to.
>> Although it is fact and true that the generated FQDN will have the region included in it
(Ex: exp-salesorder-api.au-s1.cloudhub.io), it does NOT mean that the same name can be
used when deploying to another CloudHub region.
>> Application name should be universally unique irrespective of Region and Organization
and solely determines the FQDN for Shared Load Balancers
Mule applications that implement a number of REST APIs are deployed to their own subnet
that is inaccessible from outside the organization.
External business-partners need to access these APIs, which are only allowed to be
invoked from a separate subnet dedicated to partners - called Partner-subnet. This subnet
is accessible from the public internet, which allows these external partners to reach it.
Anypoint Platform and Mule runtimes are already deployed in Partner-subnet. These Mule
runtimes can already access the APIs.
What is the most resource-efficient solution to comply with these requirements, while
having the least impact on other applications that are currently using the APIs?
A.
Implement (or generate) an API proxy Mule application for each of the APIs, then deploy the API proxies to the Mule runtimes
B.
Redeploy the API implementations to the same servers running the Mule runtimes
C.
Add an additional endpoint to each API for partner-enablement consumption
D.
Duplicate the APIs as Mule applications, then deploy them to the Mule runtimes
Implement (or generate) an API proxy Mule application for each of the APIs, then deploy the API proxies to the Mule runtimes
| Page 3 out of 13 Pages |
| 1234 |
| MCPA-Level-1 Practice Test Home |
Real-World Scenario Mastery: Our MCPA-Level-1 practice exam don't just test definitions. They present you with the same complex, scenario-based problems you'll encounter on the actual exam.
Strategic Weakness Identification: Each practice session reveals exactly where you stand. Discover which domains need more attention, before MuleSoft Certified Platform Architect - Level 1 exam day arrives.
Confidence Through Familiarity: There's no substitute for knowing what to expect. When you've worked through our comprehensive MCPA-Level-1 practice exam questions pool covering all topics, the real exam feels like just another practice session.
Copyright © All Rights Reserved