Topic 1: Contoso, Ltd
You need to create the product dimension.
How should you complete the Apache Spark SQL code? To answer, select the appropriate
options in the answer area.
NOTE: Each correct selection is worth one point.
Summary:
This question involves building a product dimension table by joining multiple source tables. The goal is to select the correct JOIN types and WHERE clause filters to create a clean, complete list of products, likely for a data warehouse. The logic must ensure we get all relevant products while handling potential missing relationships correctly.
Correct Option Explanations
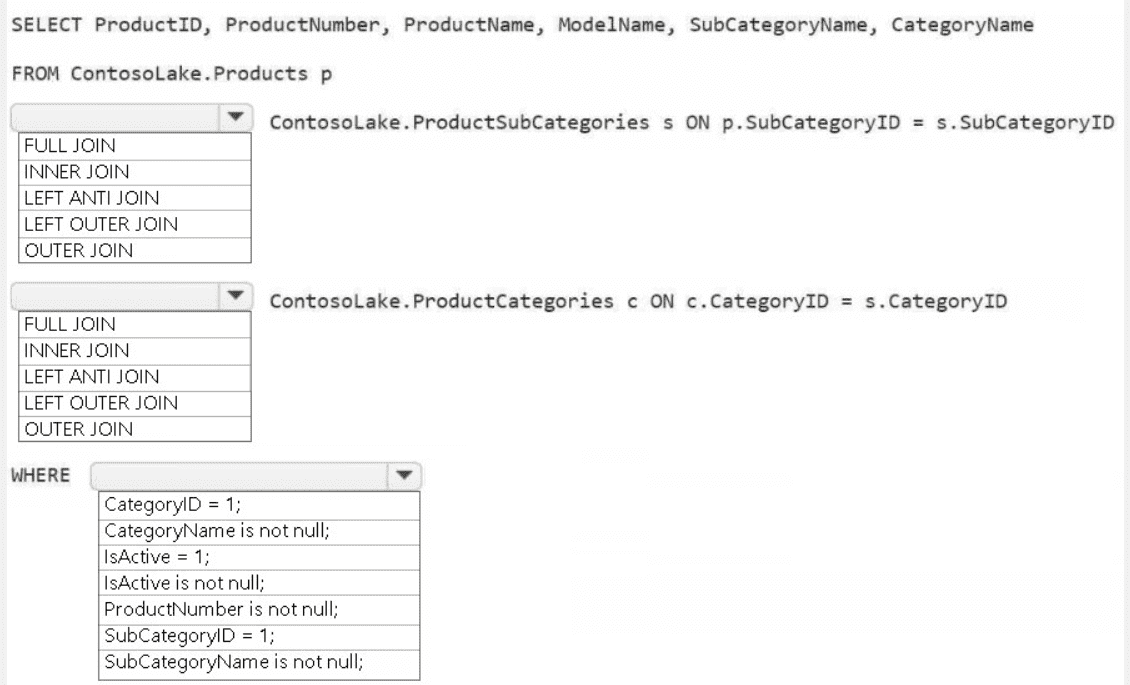
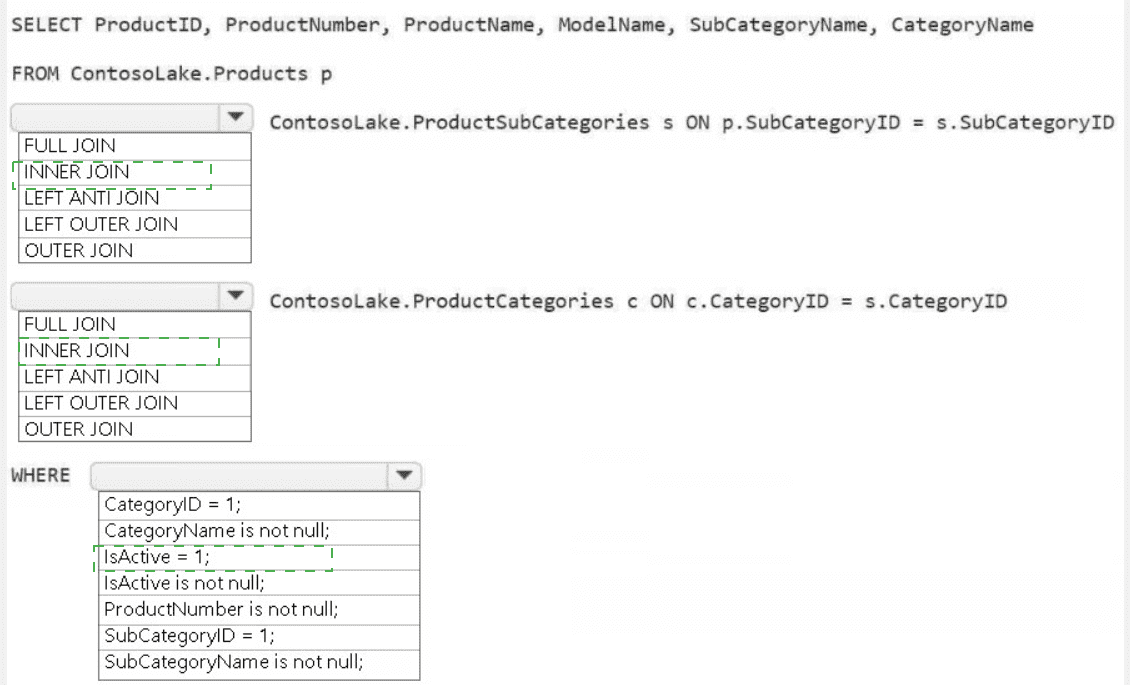
1. First JOIN Type: LEFT OUTER JOIN
The product dimension must be based on all available products from the Products table (p). Using a LEFT OUTER JOIN to the ProductSubCategories table (s) ensures that every product is included in the result, even if it has a missing or invalid SubCategoryID. An INNER JOIN would incorrectly exclude any products without a valid subcategory.
2. Second JOIN Type: LEFT OUTER JOIN
The same logic applies for joining to the ProductCategories table (c). The join is performed from the already-outer-joined subcategory table. Using another LEFT OUTER JOIN guarantees that the final result includes all products from the first join, even if their corresponding subcategory has a missing or invalid link to a category.
3. WHERE Clause: IsActive = 1 AND ProductNumber is not null
IsActive = 1: A common business rule for a dimension is to only include currently active records. This filter selects only active products.
ProductNumber is not null: This is a data quality filter. A product key like ProductNumber should never be null in a well-formed dimension table. This ensures referential integrity and clean data.
The other options are incorrect:
Filtering on specific CategoryID or SubCategoryID values (e.g., = 1) is too restrictive.
Filtering on CategoryName is not null or SubCategoryName is not null would defeat the purpose of the outer joins, as it would remove the products with missing categories that we deliberately included.
Reference:
Microsoft Official Documentation: JOIN (Databricks SQL) - This explains the different join types available in Spark SQL, which is the engine used by Fabric.
You need to populate the MAR1 data in the bronze layer.
Which two types of activities should you include in the pipeline? Each correct answer
presents part of the solution.
NOTE: Each correct selection is worth one point.
A. ForEach
B. Copy data
C. WebHook
D. Stored procedure
Summary:
This question involves designing a data pipeline to ingest data into the "bronze layer" of a Medallion Architecture in Microsoft Fabric. The bronze layer is the raw data landing zone. The source is specified as "MAR1," which is a common abbreviation for the Microsoft Azure Resources REST API. To populate this data, the pipeline must first call an API to get a list of resources and then copy the detailed data for each resource.
Correct Options:
A. ForEach
A ForEach activity is a looping container in a pipeline. When ingesting from an API like MAR1, a common pattern is to first get a list of all resources (e.g., a list of subscription IDs or resource IDs) and then use a ForEach loop to iterate over that list. Inside the loop, another activity (like the Copy Data activity) would be executed for each item to retrieve the specific details for that resource. This allows for efficient and organized processing of multiple entities.
B. Copy data
The Copy Data activity is the primary workhorse for moving data in Azure Data Factory and Fabric pipelines. It can connect to a vast array of sources and sinks. In this scenario, it would be used to connect to the MAR1 API (likely using a REST or HTTP connector as the source) and copy the raw, unaltered JSON response directly into the bronze layer of the lakehouse (the sink). This activity is essential for performing the actual data movement.
Incorrect Options:
C. WebHook
A WebHook activity is used to call an endpoint and pass a callback URL, which that endpoint will later use to notify the pipeline of an event (like a long-running job completing). It is designed for asynchronous, event-driven workflows. For a straightforward data ingestion task from an API, the synchronous Copy Data activity is the direct and correct choice, not a WebHook.
D. Stored procedure
A Stored procedure activity is used to execute a stored procedure in a relational database like Azure SQL Database or Synapse Analytics. Since the source is the MAR1 API (a REST endpoint) and not a relational database, this activity is not applicable for the data retrieval part of this task. It might be used later in the data processing lifecycle but not for the initial bronze layer ingestion from an API.
Reference:
Microsoft Official Documentation: Copy data using the Copy Data activity
Microsoft Official Documentation: ForEach activity in Azure Data Factory
You need to ensure that the data analysts can access the gold layer lakehouse.
What should you do?
A. Add the DataAnalyst group to the Viewer role for WorkspaceA.
B. Share the lakehouse with the DataAnalysts group and grant the Build reports on the default semantic model permission.
C. Share the lakehouse with the DataAnalysts group and grant the Read all SQL Endpoint data permission.
D. Share the lakehouse with the DataAnalysts group and grant the Read all Apache Spark permission.
Summary:
This question focuses on granting appropriate permissions for data access within the Fabric platform. The goal is to allow data analysts to access the "gold layer" lakehouse, which contains refined, business-ready data. Analysts typically need to query this data using SQL to build reports or perform analysis. The solution must provide the necessary permissions for this read-only SQL query access without granting unnecessary administrative or write capabilities.
Correct Option:
C. Share the lakehouse with the DataAnalysts group and grant the Read all SQL Endpoint data permission.
Every Fabric lakehouse automatically comes with a SQL analytics endpoint. This endpoint provides a T-SQL interface for querying the data. Granting the "Read all SQL Endpoint data" permission through the Share function is the precise and recommended way to enable data analysts to run SQL queries against the gold layer data. It provides direct, read-only access, which is the standard requirement for this user persona.
Incorrect Options:
A. Add the DataAnalyst group to the Viewer role for WorkspaceA.
While a Viewer role grants read access to the entire workspace, it is a broader and less secure permission than necessary. It allows viewing all items, their properties, and their SQL endpoints. However, using the granular Share feature for the specific lakehouse is a more modern and precise security practice. It follows the principle of least privilege by giving access only to the needed resource (the lakehouse), not the entire workspace.
B. Share the lakehouse with the DataAnalysts group and grant the Build reports on the default semantic model permission.
This permission is for connecting Power BI Desktop to the default semantic model of the lakehouse to build reports. While analysts might do this eventually, it does not grant them the ability to directly query the data via SQL for their own analysis, profiling, or ad-hoc exploration in tools like SQL Server Management Studio (SSMS) or Azure Data Studio. The question's primary intent is for direct data access, not just report building.
D. Share the lakehouse with the DataAnalysts group and grant the Read all Apache Spark permission.
This permission allows users to read data from the lakehouse using Spark notebooks and Spark SQL. This is more suited to data engineers and data scientists who work in a Spark/PySpark environment. Data analysts are far more likely to use the familiar T-SQL language via the SQL endpoint, making this the less optimal and less user-friendly choice for the stated goal.
Reference:
Microsoft Official Documentation: Share a lakehouse or warehouse in Microsoft Fabric
You need to ensure that usage of the data in the Amazon S3 bucket meets the technical
requirements.
What should you do?
A. Create a workspace identity and enable high concurrency for the notebooks.
B. Create a shortcut and ensure that caching is disabled for the workspace.
C. Create a workspace identity and use the identity in a data pipeline.
D. Create a shortcut and ensure that caching is enabled for the workspace.
Summary:
This question centers around securely and efficiently accessing data in an external Amazon S3 bucket from Microsoft Fabric. The technical requirements, while not fully listed, imply a need for a managed, secure, and scalable connection. The solution must provide a secure authentication method between the Fabric service and S3, avoiding individual user credentials. Using a managed identity is the standard pattern for this scenario.
Correct Option:
C. Create a workspace identity and use the identity in a data pipeline.
A workspace identity is a managed identity automatically created for your Fabric workspace. You can configure your Amazon S3 bucket to trust this specific identity by adding its Object ID to your S3 bucket policy. A data pipeline can then use this identity to authenticate and access the S3 data securely without storing any credentials in code. This provides a robust, secure, and automatable solution for data ingestion that meets enterprise technical requirements.
Incorrect Options:
A. Create a workspace identity and enable high concurrency for the notebooks.
While creating a workspace identity is a correct step for security, enabling high concurrency for notebooks is unrelated to the core requirement of accessing S3 data. High concurrency is a Spark cluster configuration that optimizes resource sharing for multiple concurrent notebook sessions but does not itself establish a connection or meet security requirements for an external data source.
B. Create a shortcut and ensure that caching is disabled for the workspace.
A shortcut is the correct way to create a virtual pointer to data in S3. However, disabling caching would harm performance, as data would need to be fetched from S3 every time it's queried. More critically, a shortcut alone does not solve the authentication requirement; you still need to configure access, for which the workspace identity is the recommended method. This option is incomplete.
D. Create a shortcut and ensure that caching is enabled for the workspace.
Similar to option B, this suggests creating a shortcut. While enabling caching improves performance, this option also fails to address the primary requirement of how to securely authenticate and authorize the connection to the S3 bucket. The shortcut creation process itself requires configured authentication, which is best handled by the workspace identity.
Reference:
Microsoft Official Documentation: Configure cross-cloud access with shortcuts - This documentation details the process of using a workspace identity to grant Fabric access to an Amazon S3 bucket.
You need to recommend a method to populate the POS1 data to the lakehouse medallion
layers.
What should you recommend for each layer? To answer, select the appropriate options in
the answer area.
NOTE: Each correct selection is worth one point.

Summary:
This question asks for the appropriate tool to implement the Medallion Architecture in Fabric. The bronze layer is for raw, unprocessed data ingestion, while the silver layer is for cleaned, filtered, and validated data. The tools must align with these purposes: a simple, orchestrated copy for bronze, and a transformation engine for silver.
Correct Option Explanations
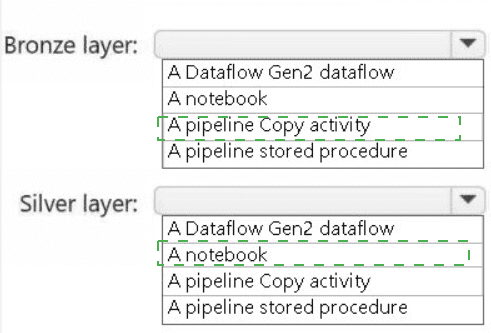
Bronze Layer: A pipeline Copy activity
The primary goal of the bronze layer is to ingest raw data from source systems in its original format as quickly and reliably as possible. A pipeline Copy activity is the ideal tool for this. It is designed for efficient data movement from a vast array of sources (like a POS system) into a destination (the lakehouse) with minimal transformation. It provides orchestration, scheduling, and monitoring, making it perfect for the "landing" stage of the medallion architecture.
Silver Layer: A notebook
The silver layer involves data cleansing, validation, filtering, deduplication, and other transformations to create a reliable, queryable dataset. An Apache Spark notebook is the most powerful and flexible tool for this task. It allows data engineers to write complex transformation logic using PySpark, Spark SQL, or Scala, leveraging the full distributed processing power of Spark. This is essential for processing the raw data from the bronze layer into a refined silver layer.
Incorrect Option Explanations
Bronze Layer - Incorrect Options:
A Dataflow Gen2 dataflow:
While it can copy data, it is overkill for simple raw ingestion. It's a transformation tool, and its primary strength is in Power Query-based data shaping, not simple, high-volume raw data landing.
A notebook:
A notebook is too heavy and complex for a simple data copy operation. It is better suited for the transformation logic required in the silver layer.
A pipeline stored procedure:
This is used to execute SQL commands in a relational database, not to ingest data from an external source like a POS system into a lakehouse.
Silver Layer - Incorrect Options:
A Dataflow Gen2 dataflow:
This is a valid alternative for the silver layer, especially for users more familiar with Power Query. However, for complex, code-first transformations and large-scale data processing, a Spark notebook is generally more powerful and is the typical tool for data engineers building a medallion architecture.
A pipeline Copy activity:
This tool is for moving data, not for applying complex transformations. It lacks the logic needed to clean and validate data for the silver layer.
A pipeline stored procedure:
This is for executing procedures in a database, not for transforming data within a lakehouse.
Reference:
Microsoft Official Documentation: Medallion architecture
You need to ensure that the authors can see only their respective sales data.
How should you complete the statement? To answer, drag the appropriate values the
correct targets. Each value may be used once, more than once, or not at all. You may need
to drag the split bar between panes or scroll to view content
NOTE: Each correct selection is worth one point.
Summary:
This question involves implementing Row-Level Security (RLS) in a Fabric Warehouse or SQL database to restrict data access. The goal is to ensure authors can only see their own sales records. The solution requires creating a security policy that uses an inline table-valued function as a filter predicate. This function compares a column in the table (the author's email) to the current user's context.
Correct Option Explanations
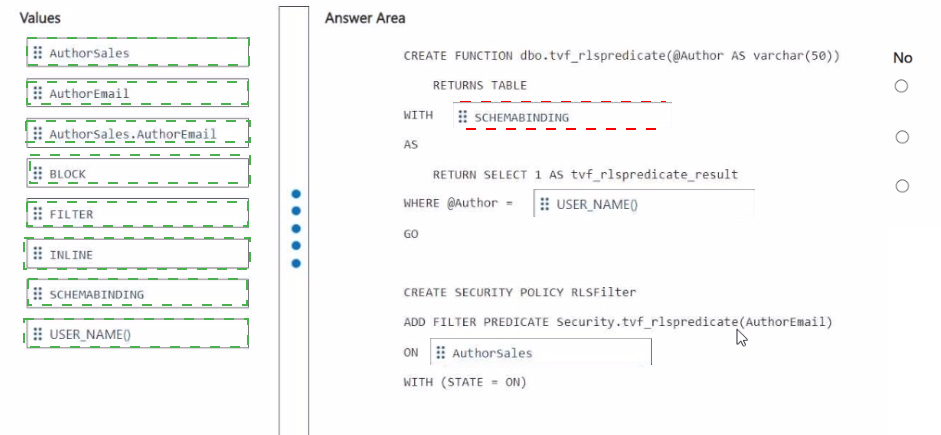
1. SCHEMABINDING
This clause is required in the function creation. It binds the function to the schema of the objects it references, which in this case is the Authorsales table. This prevents the underlying table schema from being altered in a way that would break the security policy, ensuring the integrity of the RLS implementation.
2. USER_NAME()
This is a system function that returns the name of the current database user. In the context of the RLS function, USER_NAME() will return the identity of the author who is executing a query. The WHERE clause @Author = USER_NAME() is the core logic that filters the rows, ensuring that only rows where the AuthorEmail column matches the current user's name are returned.
3. FILTER
In the CREATE SECURITY POLICY statement, you must specify the type of predicate. A FILTER predicate silently filters the rows that can be selected, updated, or deleted from the base table. This is the correct type for this requirement, as it prevents authors from seeing other authors' sales data during SELECT operations.
4. dbo.Authorsales
This is the fully qualified name (schema and table) of the table on which the security policy is being applied. The security policy and its filter predicate must be applied to the correct table containing the sensitive data (Authorsales) and the column used for filtering (AuthorEmail).
Incorrect Option Explanations
BLOCK:
A BLOCK predicate is used to prevent write operations (INSERT, UPDATE, DELETE) that would violate a rule. The requirement is about filtering data that can be seen, which is the purpose of a FILTER predicate, not a BLOCK predicate.
INLINE:
This is not a valid keyword for RLS predicates in T-SQL. Inline table-valued functions are defined differently, and the INLINE clause is not used in this context for creating the security policy.
Authorsales.AuthorEmail:
While this specifies the column, the ADD FILTER PREDICATE syntax requires the function name followed by the column name in parentheses, not the fully qualified table.column name. The correct syntax is dbo.tvf_rlspredicate(AuthorEmail).
Reference:
Microsoft Official Documentation: Row-Level Security
You need to resolve the sales data issue. The solution must minimize the amount of data transferred.
What should you do?
A. Spilt the dataflow into two dataflows.
B. Configure scheduled refresh for the dataflow.
C. Configure incremental refresh for the dataflow. Set Store rows from the past to 1 Month.
D. Configure incremental refresh for the dataflow. Set Refresh rows from the past to 1 Year.
E. Configure incremental refresh for the dataflow. Set Refresh rows from the past to 1 Month.
Summary:
This question addresses a performance issue in a dataflow, specifically related to the volume of data being processed. The core requirement is to minimize the amount of data transferred and processed during each refresh. The most effective way to achieve this is by implementing incremental refresh, which only loads new or changed data instead of the entire dataset every time.
Correct Option:
E. Configure incremental refresh for the dataflow. Set Refresh rows from the past to 1 Month.
Incremental refresh is the feature designed specifically to solve this problem. It significantly reduces data transfer and processing time by first performing a full initial load, and then subsequently loading only data that has changed within a defined period.
The key configuration is "Refresh rows from the past," which determines the range of historical data queried during a refresh. Setting this to 1 Month means the dataflow will only fetch and process data from the last 30 days. This is the most balanced approach, ensuring recent data is updated while minimizing the data volume, as it processes less data than a 1-year window (Option D).
Incorrect Options:
A. Split the dataflow into two dataflows.
While splitting a dataflow can help with organization or manageability, it does not inherently reduce the amount of data being transferred from the source system. Both dataflows would still need to query the source, potentially transferring the same or even a larger total volume of data.
B. Configure scheduled refresh for the dataflow.
Scheduled refresh determines when the dataflow runs (e.g., daily, hourly), but it does not change how much data is processed during each run. A scheduled refresh would still pull the entire dataset unless combined with incremental refresh.
C. Configure incremental refresh for the dataflow. Set Store rows from the past to 1 Month.
istorical data is kept in the destination (e.g., the lakehouse). It does not control the amount of data queried from the source. To minimize data transfer, you must reduce the source query range using "Refresh rows from the past".
D. Configure incremental refresh for the dataflow. Set Refresh rows from the past to 1 Year.
This is on the right track by using incremental refresh. However, setting the refresh period to 1 Year will still transfer a significantly larger amount of data in each refresh cycle compared to a 1-month window. To "minimize the amount of data transferred," the 1-month period is the more optimal and conservative choice.
Reference:
Microsoft Official Documentation: Incremental refresh in Power BI and Fabric Dataflows Gen2
You need to implement the solution for the book reviews.
Which should you do?
A. Create a Dataflow Gen2 dataflow.
B. Create a shortcut.
C. Enable external data sharing.
D. Create a data pipeline.
Summary:
This question asks for the best method to make book review data accessible for analysis within a Fabric environment. The key is to provide direct, live query access to data that resides in an external storage account (like ADLS Gen2) without creating a physical copy or moving the data. This approach minimizes storage costs and data duplication while ensuring the data is always current.
Correct Option:
B. Create a shortcut.
A shortcut in Microsoft Fabric creates a virtual pointer to data in an external location, such as an Azure Data Lake Storage Gen2 account or Amazon S3. It allows you to query the external data as if it were natively stored in OneLake without actually moving or copying it. This is the ideal solution for providing access to book reviews stored externally, as it offers seamless integration, real-time data access, and efficient resource utilization.
Incorrect Options:
A. Create a Dataflow Gen2 dataflow.
A Dataflow Gen2 is a transformation tool. It is used to connect to a source, apply complex data transformation logic using Power Query, and then load the resulting data into a destination like a lakehouse or warehouse. It creates a physical copy or a transformed version of the data, which is unnecessary if the goal is simply to provide direct read access to the raw review data.
C. Enable external data sharing.
External data sharing is a feature for securely sharing data from Fabric with external consumers. The scenario describes needing to access data for analysis in Fabric, implying the data is coming from an external source into the Fabric workspace. This option addresses the reverse flow of data.
D. Create a data pipeline.
A data pipeline is an orchestration tool used to automate and schedule multi-step data movement and transformation processes (e.g., running a copy activity, executing a notebook). It is overkill for the task of simply making external data available for querying. A pipeline would be used to copy the data, which is less efficient than using a shortcut for direct query access.
Reference:
Microsoft Official Documentation: OneLake shortcuts
HOTSPOT
You need to troubleshoot the ad-hoc query issue.
How should you complete the statement? To answer, select the appropriate options in the
answer area.
NOTE: Each correct selection is worth one point.
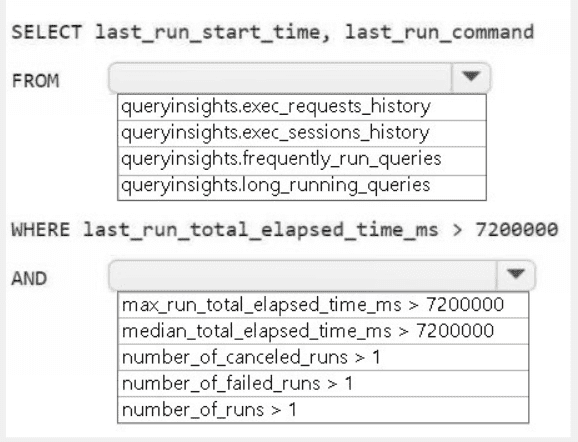
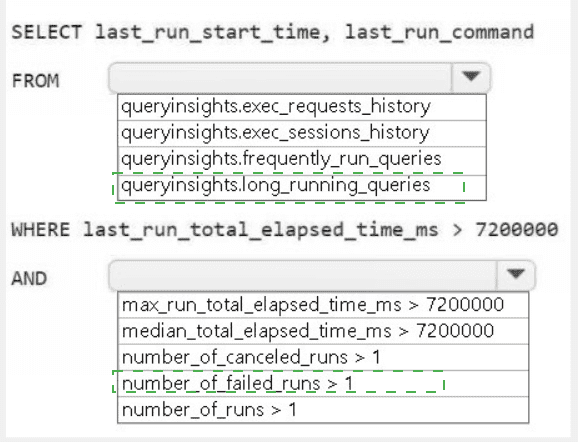
Summary:
This question involves using the Query Insights dynamic management views (DMVs) in Fabric to identify problematic queries. The goal is to find queries that have been running for a long time. The filter > 7200000 ms equates to 2 hours (7,200,000 / 1000 / 60 / 60 = 2), indicating a focus on long-running queries. The correct DMV and metric must be selected to filter for queries where the typical execution time is high, not just a single instance.
Correct Option Explanations
1. queryinsights.long_running_queries
This is the most appropriate DMV for this scenario. The long_running_queries view is specifically pre-aggregated to help identify queries that consistently have a long execution time. It provides aggregated metrics (like median, max) for queries that have run multiple times, making it perfect for troubleshooting performance issues related to query duration.
2. median_total_elapsed_time_ms
The median is the correct statistical measure to identify queries that are typically slow. Using the median (median_total_elapsed_time_ms) filters for queries where the typical execution time exceeds 2 hours, which is a strong indicator of a systemic performance issue with that specific query. This is more reliable than max, which could be skewed by a single outlier run.
Incorrect Option Explanations
FROM Clause - Incorrect Options:
queryinsights.exec_requests_history:
This DMV contains a history of individual query executions. While it could be used with complex grouping and filtering, it is a raw log. The long_running_queries DMV is a simpler, more direct solution as it provides this analysis pre-calculated.
queryinsights.exec_sessions_history:
This DMV tracks session-level information, not individual query performance. It is not the right source for analyzing specific query run times.
queryinsights.frequently_run_queries:
This DMV is optimized for identifying queries that are run very often, not necessarily those that run for a long time. While a query can be both frequent and long-running, the requirement specifically points to a "long-running" issue.
WHERE Clause - Incorrect Options:
max_run_total_elapsed_time_ms:
This would only find queries that had at least one execution that exceeded 2 hours. It doesn't indicate that the query is consistently problematic, only that it had a single bad run, which could be due to transient resource issues.
last_run_total_elapsed_time_ms:
This only looks at the most recent execution. A query might have run long once but is normally fast. The goal is to find queries that are generally slow.
number_of_canceled_runs > 1 / number_of_failed_runs > 1:
These filters are for finding queries with reliability issues (cancellations or failures), not performance issues related to long execution times.
number_of_runs > 1:
This is a reasonable filter to ensure you're looking at repeated queries, but it is not the primary filter for identifying long-running queries. The primary filter must be based on elapsed time.
Reference:
Microsoft Official Documentation: Query Insights dynamic management views (DMVs) - This documentation details the purpose and schema of DMVs like long_running_queries and the available metrics like median_total_elapsed_time_ms.
What should you do to optimize the query experience for the business users?
A. Enable V-Order.
B. Create and update statistics.
C. Run the VACUUM command.
D. Introduce primary keys.
Summary:
This question focuses on optimizing query performance for end-users (business users) in a Fabric data warehouse or lakehouse. Business users typically run a variety of ad-hoc, read-only queries. The query optimizer's ability to create efficient execution plans is the most critical factor for this unpredictable workload. To do this effectively, the optimizer requires accurate data distribution statistics.
Correct Option:
B. Create and update statistics.
Statistics provide the query optimizer with essential metadata about the distribution of data within columns (e.g., number of distinct values, data ranges). When statistics are present and up-to-date, the optimizer can make intelligent decisions about how to execute a query, such as choosing the best join algorithms or filter application order. This directly leads to faster and more consistent performance for the ad-hoc queries run by business users. It is a foundational best practice for optimizing relational query engines.
Incorrect Options:
A. Enable V-Order.
V-Order is a write-time optimization that improves compression and read performance for data in a lakehouse. It is highly beneficial but is typically applied during data ingestion by data engineers. It is not a direct, user-configurable action for optimizing an existing query experience in the same way that managing statistics is. Its benefits are more passive.
C. Run the VACUUM command.
The VACUUM command is used for storage management and cleanup. It removes data files that are no longer part of the current table version and are older than the retention threshold. While this can reclaim storage, it has a minimal impact on the performance of read queries for business users. It does not help the query optimizer generate better plans.
D. Introduce primary keys.
Primary keys in a Fabric warehouse are primarily a logical construct that enforce entity integrity by ensuring uniqueness. While they can be helpful for guiding some optimizations, they do not, by themselves, create the detailed data distribution statistics that the optimizer relies on for efficient plan generation. Creating statistics is a more direct and impactful action for general query performance.
Reference:
Microsoft Official Documentation: Statistics in Fabric Data Warehouse
You have an Azure event hub. Each event contains the following fields:
BikepointID
Street
Neighbourhood
Latitude
Longitude
No_Bikes
No_Empty_Docks
You need to ingest the events. The solution must only retain events that have a
Neighbourhood value of Chelsea, and then store the retained events in a Fabric lakehouse.
What should you use?
A. a KQL queryset
B. an eventstream
C. a streaming dataset
D. Apache Spark Structured Streaming
Summary:
This question involves real-time data ingestion from Azure Event Hubs into a Fabric lakehouse with a specific filtering requirement. The solution needs to connect to the event hub, filter events based on a condition (Neighbourhood == 'Chelsea'), and write the results to the lakehouse. This requires a service capable of handling streaming data and applying transformation logic in near real-time.
Correct Option:
B. an eventstream
An eventstream in Fabric is a dedicated service for ingesting, transforming, and routing real-time event data. It has a built-in connector for Azure Event Hubs. You can add a Filter transformation operator directly within the eventstream to retain only events where Neighbourhood equals "Chelsea". Finally, you can route the filtered output to a lakehouse destination. This provides a low-code, UI-driven solution that perfectly meets all the stated requirements.
Incorrect Options:
A. a KQL queryset
A KQL queryset is used to query data that is already stored in a KQL database within Fabric. It is not a data ingestion tool and cannot natively read directly from an Azure Event Hub to land data into a lakehouse. Its role is analysis, not ETL/ELT.
C. a streaming dataset
A streaming dataset in Fabric is primarily a destination for data that will be used in Power BI real-time dashboards. It is not designed for transforming and storing raw event data in a lakehouse for broader data engineering purposes. It lacks the transformation capabilities (like filtering) needed before storage.
D. Apache Spark Structured Streaming
While this is a technically feasible option using code in a notebook, it is not the best answer. An eventstream provides the same underlying capability but through a managed, low-code interface that is simpler to configure and manage for a straightforward filter-and-store task. The question does not specify a requirement for custom code, so the platform-native, no-code tool (eventstream) is the preferred solution.
Reference:
Microsoft Official Documentation: What is eventstream in Microsoft Fabric?
You are building a data orchestration pattern by using a Fabric data pipeline named
Dynamic Data Copy as shown in the exhibit. (Click the Exhibit tab.)
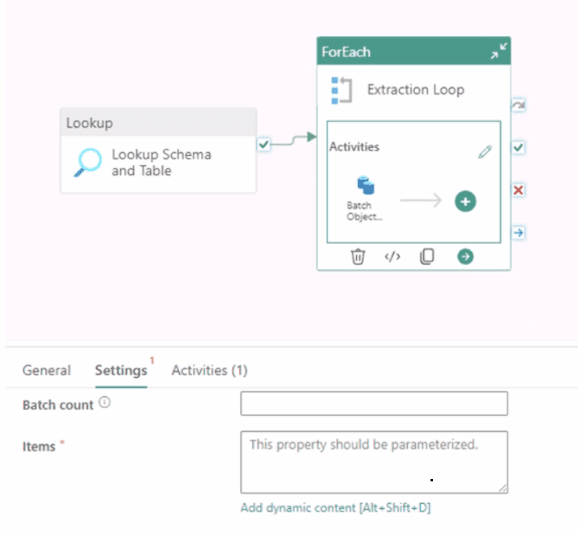
Dynamic Data Copy does NOT use parametrization.
You need to configure the ForEach activity to receive the list of tables to be copied.
How should you complete the pipeline expression? To answer, select the appropriate
options in the answer area.
NOTE: Each correct selection is worth one point.


Summary:
This question involves configuring a Fabric Data Factory pipeline. A Lookup activity is used to retrieve a list of objects (schemas and tables), and a ForEach activity is needed to loop over that list. The Lookup activity's result is stored in its output, and the ForEach activity must be configured to consume this output correctly to iterate through each item in the list.
Correct Option Explanations
@activity('Lookup Schema and Table').output.value
This is the correct expression to retrieve the list of items for the ForEach loop.
activity('Lookup Schema and Table') references the preceding Lookup activity by its name.
.output accesses the result set produced by that activity.
.value is the specific property that contains the array (list) of records returned by the Lookup. The ForEach activity requires an array to iterate over, making .value the necessary final part of the expression.
Incorrect Option Explanations
Other output properties:
output:
This refers to the entire output object of the Lookup activity, which includes metadata like execution count and status, not just the data array. The ForEach activity cannot iterate over this full object.
output.count:
This property returns a single integer representing the number of records in the result set. It is a scalar value, not an array, so it cannot be used for iterating through individual items.
output.pipelineReturnValue:
This is not a standard property of a Lookup activity's output. It might be used in other contexts, such as the return value of an Execute Pipeline activity, but not for the result set of a Lookup.
Activity Names:
Batch Object Copy, Dynamic Data Copy, Extraction Loop: These are the names of other activities or the pipeline itself. The expression must reference the specific Lookup activity that produces the list, which is named Lookup Schema and Table.
Reference:
Microsoft Official Documentation: Lookup activity in Azure Data Factory and Azure Synapse Analytics
Microsoft Official Documentation: ForEach activity in Azure Data Factory
| Page 1 out of 8 Pages |