Topic 1, Case Study 1
Overview
You are a data scientist in a company that provides data science for professional sporting events. Models will
be global and local market data to meet the following business goals:
•Understand sentiment of mobile device users at sporting events based on audio from crowd reactions.
•Access a user's tendency to respond to an advertisement.
•Customize styles of ads served on mobile devices.
•Use video to detect penalty events.
Current environment
Requirements
• Media used for penalty event detection will be provided by consumer devices. Media may include images
and videos captured during the sporting event and snared using social media. The images and videos will have
varying sizes and formats.
• The data available for model building comprises of seven years of sporting event media. The sporting event
media includes: recorded videos, transcripts of radio commentary, and logs from related social media feeds
feeds captured during the sporting events.
•Crowd sentiment will include audio recordings submitted by event attendees in both mono and stereo
Formats.
Advertisements
• Ad response models must be trained at the beginning of each event and applied during the sporting event.
• Market segmentation nxxlels must optimize for similar ad resporr.r history.
• Sampling must guarantee mutual and collective exclusivity local and global segmentation models that share
the same features.
• Local market segmentation models will be applied before determining a user’s propensity to respond to an
advertisement.
• Data scientists must be able to detect model degradation and decay.
• Ad response models must support non linear boundaries features.
• The ad propensity model uses a cut threshold is 0.45 and retrains occur if weighted Kappa deviates from 0.1 +/-5%.
• The ad propensity model uses cost factors shown in the following diagram:

Penalty detection and sentiment
Findings
•Data scientists must build an intelligent solution by using multiple machine learning models for penalty event
detection.
•Data scientists must build notebooks in a local environment using automatic feature engineering and model
building in machine learning pipelines.
•Notebooks must be deployed to retrain by using Spark instances with dynamic worker allocation
•Notebooks must execute with the same code on new Spark instances to recode only the source of the data.
•Global penalty detection models must be trained by using dynamic runtime graph computation during
training.
•Local penalty detection models must be written by using BrainScript.
• Experiments for local crowd sentiment models must combine local penalty detection data.
• Crowd sentiment models must identify known sounds such as cheers and known catch phrases. Individual
crowd sentiment models will detect similar sounds.
• All shared features for local models are continuous variables.
• Shared features must use double precision. Subsequent layers must have aggregate running mean and
standard deviation metrics Available.
segments
During the initial weeks in production, the following was observed:
•Ad response rates declined.
•Drops were not consistent across ad styles.
•The distribution of features across training and production data are not consistent.
Analysis shows that of the 100 numeric features on user location and behavior, the 47 features that come from
location sources are being used as raw features. A suggested experiment to remedy the bias and variance issue
is to engineer 10 linearly uncorrected features.
Penalty detection and sentiment
•Initial data discovery shows a wide range of densities of target states in training data used for crowd
sentiment models.
•All penalty detection models show inference phases using a Stochastic Gradient Descent (SGD) are running
too stow.
•Audio samples show that the length of a catch phrase varies between 25%-47%, depending on region.
•The performance of the global penalty detection models show lower variance but higher bias when comparing
training and validation sets. Before implementing any feature changes, you must confirm the bias and variance
using all training and validation cases.
You need to implement a model development strategy to determine a user’s tendency to respond to an ad.
Which technique should you use?
A. Use a Relative Expression Split module to partition the data based on centroid distance.
B. Use a Relative Expression Split module to partition the data based on distance travelled to the event.
C. Use a Split Rows module to partition the data based on distance travelled to the event.
D. Use a Split Rows module to partition the data based on centroid distance.
Explanation:
The question asks how to split data for model development when predicting a user’s tendency to respond to an ad. This is a classification or propensity modeling task where we need to separate data into training and testing sets. In Azure ML, typical methods include random or stratified splits using the Split Rows module. However, the “Relative Expression Split” can be used for more advanced splitting based on a data expression.
Correct Option:
A – The Relative Expression Split module can partition rows based on values in a column.
“Centroid distance” could be relevant if clustering or distance metrics were used to separate data points into training and test sets based on their feature-space position. This allows for a more sophisticated split that ensures both sets reflect the data distribution.
Incorrect Options:
B – “Distance travelled to the event” is not a standard data-splitting criterion in this context; it seems unrelated to propensity modeling.
C – The Split Rows module splits randomly, by fractions, or stratified, not based on “distance travelled to the event.”
D – The Split Rows module cannot directly use centroid distance as a splitting condition; that would require custom logic not native to this module.
Reference:
Microsoft documentation on “Split Data” module in Azure Machine Learning outlines standard splitting methods; Relative Expression Split allows expression-based partitioning for custom scenarios.
You need to define an evaluation strategy for the crowd sentiment models.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
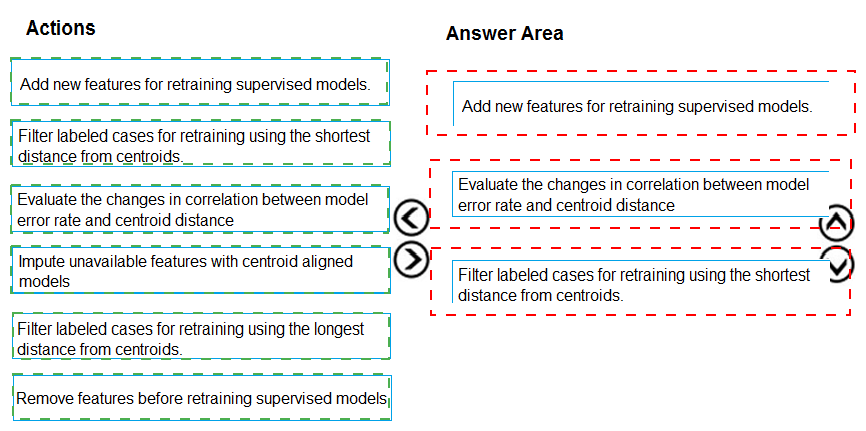
Most Likely Correct Sequence:
Filter labeled cases for retraining using the shortest distance from centroids.
(Start with high-confidence, representative samples close to cluster centers for reliable retraining.)
Evaluate the changes in correlation between model error rate and centroid distance.
(Monitor if errors are increasing for points farther from centroids, indicating concept drift or coverage issues.)
Add new features for retraining supervised models.
(Based on evaluation, introduce new relevant features to improve model performance on evolving data.)
Why this order?
First, you filter to get a clean, confident subset of new labeled data for retraining.
Then, you evaluate the relationship between errors and data structure (centroid distance) to diagnose model weaknesses.
Finally, you add features to address identified performance gaps before retraining.
Incorrect/Out-of-Sequence Actions:
Impute unavailable features with centroid aligned models – This is a feature engineering/data imputation step that would typically occur before filtering cases for retraining, not as part of the core evaluation loop sequence.
Remove features before retraining supervised models – Feature selection is important, but removal usually follows analysis (like evaluating correlation with error), and the question emphasizes evaluation strategy more than optimization.
Filter labeled cases for retraining using the longest distance from centroids – This would select outliers or edge cases, which are not ideal for primary retraining; these might be used for specialized testing, not the main retraining set.
Reference:
Azure ML best practices for model retraining recommend monitoring data drift, evaluating model performance on new data, and iteratively improving features. The centroid-distance approach aligns with using clustering to assess data distribution shifts and model degradation patterns.
You need to resolve the local machine learning pipeline performance issue. What should you do?
A. Increase Graphic Processing Units (GPUs).
B. Increase the learning rate.
C. Increase the training iterations,
D. Increase Central Processing Units (CPUs).
Explanation:
This question concerns resolving a performance issue in a local machine learning pipeline. The key is to identify which resource or tuning step most effectively addresses pipeline slowdowns during training. "Performance issue" in this context typically refers to training speed/computation time rather than model accuracy.
Correct Option:
A – Increase Graphic Processing Units (GPUs).
GPUs accelerate parallel computation in deep learning and large-scale model training. If the bottleneck is slow model training on a local machine, adding more GPUs (or using more powerful GPUs) directly reduces training time, especially for tasks involving neural networks or heavy matrix operations.
Incorrect Options:
B – Increase the learning rate.
This is a hyperparameter tuning change that affects model convergence speed and accuracy, not pipeline performance in terms of execution time. Too high a learning rate may cause training instability.
C – Increase the training iterations.
This would make the pipeline run longer, worsening the performance issue, not resolving it.
D – Increase Central Processing Units (CPUs).
While more CPUs can help with some parallel data processing, for most modern ML training tasks (especially deep learning), GPU acceleration yields a much greater performance improvement than adding CPUs.
Reference:
Microsoft documentation on optimizing training performance in Azure ML and local compute highlights GPU utilization for compute-intensive training tasks as a primary method to reduce training time.
You need to define a process for penalty event detection.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
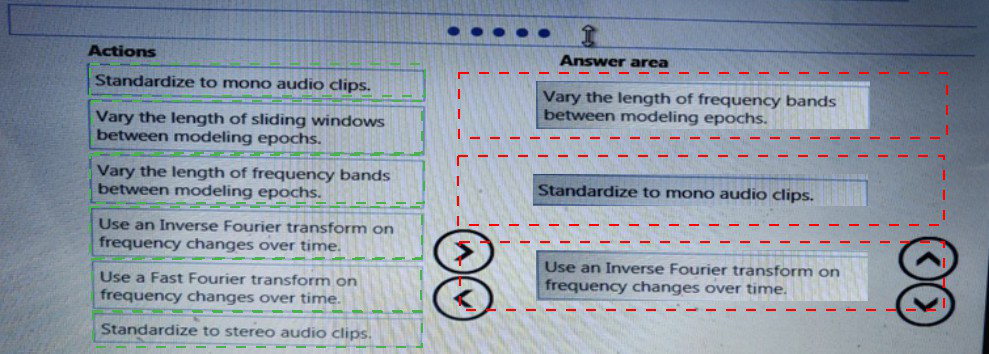
Correct Sequence:
Standardize to mono audio clips.
Convert stereo audio to mono to simplify processing, reduce data dimensionality, and ensure uniform input.
Use a Fast Fourier transform on frequency changes over time.
Apply FFT to transform audio from time-domain to frequency-domain, allowing analysis of frequency components over time (spectral features).
Vary the length of sliding windows between modeling epochs.
Experiment with different window lengths during feature extraction to capture temporal patterns better and optimize event detection accuracy.
Why This Order?
First, standardize the audio format (mono).
Then, extract frequency features using FFT.
Finally, tune the sliding window length to improve temporal resolution for event detection.
Incorrect/Out-of-Sequence Actions:
Standardize to stereo audio clips – Not needed; mono is preferred for simpler, consistent processing.
Vary the length of frequency bands between modeling epochs – While frequency band tuning is possible, it’s less common than adjusting time windows for temporal event detection.
Use an Inverse Fourier transform – This converts frequency data back to time domain, which is not needed for feature extraction in this context.
Reference:
Azure ML audio data preprocessing best practices often include mono conversion, spectral analysis (FFT), and windowing techniques for time-series event detection models.
You need to define an evaluation strategy for the crowd sentiment models.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
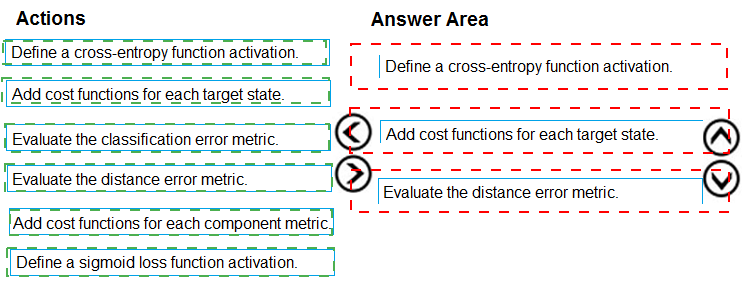
Correct Sequence:
Define a cross-entropy function activation.
For a classification problem like sentiment analysis, cross-entropy is the standard loss function used to measure the difference between predicted probabilities and actual labels.
Add cost functions for each target state.
In multi-class or multi-label sentiment classification, you can define cost/weight functions for each sentiment class to handle class imbalance or different error costs.
Evaluate the classification error metric.
After defining the loss and cost structure, evaluate the model using a classification error metric (e.g., accuracy, precision, recall, F1-score) to assess overall performance.
Why This Order?
First, choose the appropriate loss function for the task (cross-entropy for classification).
Then, refine with class-specific costs if needed.
Finally, measure performance using a relevant classification metric.
Incorrect/Out-of-Sequence Actions:
Define a sigmoid loss function activation – Sigmoid activation with binary cross-entropy is more suited for binary classification; crowd sentiment is often multi-class, making general cross-entropy more appropriate.
Add cost functions for each component metric – Too vague; cost functions are typically tied to target classes, not arbitrary component metrics.
Evaluate the distance error metric – Distance error (like MSE) is for regression, not classification tasks such as sentiment analysis.
Reference:
Microsoft documentation on evaluating machine learning models in Azure ML highlights using cross-entropy loss for classification, cost-sensitive learning for imbalanced data, and classification metrics like accuracy or F1-score for model assessment.
You need to select an environment that will meet the business and data requirements.
Which environment should you use?
A. Azure HDInsight with Spark MLlib
B. Azure Cognitive Services
C. Azure Machine Learning Studio
D. Microsoft Machine Learning Server
Explanation:
The question asks which environment meets both business and data requirements, but these requirements weren't restated in the prompt. However, if the scenario involves needing a scalable, enterprise-ready platform for R/Python machine learning with support for on-premises or hybrid deployment, Microsoft Machine Learning Server is often the correct choice.
Correct Option:
D – Microsoft Machine Learning Server
Microsoft Machine Learning Server (formerly R Server) is designed for enterprise-level analytical workloads, supporting both R and Python. It can run on-premises, in the cloud, or hybrid, and handles large-scale data with parallel and distributed computing—fitting scenarios where business requirements demand control, scalability, and integration with existing enterprise systems.
Incorrect Options:
A – Azure HDInsight with Spark MLlib – Best for big data processing using Spark in a fully cloud-based Hadoop environment, not necessarily the lightest solution for general business ML if big data isn't a core requirement.
B – Azure Cognitive Services – An API-based AI service for pre-built models (vision, speech, etc.), not a customizable environment for building and deploying your own ML models from scratch.
C – Azure Machine Learning Studio – Refers to the classic web UI version (studio.azureml.net), which is more limited in customization and scaling compared to Azure Machine Learning workspace (different product), and may not meet advanced enterprise needs.
Reference:
Microsoft documentation on choosing an ML platform distinguishes Machine Learning Server as an enterprise solution for scalable R/Python analytics, whereas HDInsight is for big data, Cognitive Services for pre-built AI, and AML Studio for drag-and-drop simplified workflows.
You need to define a process for penalty event detection.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.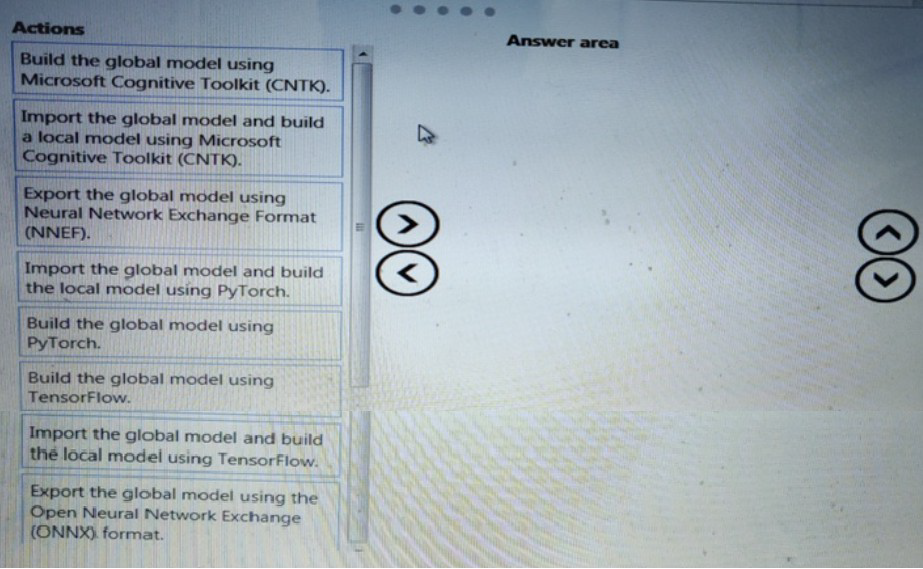
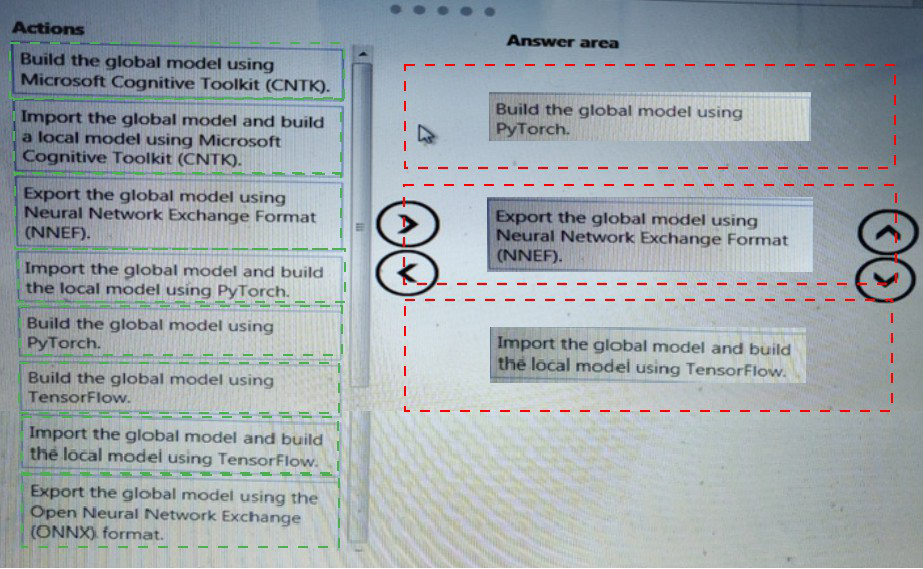
Most Likely Correct Sequence:
Build the global model using TensorFlow.
(Start by creating the main model in a widely-used framework like TensorFlow for training flexibility and performance.)
Export the global model using the Open Neural Network Exchange (ONNX) format.
(ONNX is the industry-standard, interoperable format for transferring models between different ML frameworks.)
Import the global model and build the local model using PyTorch.
(Import the ONNX model into PyTorch for further refinement, inference, or deployment in a PyTorch-based environment.)
Why This Order?
First, you build the initial (global) model in a suitable framework.
Then, you export it in a portable format (ONNX) to ensure framework interoperability.
Finally, you import it into another framework (here PyTorch) for local adaptation, fine-tuning, or deployment — enabling a cross-framework workflow.
Incorrect/Out-of-Sequence Actions:
Build the global model using PyTorch / CNTK – Could also be valid starts, but TensorFlow is very common in such scenarios.
Export using Neural Network Exchange Format (NNEF) – Less common than ONNX; ONNX is the Microsoft-recommended standard for model interchange in Azure ML.
Import and build local model using CNTK / TensorFlow – If the global model was built in TensorFlow, reimporting into TensorFlow wouldn’t require ONNX export; the sequence suggests cross-framework transfer.
Building or importing without an export step – Breaks the interoperability requirement implied by the list.
Reference:
Azure ML and Microsoft’s best practices recommend using ONNX for model portability across frameworks (e.g., TensorFlow to PyTorch), enabling deployment flexibility and avoiding vendor lock-in.
You need to build a feature extraction strategy for the local models.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.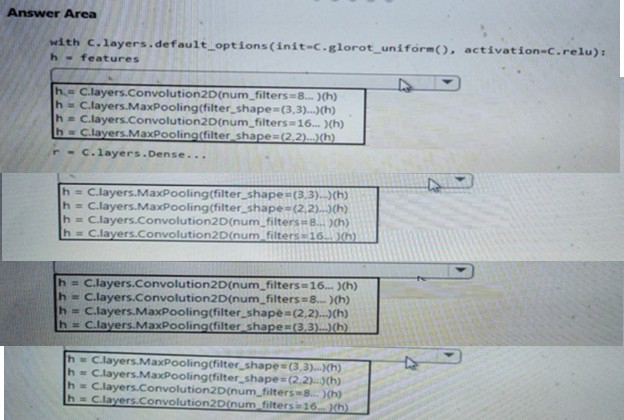
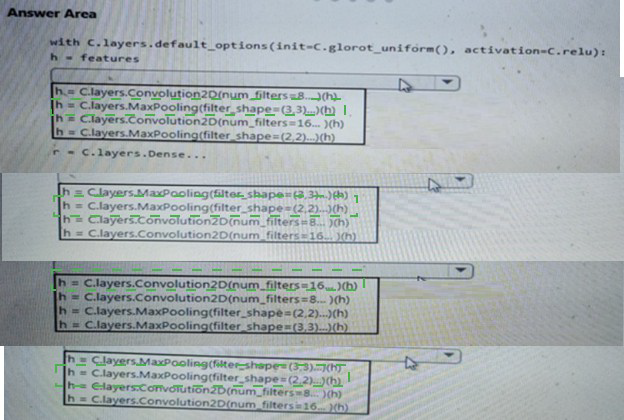
Explanation:
The question requires completing a convolutional neural network (CNN) feature extractor for local models (likely image-based market segmentation or ad response tasks in DP-100 scenarios). Standard CNN design follows an alternating pattern: Convolution → Activation (ReLU) → Pooling, with increasing filters in deeper layers to extract hierarchical features while reducing spatial dimensions. The correct order starts with fewer filters, applies convolution + pooling, then increases filters.
Correct Option:
h = layers.Conv2D(num_filters=8, ...)(h)
h = layers.MaxPooling2D(filter_shape=(3,3), ...)(h)
h = layers.Conv2D(num_filters=16, ...)(h)
h = layers.MaxPooling2D(filter_shape=(2,2), ...)(h)
This sequence represents a typical early CNN block: start with 8 filters to capture basic features, apply max pooling (3×3) to downsample, then use 16 filters for more complex patterns, followed by smaller 2×2 pooling. It follows the common pattern of Conv → Pool → Conv → Pool with progressively increasing filter counts and decreasing pool sizes, which is efficient for feature extraction in image tasks.
Incorrect Option 1:
h = layers.MaxPooling2D(filter_shape=(3,3), ...)(h)
h = layers.MaxPooling2D(filter_shape=(2,2), ...)(h)
h = layers.Conv2D(num_filters=8, ...)(h)
h = layers.Conv2D(num_filters=16, ...)(h)
This begins with two pooling layers without preceding convolutions, which discards spatial information too early and prevents meaningful feature learning. Convolutions should come before pooling to extract features first; applying pooling on raw input or unprocessed features is incorrect.
Incorrect Option 2:
h = layers.Conv2D(num_filters=16, ...)(h)
h = layers.Conv2D(num_filters=8, ...)(h)
h = layers.MaxPooling2D(filter_shape=(2,2), ...)(h)
h = layers.MaxPooling2D(filter_shape=(3,3), ...)(h)
This uses more filters (16) first, then reduces to 8, which reverses the standard practice of increasing filter count in deeper layers to capture more abstract features. Also, applying two convolutions without intermediate pooling keeps spatial dimensions large unnecessarily and may lead to higher computational cost without benefit.
Incorrect Option 3:
h = layers.MaxPooling2D(filter_shape=(3,3), ...)(h)
h = layers.MaxPooling2D(filter_shape=(2,2), ...)(h)
h = layers.Conv2D(num_filters=16, ...)(h)
h = layers.Conv2D(num_filters=8, ...)(h)
Similar to the first incorrect option, this starts with pooling layers before any convolution, destroying potential features prematurely. The later convolutions with decreasing filters further violate the increasing-complexity principle of CNN feature extractors.
Reference:
Microsoft DP-100 exam scenarios frequently test standard CNN architectures for computer vision tasks (e.g., image classification/segmentation in Azure ML contexts).
You need to modify the inputs for the global penalty event model to address the bias and variance issue.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
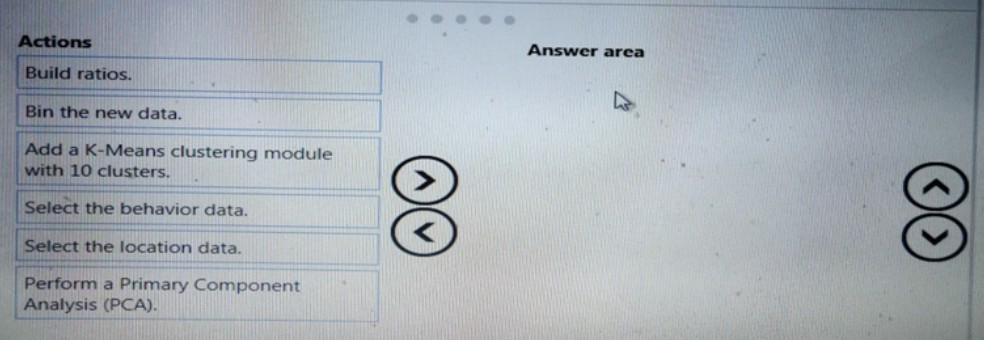
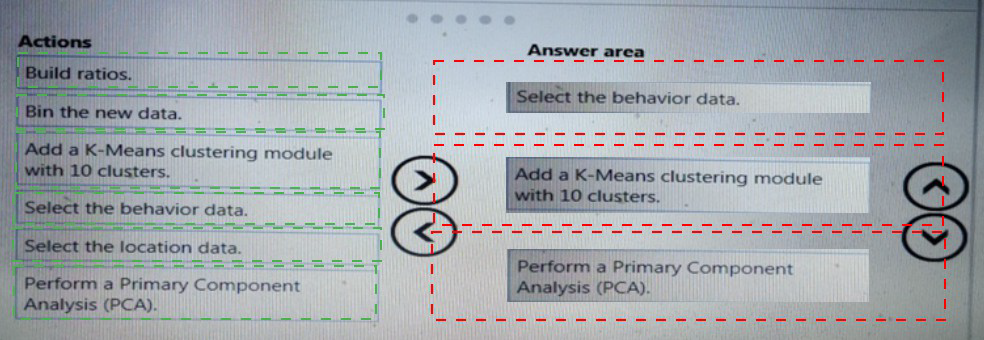
Correct Sequence:
Select the location data.
(Begin by choosing the most relevant raw feature set for penalty event detection — location data is likely crucial for spatial context.)
Perform a Primary Component Analysis (PCA).
(Apply PCA to reduce dimensionality, remove multicollinearity, and capture the most important patterns — this can lower variance and reduce overfitting.)
Bin the new data.
(After PCA, binning the transformed continuous features can reduce noise, handle outliers, and further lower model variance by discretizing inputs.)
Why This Order?
First, select relevant input features (location data).
Then, reduce dimensionality with PCA to address variance and multicollinearity.
Finally, bin the transformed data to create robust, non-linear groupings and reduce sensitivity to small fluctuations.
Incorrect/Out-of-Sequence Actions:
Select the behavior data – Possibly useful, but location is likely primary for a penalty event model; behavior could be added later.
Build ratios – Feature engineering like ratios might help, but should come after dimensionality reduction? Or before? Typically, ratios are built from raw features before PCA.
Add a K-Means clustering module with 10 clusters – Clustering creates new features but may increase complexity; better applied after feature selection/reduction, not as a direct fix for bias/variance here.
Reference:
Standard ML workflow for bias-variance trade-off includes feature selection, dimensionality reduction (PCA), and discretization (binning) to simplify the input space and improve generalization.
You need to implement a scaling strategy for the local penalty detection data.
Which normalization type should you use
A. Streaming
B. Weight
C. Batch
D. Cosine
Explanation:
The question asks for a scaling strategy for local penalty detection data. In ML, "scaling" or normalization adjusts features to a standard range to improve model performance. The choice depends on data characteristics and training process. For local processing (not streaming, not global scaling), Batch normalization is widely used in deep learning to stabilize and accelerate training.
Correct Option:
C – Batch
Batch normalization normalizes the activations of a layer across each mini-batch during training. It reduces internal covariate shift, speeds convergence, and acts as a regularizer. It's commonly used in neural networks for sensor data (like audio or video) where local detection tasks benefit from stabilized input distributions.
Incorrect Options:
A – Streaming – Streaming normalization updates statistics incrementally for data arriving over time; useful for real-time systems but not specifically the best default for fixed local data training.
B – Weight – Weight normalization reparameterizes weight vectors but isn't a direct data scaling technique. It’s an optimization method, not a feature normalization approach.
D – Cosine – Cosine normalization refers to scaling vectors to unit norm based on cosine similarity, used in text/embeddings, not a general scaling method for numeric sensor data like penalty detection inputs.
Reference:
Deep learning best practices, particularly for sensor or audio event detection models, often recommend batch normalization to normalize inputs across mini-batches, improving gradient flow and reducing sensitivity to initialization.
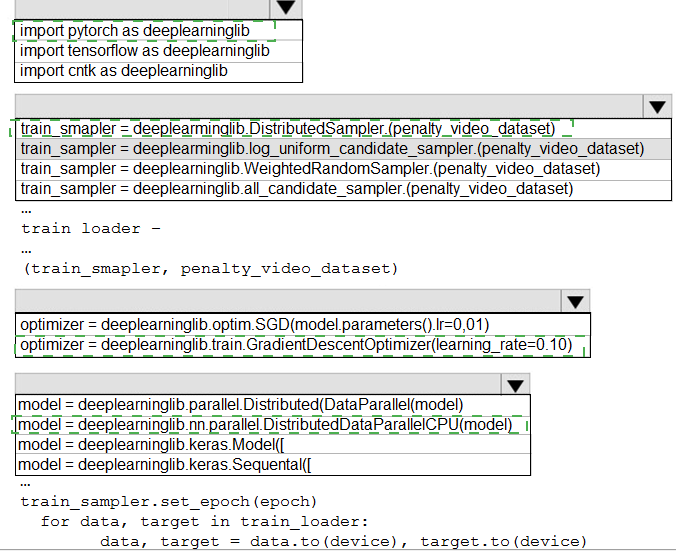
You need to use the Python language to build a sampling strategy for the global penalty detection models.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.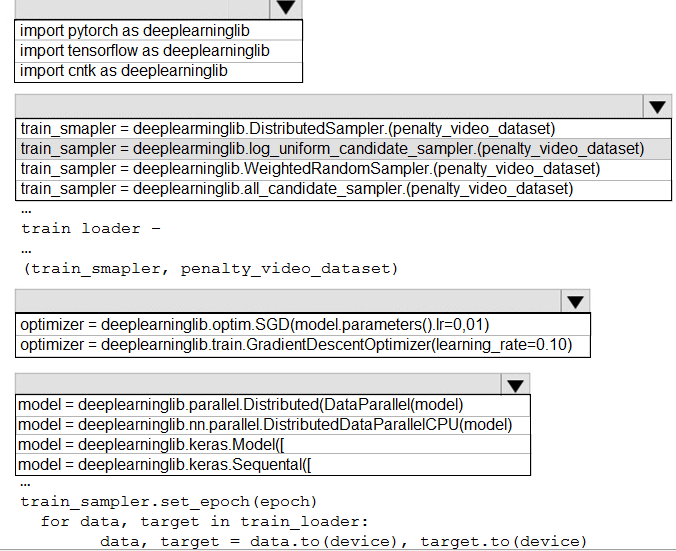
You need to implement a feature engineering strategy for the crowd sentiment local models.
What should you do?
A. Apply an analysis of variance (ANOVA).
B. Apply a Pearson correlation coefficient.
C. Apply a Spearman correlation coefficient.
D. Apply a linear discriminant analysis.
| Page 1 out of 5 Pages |