Topic 3: Misc. Questions
You develop a custom question answering project in Azure Cognitive Service for Language. The project will be used by a chatbot. You need to configure the project to engage in multi-turn conversations. What should you do?
A. Add follow-up prompts
B. Enable active learning.
C. Add alternate questions
D. Enable chit-chat
Explanation:
Multi-turn conversation in a custom question answering knowledge base is specifically achieved by defining a hierarchical relationship between question/answer pairs. This allows the bot to ask clarifying questions or guide the user through a process, creating a conversational flow.
Correct Option:
A. Add follow-up prompts:
This is the explicit feature for enabling multi-turn conversations. Follow-up prompts allow you to connect a source QnA pair to one or more related destination QnA pairs. When the source answer is returned, the system presents the linked prompts as clickable options to continue the conversation in a guided, logical path.
Incorrect Option:
B. Enable active learning:
This feature helps improve the knowledge base over time by suggesting real user questions as alternate phrasings for existing answers. It is for refining and expanding QnA pairs, not for structuring conversational turns.
C. Add alternate questions:
This improves the matching accuracy for a single answer by adding different ways a user might ask the same core question. It enhances a single turn, but does not create a linked, multi-step dialogue.
D. Enable chit-chat:
This adds a layer of pre-built, casual conversational QnA pairs (like greetings, jokes, or "How are you?"). It makes the bot more personable but does not create a logical, task-oriented multi-turn flow for custom domain knowledge.
Reference:
Microsoft Learn: "Create multiple turns of a conversation"
You plan to build a chatbot to support task tracking.
You create a Language Understanding service named lu1.
You need to build a Language Understanding model to integrate into the chatbot. The solution must minimize development time to build the model.
Which four actions should you perform in sequence? To answer, move the appropriate
actions from the list of actions to the answer area and arrange them in the correct order.
(Choose four.)
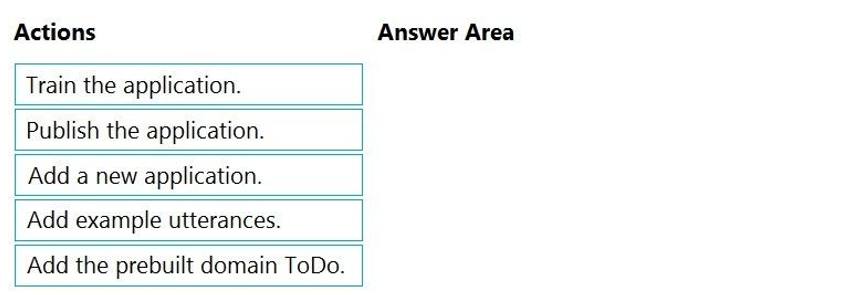

Explanation:
This scenario describes building a Language Understanding (LUIS) model to minimize development time. The most efficient approach is to start with a prebuilt domain model that already contains intents and entities for common scenarios, like task management, and then customize it with your own examples.
Correct Option (Sequence):
Add a new application.
The first logical step is to create a new LUIS application within the lu1 service to serve as the container for your custom model.
Add the prebuilt domain ToDo.
To minimize development time, you import the prebuilt ToDo domain. This domain comes with pre-trained intents (like "AddToDo", "DeleteToDo", "MarkToDoComplete") and relevant entities, providing an immediate, robust foundation for a task-tracking bot.
Add example utterances.
After importing the prebuilt domain, you add your own example utterances. This step is crucial to tailor the pre-trained model to your specific users' phrasing and to improve prediction accuracy for your application.
Train the application.
Once you have added your custom utterances, you must train the application. This process updates the underlying machine learning model with the new data (the prebuilt domain + your examples).
Incorrect Option / Not in Sequence:
Publish the application:
This is the final step to deploy the trained model to a prediction endpoint so the chatbot can call it. However, it is performed after the four steps listed above. The question asks for the sequence to build the model, not the final deployment action.
Reference:
Microsoft Learn: "Prebuilt domains in LUIS"
You are designing a conversation flow to be used in a chatbot.
You need to test the conversation flow by using the Microsoft Bot Framework Emulator.
How should you complete the .chat file? To answer, select the appropriate options in the
answer area.
NOTE: Each correct selection is worth one point.
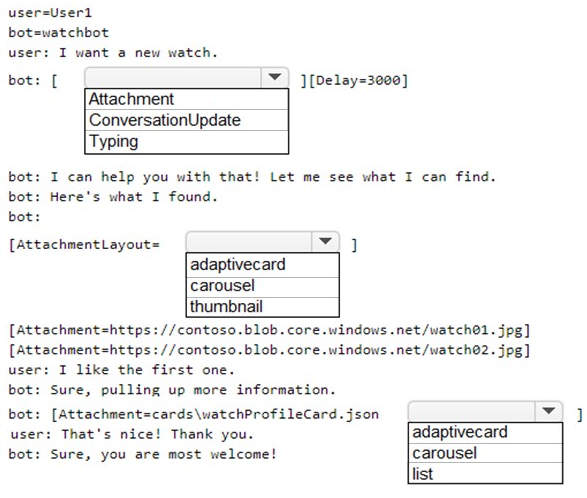
Explanation:
A .chat file is used in the Bot Framework Emulator to script and simulate a conversation for testing. It uses specific activities and formatting directives. The correct choices depend on simulating realistic bot behavior (like showing a typing indicator before a response) and specifying how multiple attachments should be displayed.
Correct Option:
First Dropdown (After user says "I want a new watch."):
Typing
Explanation:
When the bot needs time to process or "think," it should send a Typing activity to the user. This is a standard UX pattern in chatbots to indicate the bot is working on a response. The subsequent 3-second delay (Delay=3000) mimics this processing time before the actual message is delivered.
Second Dropdown (When displaying multiple watch images):
carousel
Explanation:
The AttachmentLayout property controls how multiple attachments are presented. A carousel layout displays attachments as a horizontally scrollable set of cards, which is ideal for visually rich items like product images (watch01.jpg, watch02.jpg). A list layout is better for simple, vertical text-based lists.
Third Dropdown (When displaying a single JSON card file):
adaptivecard
Explanation:
The file watchProfileCard.json is an Adaptive Card, a rich, structured JSON document. The Attachment directive should specify adaptivecard as the content type to instruct the emulator/channel to render the JSON as a rich interactive card, not as a simple file attachment or image.
Incorrect Option / Rationale:
First Dropdown - ConversationUpdate:
This activity is sent when a member joins or leaves a conversation. It is used for system notifications, not for indicating the bot is processing a user's message.
Second Dropdown - list / thumbnail:
list is incorrect for displaying side-by-side product images. thumbnail is not a valid value for the AttachmentLayout property in this context (valid options are list or carousel).
Third Dropdown - carousel:
This is for the layout of multiple attachments. Since only a single card file (watchProfileCard.json) is being sent here, specifying a layout is not applicable. The content type of the single attachment itself must be declared.
Reference:
Bot Framework SDK Documentation: "How to test with the Emulator" and "Add media attachments to messages".
Match the Azure services to the appropriate locations in the architecture.
To answer, drag the appropriate service from the column on the left to its location on the
right. Each service may be used once, more than once, or not at all.
NOTE: Each correct match is worth one point.

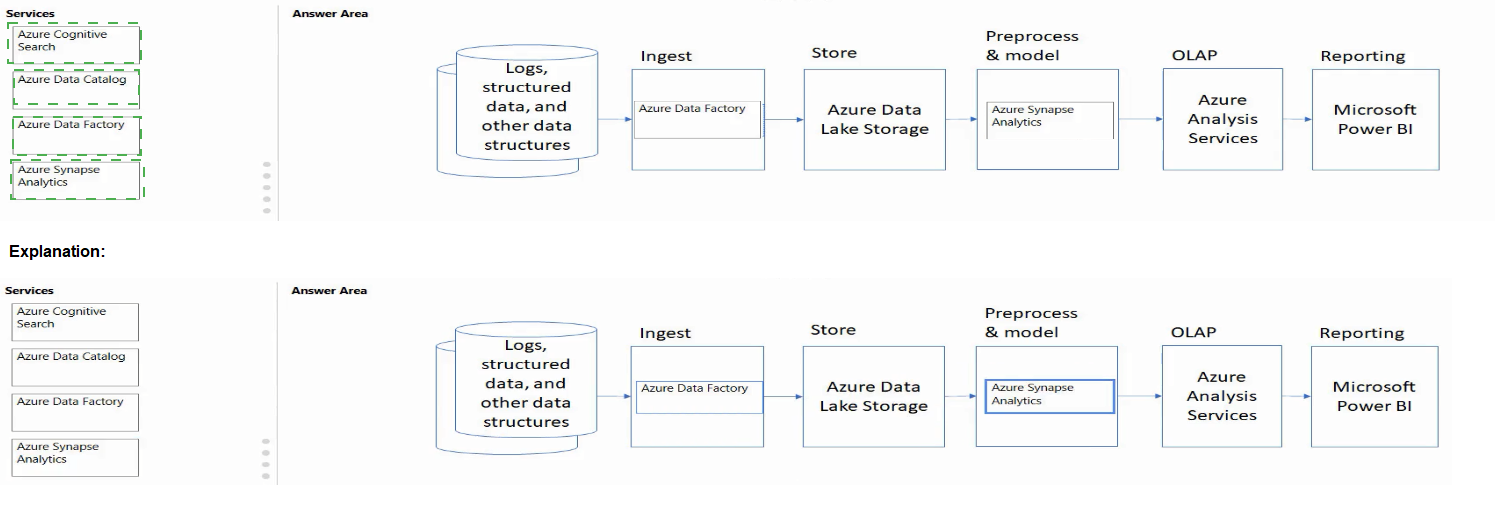
Explanation:
This diagram depicts a classic data pipeline architecture: Ingest -> Store -> Prepare and Serve (OLAP) -> Consume (Reporting). The task is to match Azure services to their typical role in this pipeline. The "Preprocess" stage is part of the "Prepare and Serve" phase, often handled by data orchestration or transformation services.
Correct Option:
Azure Data Factory -> Ingest:
Azure Data Factory is a cloud-based data integration service. It is primarily used to create, schedule, and orchestrate data pipelines that move and transform data from various source systems—making it the ideal tool for the Ingest stage.
Azure Synapse Analytics -> OLAP:
Azure Synapse Analytics is an integrated analytics service that provides both serverless and dedicated SQL pools for large-scale data warehousing and analytics. It is specifically designed for Online Analytical Processing (OLAP) workloads, involving complex queries over large datasets.
Azure Data Lake Storage -> Store:
Azure Data Lake Storage Gen2 is a massively scalable and secure data lake for high-performance analytics workloads. It is the foundational storage service designed to hold vast amounts of raw data in its native format during the Store stage of a data lakehouse architecture.
Azure Data Catalog -> Reporting (or possibly the "Preprocess" stage in some contexts, but Reporting fits the available target better):
Azure Data Catalog (now part of Azure Purview) is an enterprise-wide metadata catalog. It enables data discovery and governance, which is a critical supporting service for the Reporting and consumption phase, as it helps analysts find and understand the available data assets.
Incorrect Option / Not Used:
Azure Search:
This service is a dedicated AI-powered search engine. While it can be part of a data solution (e.g., powering search over cataloged assets or reports), it does not directly map to the core, high-level stages shown in this specific data pipeline diagram (Ingest, Store, OLAP, Reporting). It would likely remain unused in this matching exercise.
Reference:
"What is Azure Data Factory?"
What is used to define a query in a stream processing jobs in Azure Stream Analytics?
A. SQL
B. XML
C. YAML
D. KOL
Explanation:
Azure Stream Analytics (ASA) is a real-time analytics and complex event-processing engine. To define the logic for transforming, aggregating, and analyzing streaming data, you need a declarative query language. ASA provides a dialect of SQL that is extended to handle temporal and streaming concepts like windows.
Correct Option:
A. SQL:
Azure Stream Analytics uses a SQL-like query language. This language is based on ANSI SQL but includes specific extensions for temporal operations (e.g., TIMESTAMP BY, tumbling windows, hopping windows) that are essential for processing infinite, time-series data streams. The job's transformation logic is authored in this Stream Analytics SQL.
Incorrect Option:
B. XML:
While XML may be used for configuration files (like the job's input/output definitions in an ARM template), it is not the language used to write the core data transformation and processing query logic within the job itself.
C. YAML:
YAML is sometimes used for CI/CD pipeline definitions or deployment manifests in Azure, but it is not the query language for defining the real-time data processing logic in a Stream Analytics job.
D. KQL (Kusto Query Language):
KQL is the powerful query language used by Azure Data Explorer and Azure Monitor Logs. While both handle time-series data, KQL is not used in Azure Stream Analytics jobs. This is a common point of confusion. Stream Analytics uses its own SQL variant.
Reference:
"Stream Analytics Query Language Reference"
You have a Language Understanding resource named lu1.
You build and deploy an Azure bot named bot1 that uses lu1.
You need to ensure that bot1 adheres to the Microsoft responsible AI principle of
inclusiveness.
How should you extend bot1?
A. Implement authentication for bot1
B. Enable active learning for Iu1
C. Host Iu1 in a container
D. Add Direct Line Speech to bot1.
Explanation:
The principle of inclusiveness in responsible AI means designing systems that are accessible to and work well for people with a wide range of abilities, backgrounds, and characteristics. For a chatbot, this includes ensuring it can be used by people with disabilities, such as those with visual impairments or motor difficulties that prevent easy typing.
Correct Option:
D. Add Direct Line Speech to bot1:
This directly addresses inclusiveness. Direct Line Speech is a feature that adds high-quality, two-way speech capability to a bot, allowing users to interact with it through voice commands and hear spoken responses. This makes the bot accessible to users who cannot read screens or type effectively.
Incorrect Option:
A. Implement authentication for bot1:
This relates to security and privacy (accountability or reliability principles), not directly to making the bot usable by a diverse audience with varying abilities.
B. Enable active learning for lu1:
This improves the performance and accuracy of the Language Understanding model over time by learning from user interactions. It relates to the principles of reliability and performance, but does not inherently make the bot more accessible or inclusive in its mode of interaction.
C. Host lu1 in a container:
Containerization is primarily about deployment flexibility, portability, and data residency/compliance (privacy principle). It does not change the bot's user interface or interaction model to be more inclusive.
Reference:
"Principles of responsible AI"
You are reviewing the design of a chatbot. The chatbot includes a language generation file
that contains the following fragment.
# Greet(user)
- ${Greeting()}, ${user.name}
For each of the following statements, select Yes if the statement is true. Otherwise, select
No.
NOTE: Each correct selection is worth one point.


You are developing an application to recognize employees’ faces by using the Face
Recognition API. Images of the faces will be accessible from a URI endpoint.
The application has the following code.


Explanation:
A. True
B. True
C. True
B: see this example code from documentation that uses PersonGroup of size 10,000 :
https://docs.microsoft.com/en-us/azure/cognitive-services/face/face-api-how-to-topics/howto-
add-faces
the question wants to trick you into thinking you need to use a LargePersonGroup for a size
of 10,000 - but the documentation for it doesn't include this limitation or criteria:
https://docs.microsoft.com/en-us/azure/cognitive-services/face/face-api-how-to-topics/howto-
use-large-scale
You have the following data sources:
Finance: On-premises Microsoft SQL Server database
Sales: Azure Cosmos DB using the Core (SQL) API
Logs: Azure Table storage
HR: Azure SQL database
You need to ensure that you can search all the data by using the Azure Cognitive Search
REST API. What should you do?
A.
Configure multiple read replicas for the data in Sales.
B.
Mirror Finance to an Azure SQL database
C.
Migrate the data in Sales to the MongoDB API.
D.
Ingest the data in Logs into Azure Sentinel.
Mirror Finance to an Azure SQL database
Explanation:
On-premises Microsoft SQL Server database cannot be used as an index data source.
Note: Indexer in Azure Cognitive Search: : Automate aspects of an indexing operation by
configuring a data source and an indexer that you can schedule or run on demand. This
feature is supported for a limited number of data source types on Azure.
Indexers crawl data stores on Azure.
Azure Blob Storage
Azure Data Lake Storage Gen2 (in preview)
Azure Table Storage
Azure Cosmos DB
Azure SQL Database
SQL Managed Instance
SQL Server on Azure Virtual Machines
Reference:
https://docs.microsoft.com/en-us/azure/search/search-indexer-overview#supported-datasources
You need to build a chatbot that meets the following requirements:
Supports chit-chat, knowledge base, and multilingual models
Performs sentiment analysis on user messages
Selects the best language model automatically
What should you integrate into the chatbot?
A.
QnA Maker, Language Understanding, and Dispatch
B.
Translator, Speech, and Dispatch
C.
Language Understanding, Text Analytics, and QnA Maker
D.
Text Analytics, Translator, and Dispatch
Language Understanding, Text Analytics, and QnA Maker
Explanation:
Language Understanding: An AI service that allows users to interact with your applications,
bots, and IoT devices by using natural language.
QnA Maker is a cloud-based Natural Language Processing (NLP) service that allows you to
create a natural conversational layer over your data. It is used to find the most appropriate
answer for any input from your custom knowledge base (KB) of information.
Text Analytics: Mine insights in unstructured text using natural language processing
(NLP)—no machine learning expertise required. Gain a deeper understanding of customer
opinions with sentiment analysis. The Language Detection feature of the Azure Text
Analytics REST API evaluates text input
Reference:
https://azure.microsoft.com/en-us/services/cognitive-services/text-analytics/
https://docs.microsoft.com/en-us/azure/cognitive-services/qnamaker/overview/overview
You have a chatbot that was built by using the Microsoft Bot Framework. You need to
debug the chatbot endpoint remotely.
Which two tools should you install on a local computer? Each correct answer presents part
of the solution. (Choose two.)
NOTE: Each correct selection is worth one point.
A.
Fiddler
B.
Bot Framework Composer
C.
Bot Framework Emulator
D.
Bot Framework CLI
E.
ngrok
F.
nginx
Bot Framework Emulator
ngrok
Explanation:
Bot Framework Emulator is a desktop application that allows bot developers to test and
debug bots, either locally or remotely.
ngrok is a cross-platform application that "allows you to expose a web server running on
your local machine to the internet." Essentially, what we'll be doing is using ngrok to
forward messages from external channels on the web directly to our local machine to allow
debugging, as opposed to the standard messaging endpoint configured in the Azure portal.
Reference:
https://docs.microsoft.com/en-us/azure/bot-service/bot-service-debug-emulator
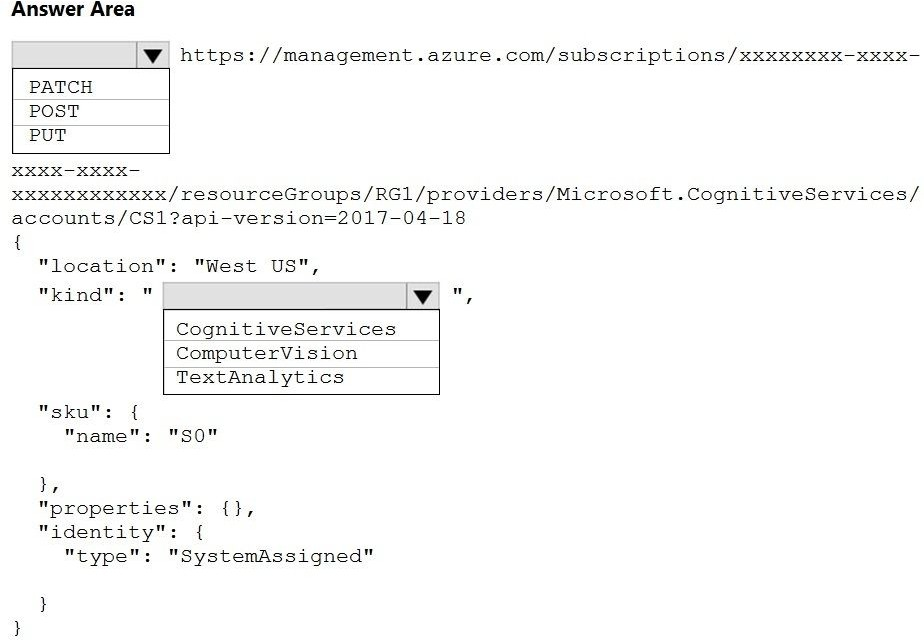
You need to create a new resource that will be used to perform sentiment analysis and
optical character recognition (OCR). The solution must meet the following requirements:
Use a single key and endpoint to access multiple services.
Consolidate billing for future services that you might use.
Support the use of Computer Vision in the future.
How should you complete the HTTP request to create the new resource? To answer, select
the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

| Page 3 out of 22 Pages |
| Previous |